
快速上手
Palo是一款高性能的分布式分析型数据仓库,用于支持大规模数据分析场景。而PaloUI作为Palo的一个重要组成部分,为用户提供了一个便捷的平台,用于执行SQL查询、管理数据仓库集群以及监控和分析查询性能。本文档的目的是为您详尽地介绍如何通过Palo UI(Palo的用户界面)快速体验和使用Palo进行查询操作。
- 公有云用户,请先参阅 创建集群 文档创建一个 Palo 集群。
Palo UI是Palo为大家提供的可以快速执行查询请求和进行一些管理操作的Web UI环境。
提示:本文档中演示使用的demo数据和查询例句均来自于 Star Schema Benchmark,用户可以点击下载获取样例数据和SQL语句。
进入Palo UI
操作步骤:
1.在集群管理列表选择对应集群点击集群名称,进入详情界面
2.找到连接信息,选择Ui地址点击链接进入
登陆Palo UI
操作步骤:
1.进入环境后,在登录页面输入用户名和密码。用户名是“admin”,密码是用户创建集群时填写的密码。
图一 登陆界面

2.输入用户名密码后点击登陆进入Palo ui主界面。点击登录之后,就可以进入到Palo UI的主页面,默认页面就是Palo查询页面(Playground)。
3.Palo快速查询页面主要分成三个区域,左侧为表管理区域,包括系统库表和用户自己创建的表。右上区域是SQL执行区域,右下区域为表预览和数据导入以及执行结果区域。
