
FineBI(帆软)
更新时间:2025-08-21
Palo支持连接FineBI,您可以根据以下的指导步骤来连接您的可视化工具FineBI。
准备工作
- 安装FineBI 5.0及以上版本。
- 安装MySQL JDBC驱动。
登录服务器
- 打开FineBI,点击软件的“服务器地址”,进行账号配置。

- 在打开的服务器地址页面设置账号。