接下来我们在本页面展示从建库、建表、导入数据、查询等主要步骤,帮助初次使用Palo的用户体验一次完整的使用流程。
建库建表
在编辑器区域,我们输入SQL语句创建一个example_db的库。点击执行之后,在下方可以看到执行结果,执行成功之后,刷新左侧表区域,就可以在表管理区域看到新创建的example_db库了。
1CREATE DATABASE example_db;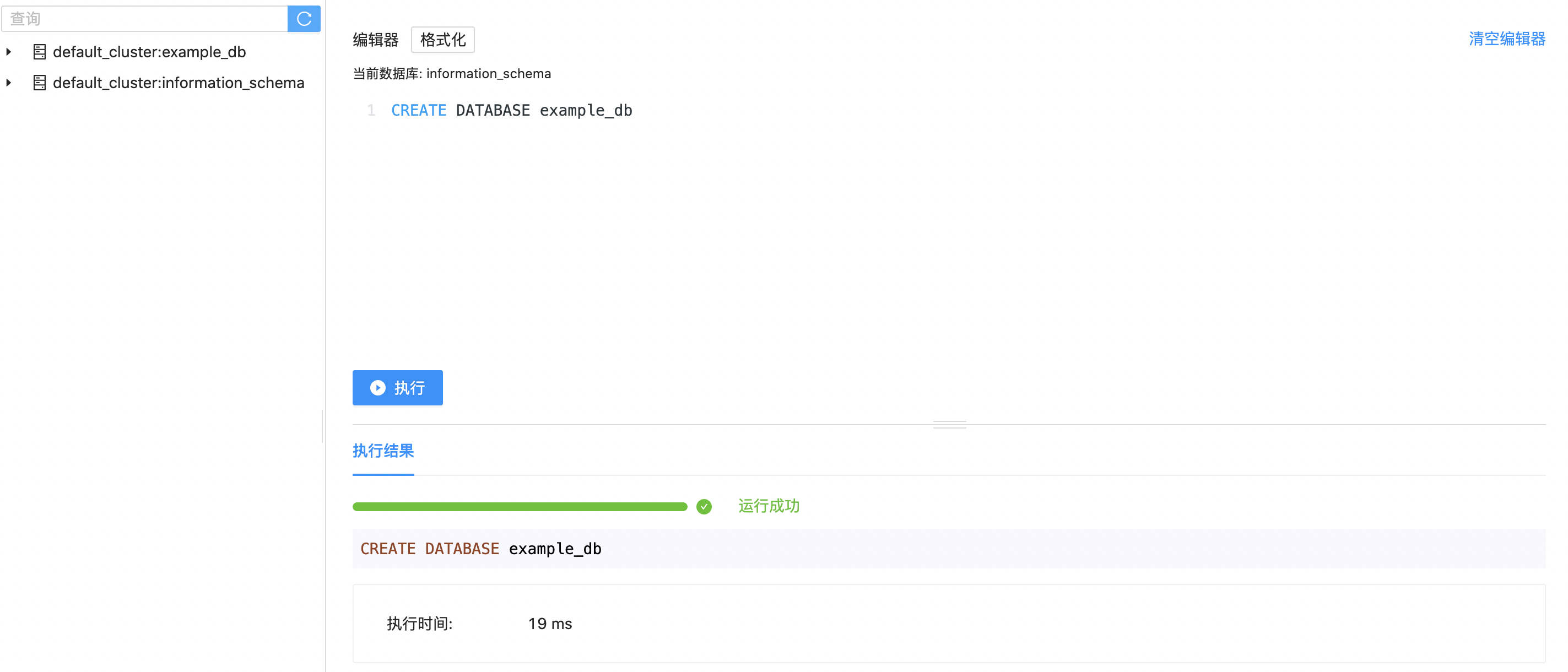
我们的demo数据一共有5份销售相关的订单、日期、客户信息等数据样例,所以我们需要创建5张对应的表。
首先我们在example_db库中创建一个名为lineorder的表。Palo使用DISTRIBUTED关键字设置分桶列,分桶列用于对数据进行水平划分,一般我们选择一个可以帮助数据能够均匀划分的列作为分桶列。此处我们使用lo_orderkey作为分桶列。此处我们还设置了一个副本数为1,因为Palo默认三副本,如果我们集群只购买了一个LeaderNode,则需要手动设置副本数为1。
这个表主要定义了订单号、订单时间以及利润、税收等一些订单主信息。
1CREATE TABLE lineorder (
2 lo_orderkey BIGINT,
3 lo_linenumber BIGINT,
4 lo_custkey INT,
5 lo_partkey INT,
6 lo_suppkey INT,
7 lo_orderdate INT,
8 lo_orderpriotity VARCHAR(16),
9 lo_shippriotity INT,
10 lo_quantity BIGINT,
11 lo_extendedprice BIGINT,
12 lo_ordtotalprice BIGINT,
13 lo_discount BIGINT,
14 lo_revenue BIGINT,
15 lo_supplycost BIGINT,
16 lo_tax BIGINT,
17 lo_commitdate BIGINT,
18 lo_shipmode VARCHAR(11)
19)
20DISTRIBUTED BY HASH(lo_orderkey)
21PROPERTIES ("replication_num"="1");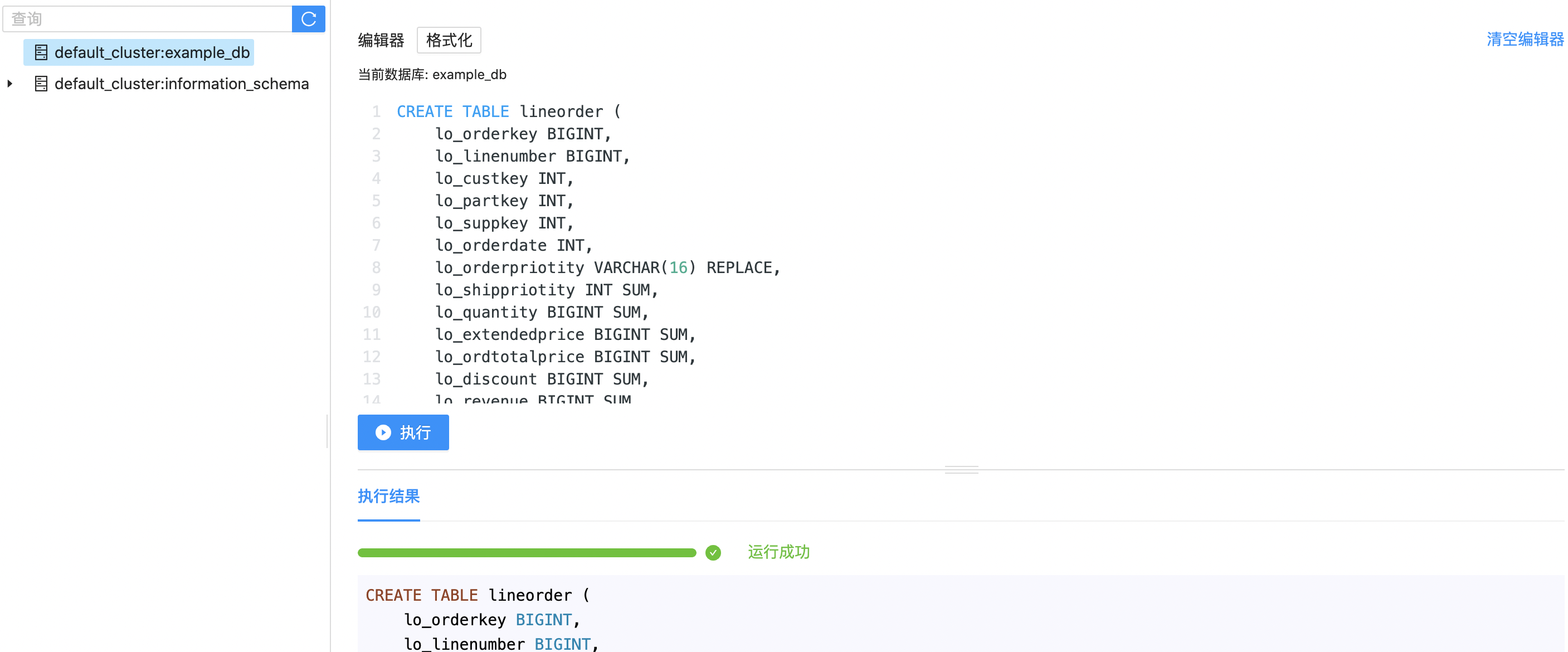
然后我们再创建一个date表。使用d_datekey作为分桶列,并设置副本数为1。这个表定义的是更加详细一些的订单日期信息。
1CREATE TABLE date (
2 d_datekey INT,
3 d_date VARCHAR(20),
4 d_dayofweek VARCHAR(10),
5 d_month VARCHAR(11),
6 d_year INT,
7 d_yearmonthnum INT,
8 d_yearmonth VARCHAR(9),
9 d_daynuminweek INT,
10 d_daynuminmonth INT,
11 d_daynuminyear INT,
12 d_monthnuminyear INT,
13 d_weeknuminyear INT,
14 d_sellingseason VARCHAR(14),
15 d_lastdayinweekfl INT,
16 d_lastdayinmonthfl INT,
17 d_holidayfl INT,
18 d_weekdayfl INT
19) DISTRIBUTED BY hash(d_datekey) PROPERTIES (
20 "storage_type"="column",
21 "replication_num"="1");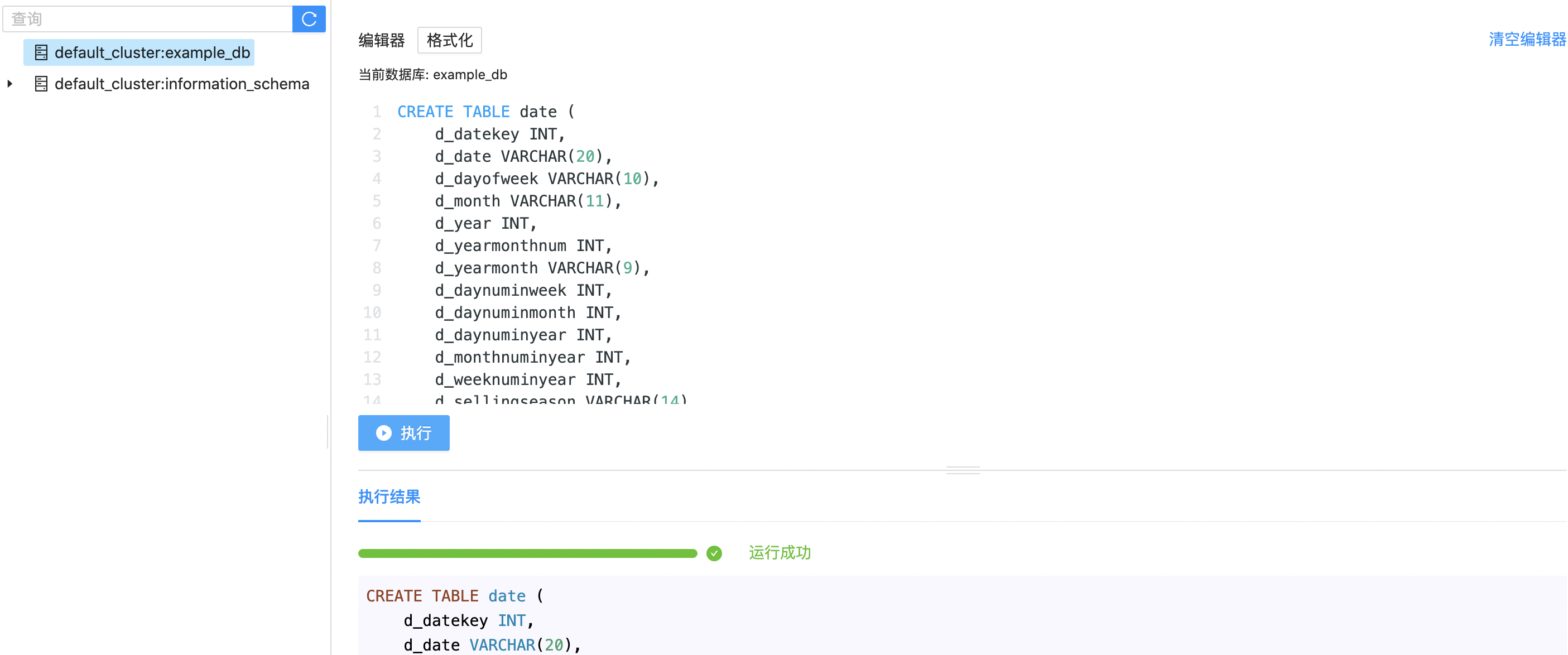
接下来我们再分别创建剩下三张表,customer,part,supplier,分别记录了客户、商品和供应商的详细信息。
1CREATE TABLE customer (
2 c_custkey INT,
3 c_name VARCHAR(26),
4 c_address VARCHAR(41),
5 c_city VARCHAR(11),
6 c_nation VARCHAR(16),
7 c_region VARCHAR(13),
8 c_phone VARCHAR(16),
9 c_mktsegment VARCHAR(11) )
10DISTRIBUTED BY hash(c_custkey)
11PROPERTIES (
12 "storage_type"="column",
13 "replication_num"="1");
14
15CREATE TABLE part (
16 p_partkey INT,
17 p_name VARCHAR(23),
18 p_mfgr VARCHAR(7),
19 p_category VARCHAR(8),
20 p_brand VARCHAR(10),
21 p_color VARCHAR(12),
22 p_type VARCHAR(26),
23 p_size INT,
24 p_container VARCHAR(11) )
25DISTRIBUTED BY hash(p_partkey)
26PROPERTIES (
27 "storage_type"="column",
28 "replication_num"="1");
29
30CREATE TABLE supplier (
31 s_suppkey INT,
32 s_name VARCHAR(26),
33 s_address VARCHAR(26),
34 s_city VARCHAR(11),
35 s_nation VARCHAR(16),
36 s_region VARCHAR(13),
37 s_phone VARCHAR(16) )
38DISTRIBUTED BY hash(s_suppkey)
39PROPERTIES (
40 "storage_type"="column",
41 "replication_num"="1");表建完之后,可以查看 example_db 中表的信息:
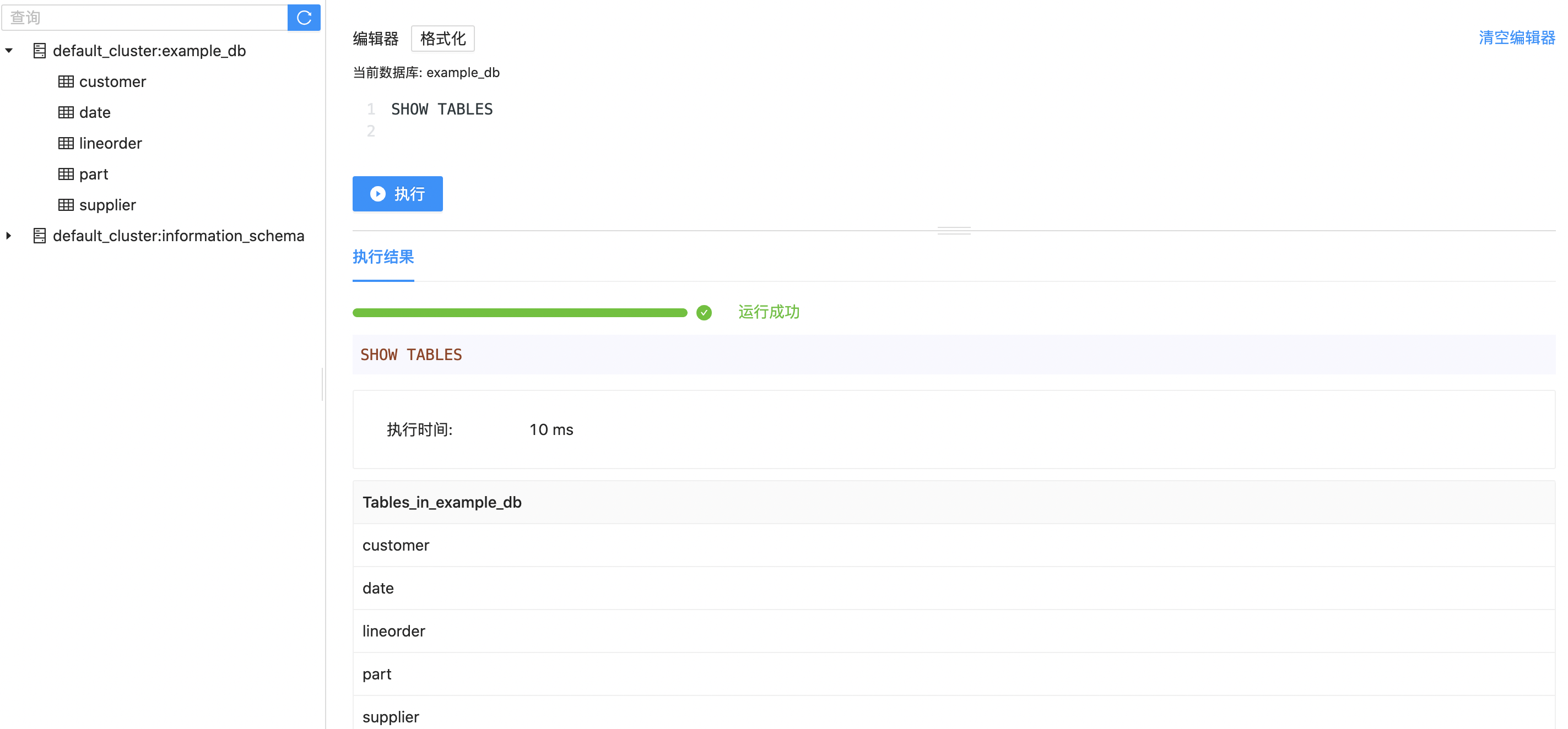
导入数据
Palo 支持多种数据导入方式。具体可以参阅数据导入文档。这里我们使用Web方式便捷导入数据做示例。
1.首先点击选中需要导入数据的表
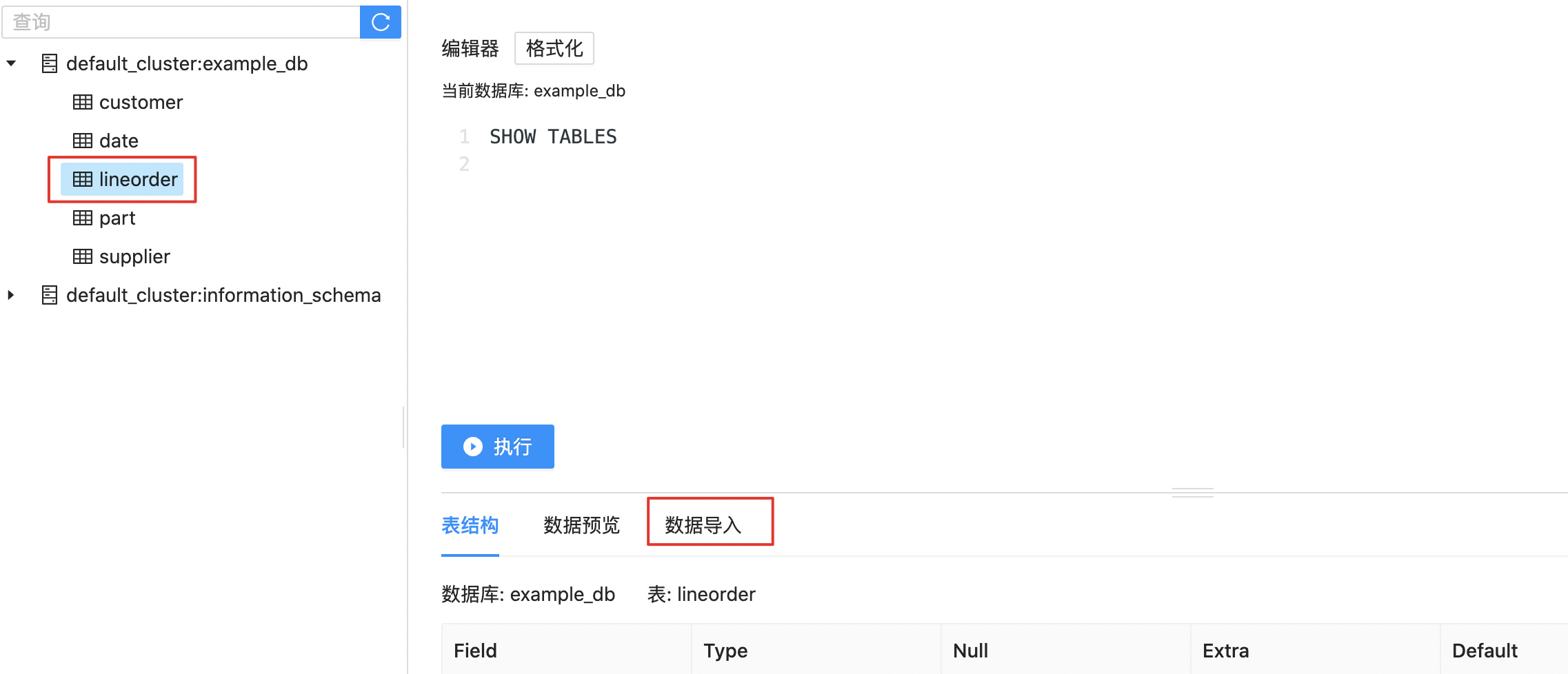
2.然后点击数据导入,进入数据导入页面
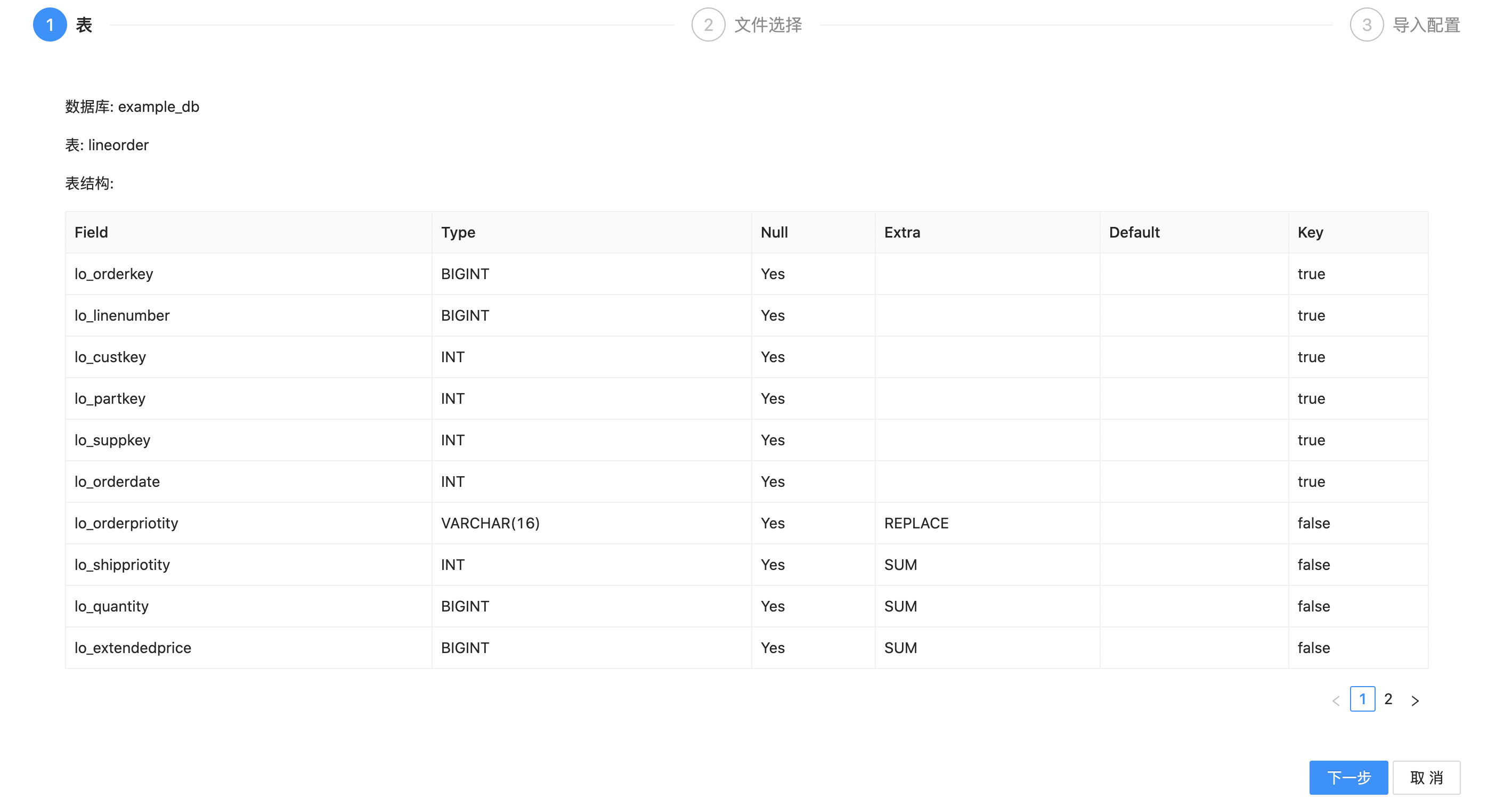
3.点击“下一步”。之后先选择导入文件的列分割符,这里我们是 \t 分割。接着选择需要导入的数据文件
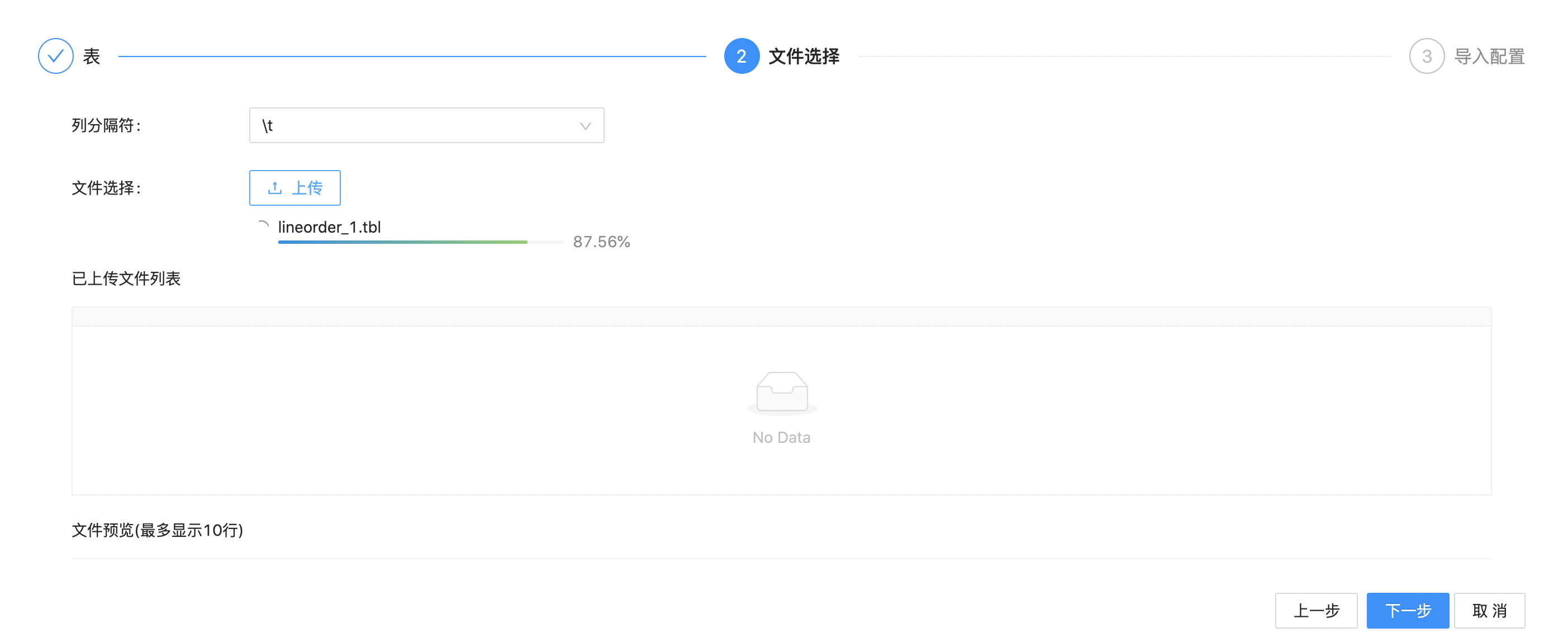
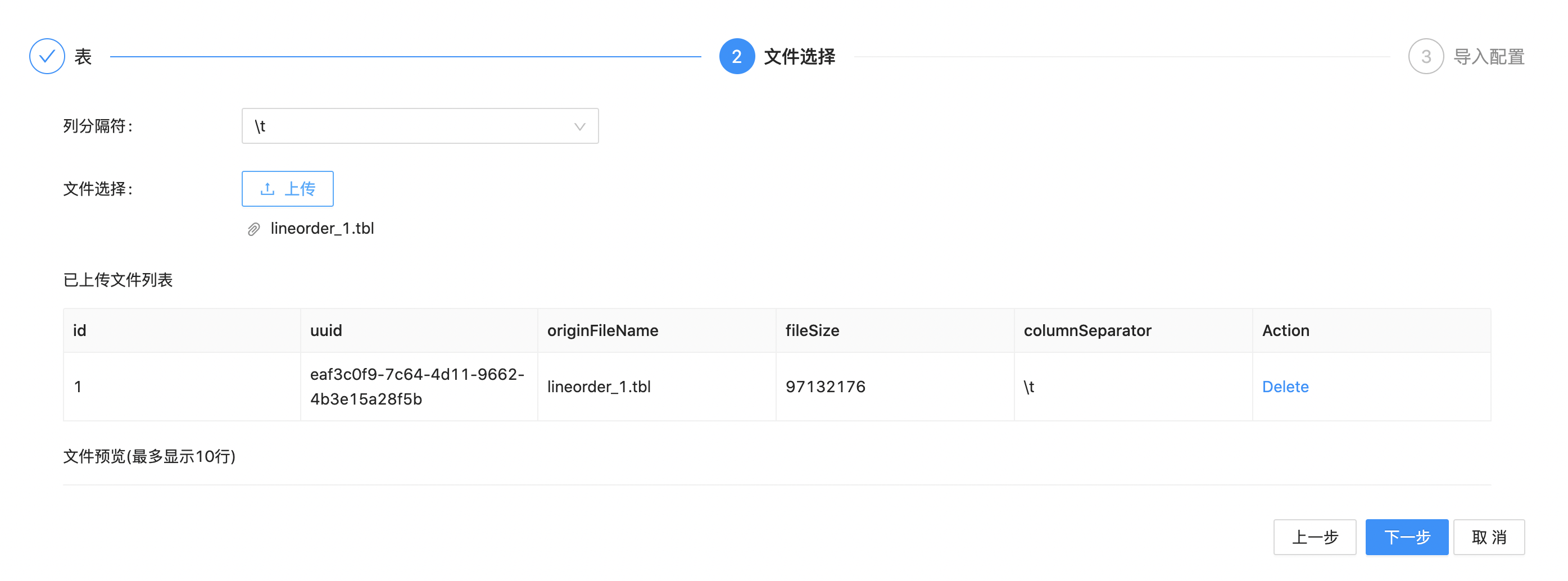
4.等待文件上传完成,点击选择下方已上传的文件。这时也会看到该文件按照指定分隔符分割后的预览数据(前10行)。
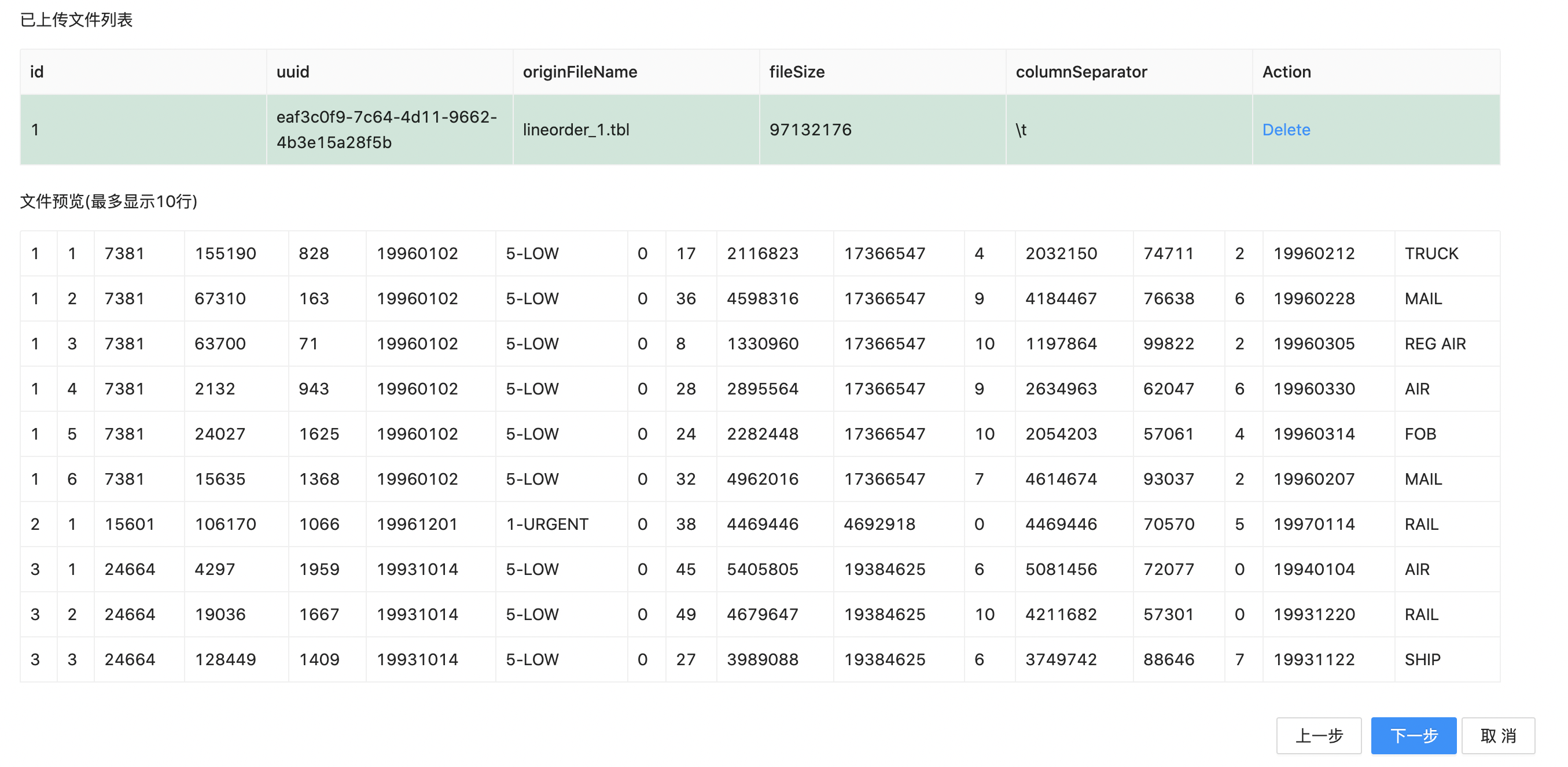
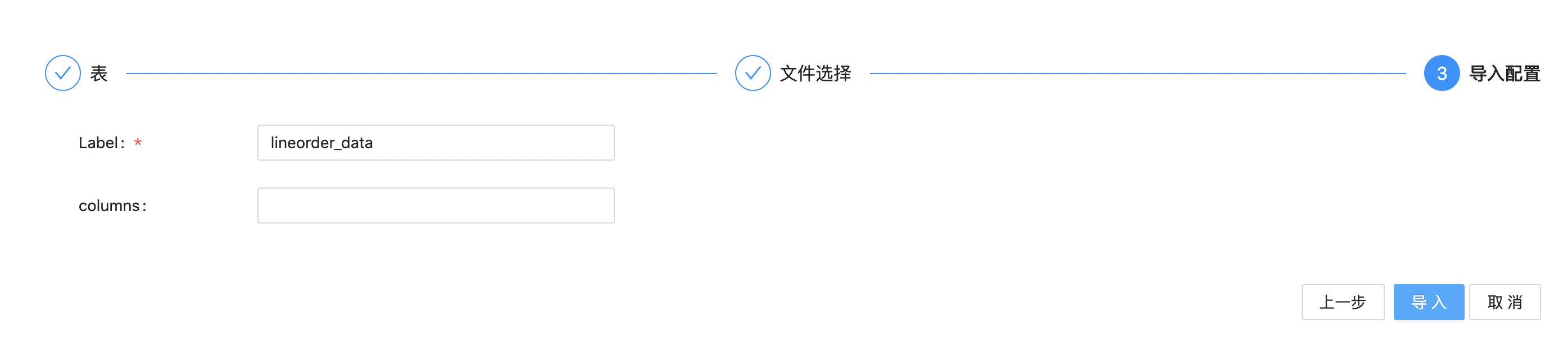
5.点击“下一步”进入到数据导入配置页面,我们以“lineorder_data”为label,然后点击“导入”按钮。
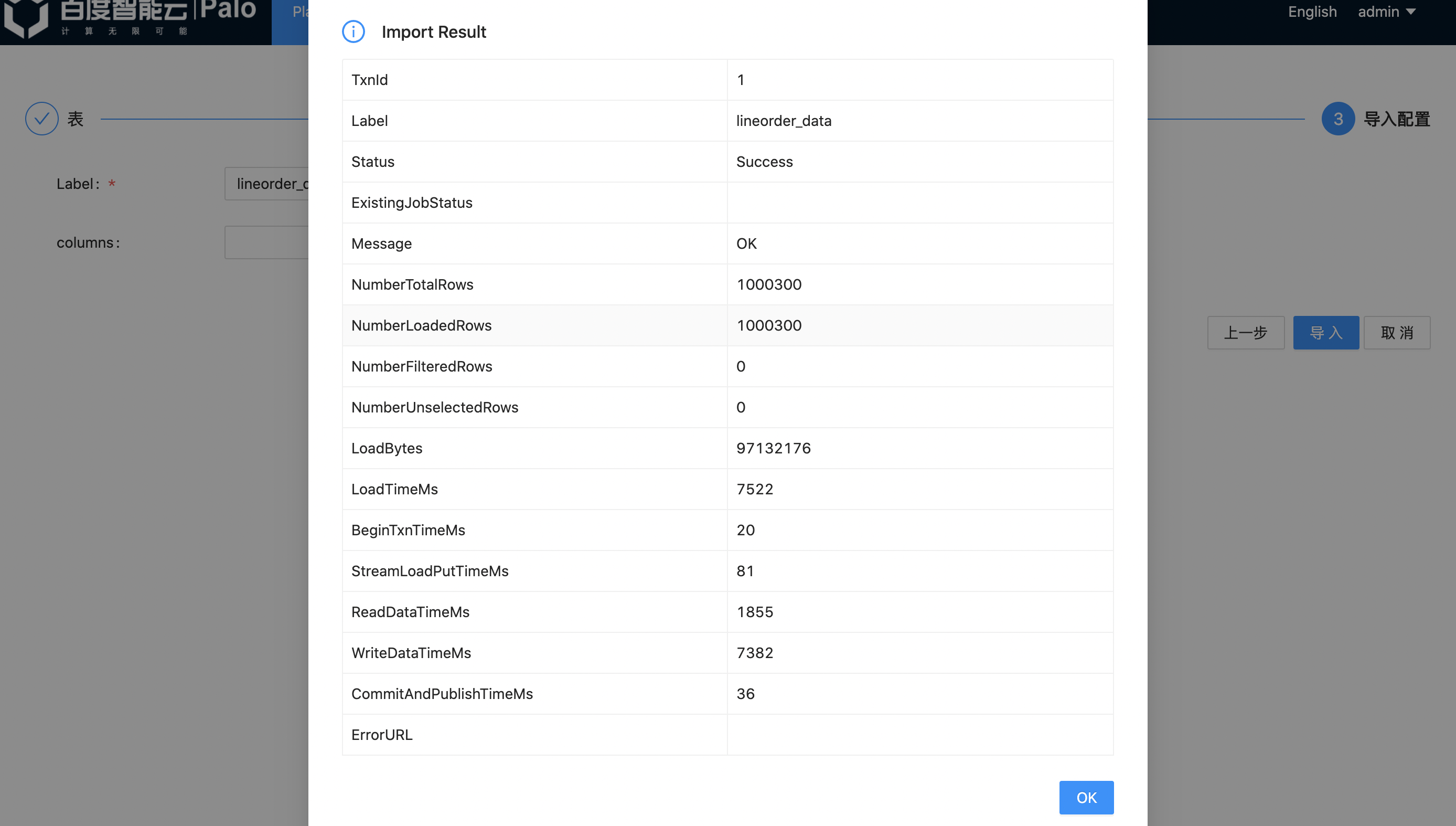
6.等待片刻,可以看到数据导入的结果。其中 Status 的状态为 Success,即表示导入成功。点击OK之后,数据导入完成。
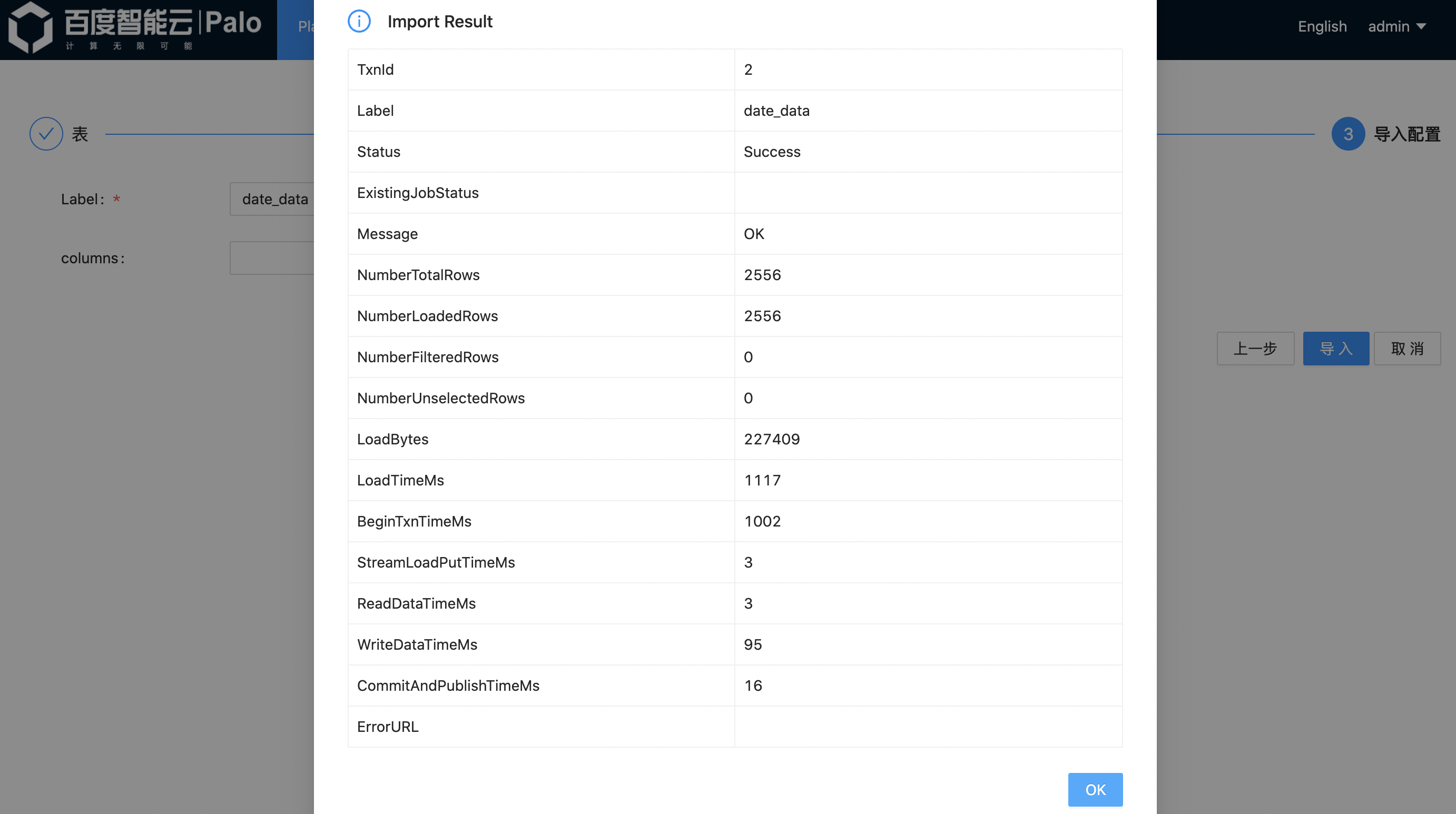
7.由于Web UI支持导入的数据大小有限,因此我们将完整的lineorder数据切分成了六份,此处我们仅导入一份数据作为演示,我们在demo文件中放置了完整数据样本,用户可以根据测试需求进行追加导入全部数据。
我们以同样的方式导入表date、customer、part、supplier对应的数据。
数据查询
简单查询
数据导入完成之后,我们可以执行一些查询语句来查看数据的状态。
可以预览表的一部分数据。
1SELECT * FROM lineorder limit 10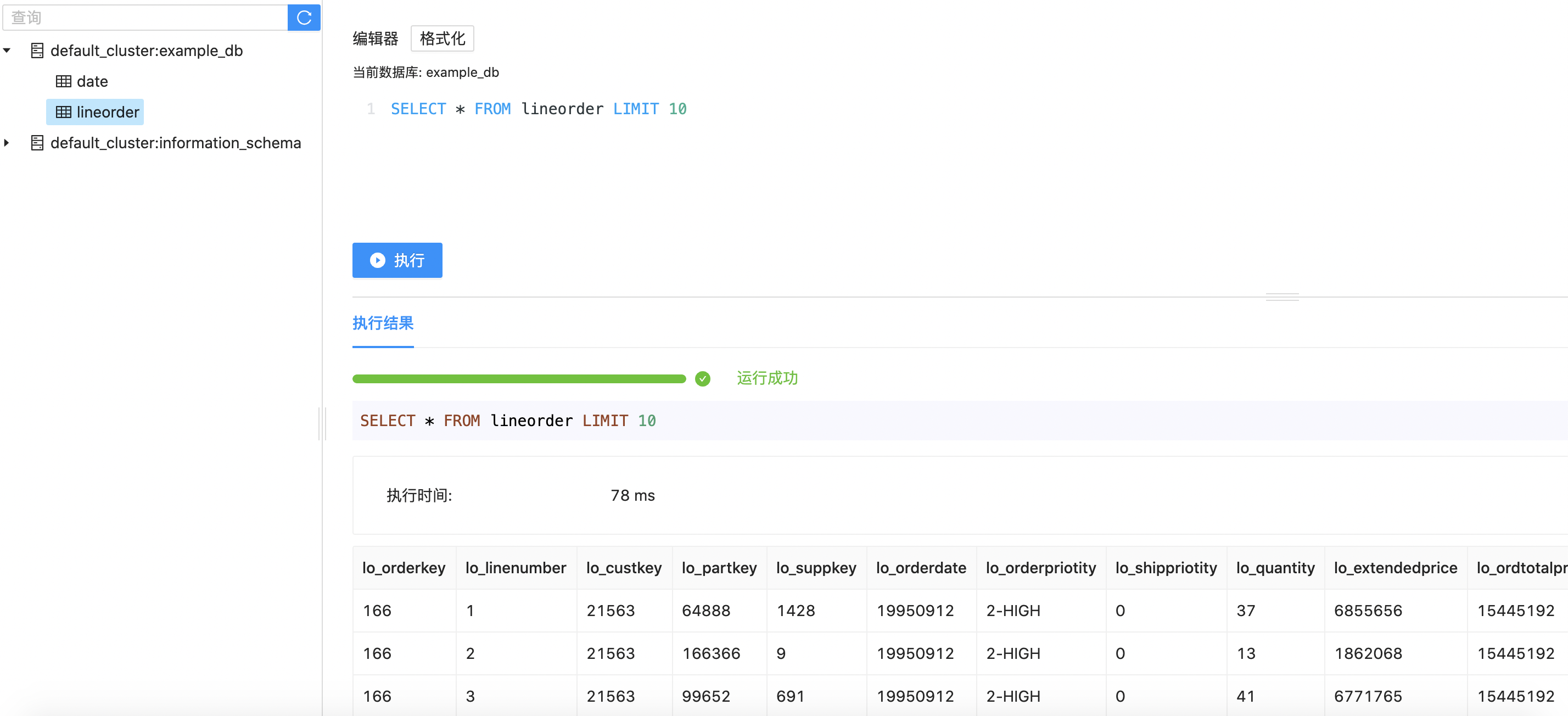
或者统计查询表的记录数量。
1SELECT COUNT(*) FROM lineorder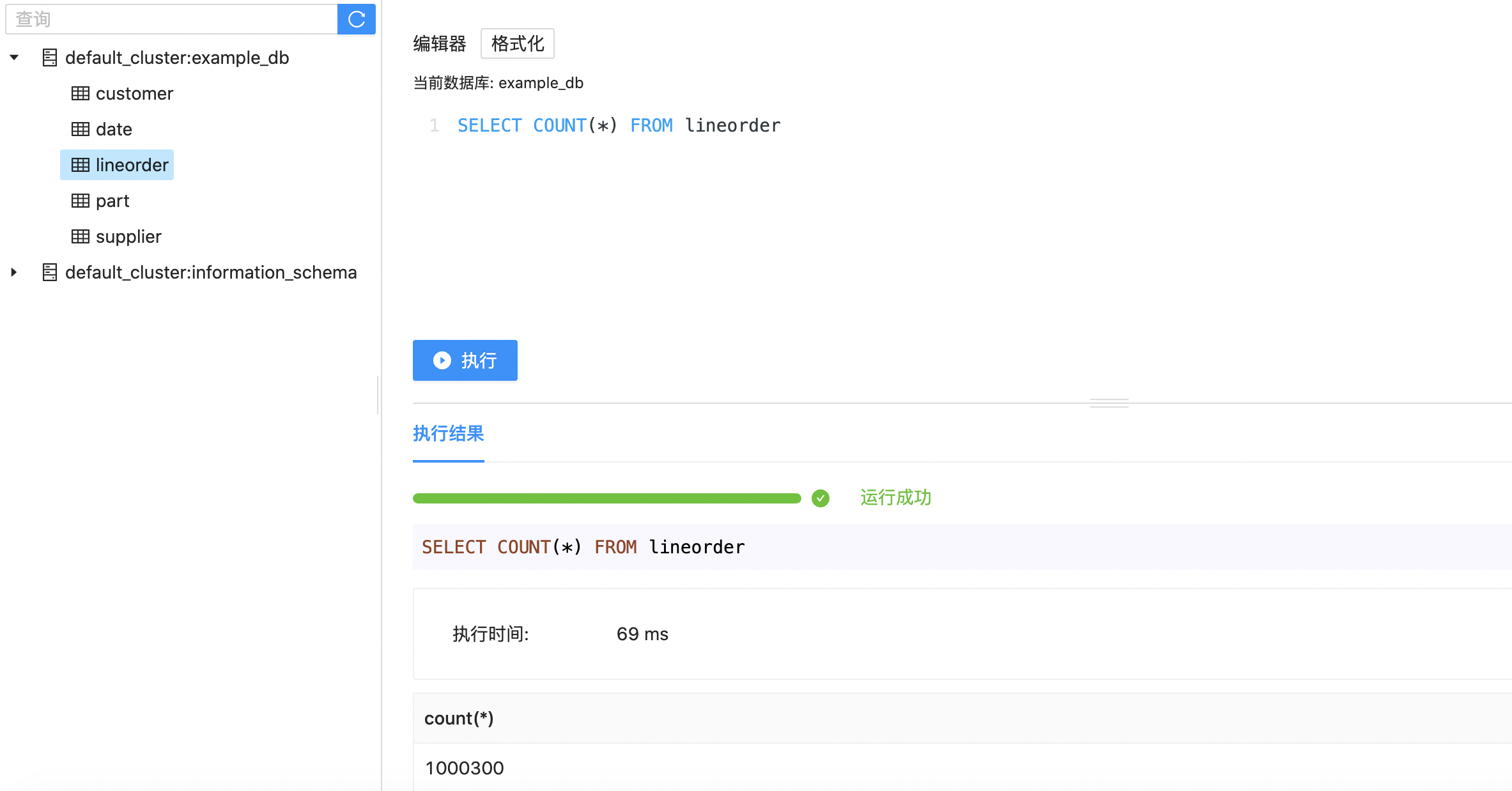
分析查询
然后可以按照我们的分析需求,执行查询操作,获取查询结果。
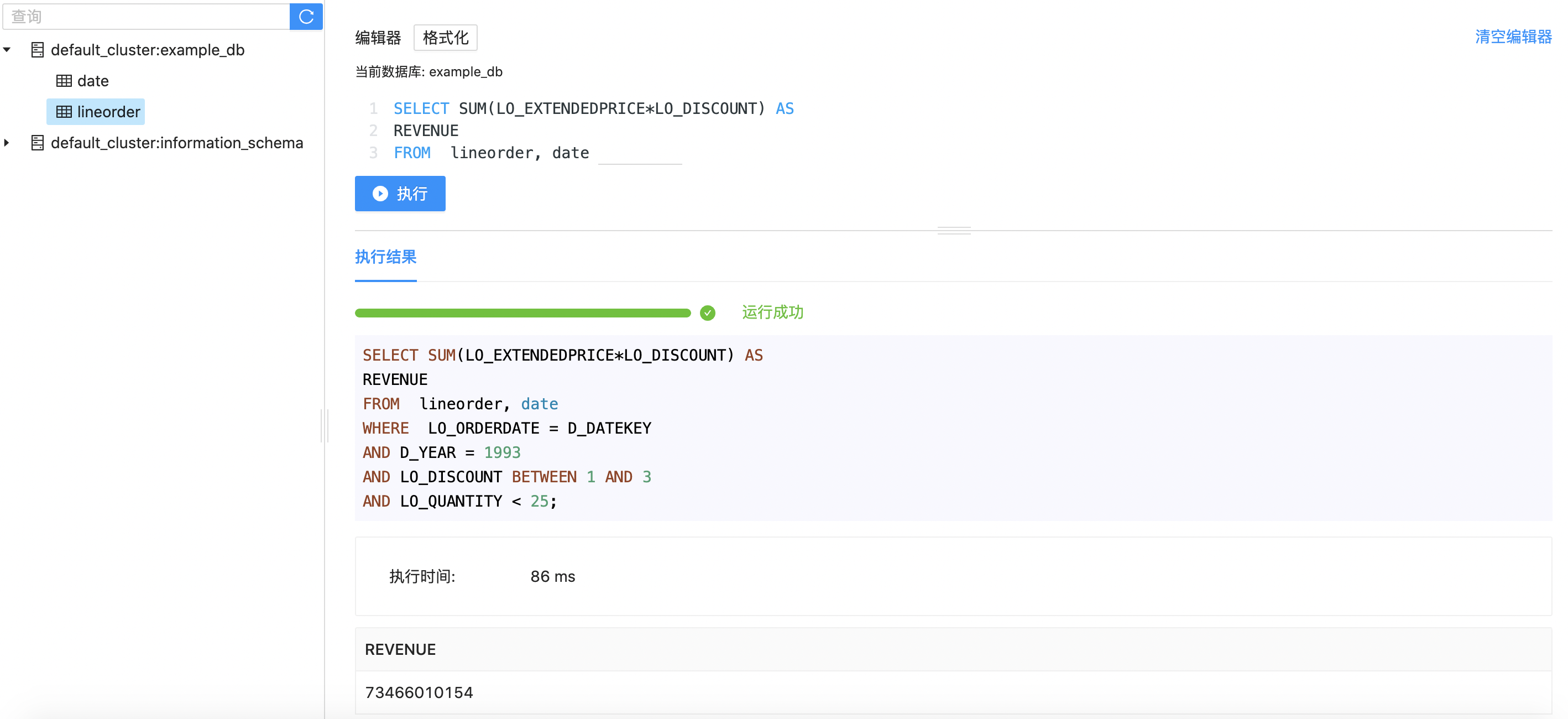
1SELECT SUM(LO_EXTENDEDPRICE*LO_DISCOUNT) AS
2REVENUE
3FROM lineorder, date
4WHERE LO_ORDERDATE = D_DATEKEY
5AND D_YEAR = 1993
6AND LO_DISCOUNT BETWEEN 1 AND 3
7AND LO_QUANTITY < 25;通过Web UI,我们在页面执行SQL,并且快速获取查询结果。
也可以执行多表的复杂查询
1SELECT C_CITY, S_CITY, D_YEAR, SUM(LO_REVENUE)
2AS REVENUE
3FROM customer, lineorder, supplier, date
4WHERE LO_CUSTKEY = C_CUSTKEY
5AND LO_SUPPKEY = S_SUPPKEY
6AND LO_ORDERDATE = D_DATEKEY
7AND C_NATION = 'UNITED STATES'
8AND S_NATION = 'UNITED STATES'
9AND D_YEAR >= 1992 AND D_YEAR <= 1997
10GROUP BY C_CITY, S_CITY, D_YEAR
11ORDER BY D_YEAR ASC, REVENUE DESC;页面查询的执行时间以及结果:
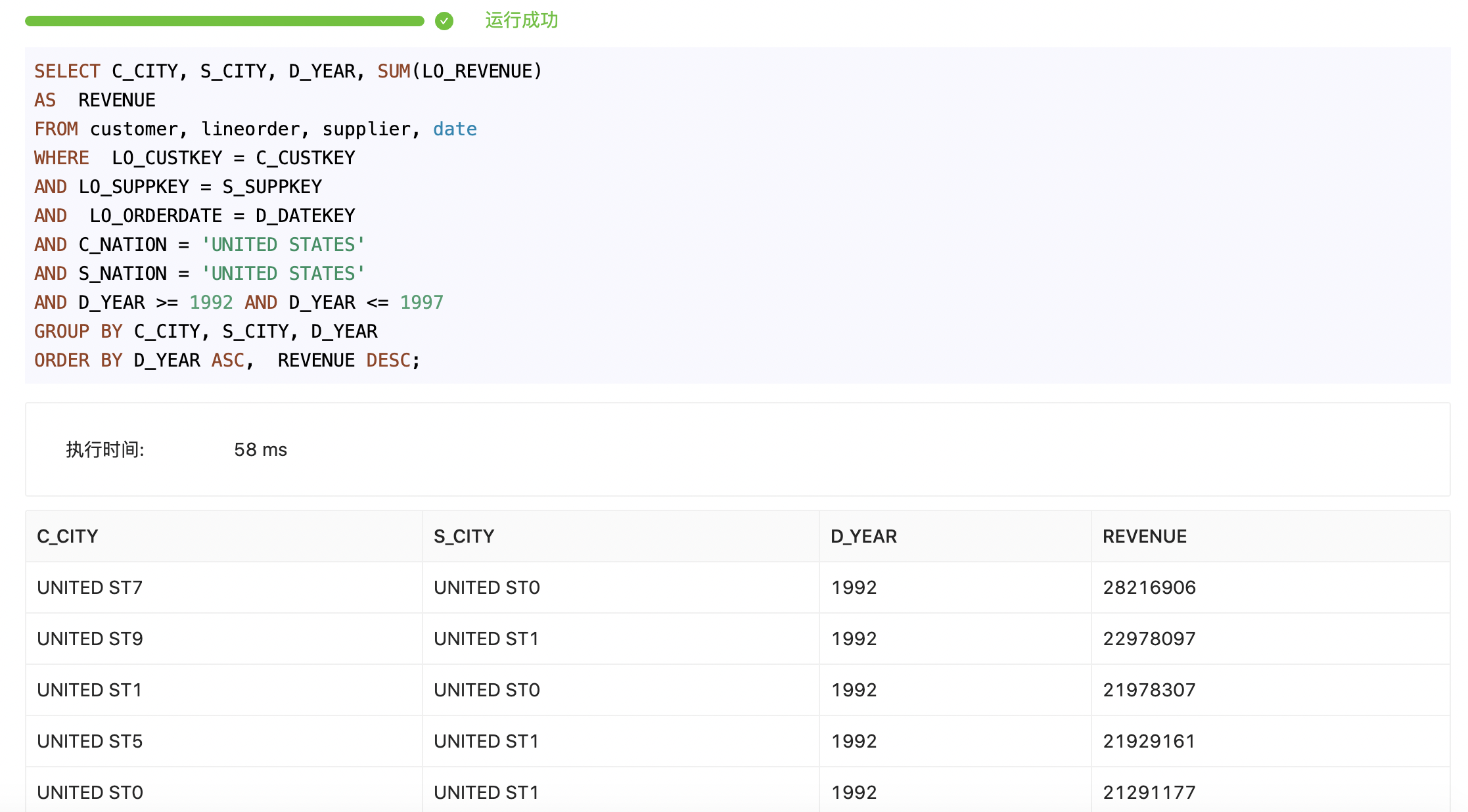
执行时间为 SQL 在服务器端实际执行耗时。因为 UI 界面经过多层代理,所以用户感知的查询延迟略慢于实际SQL的执行时间。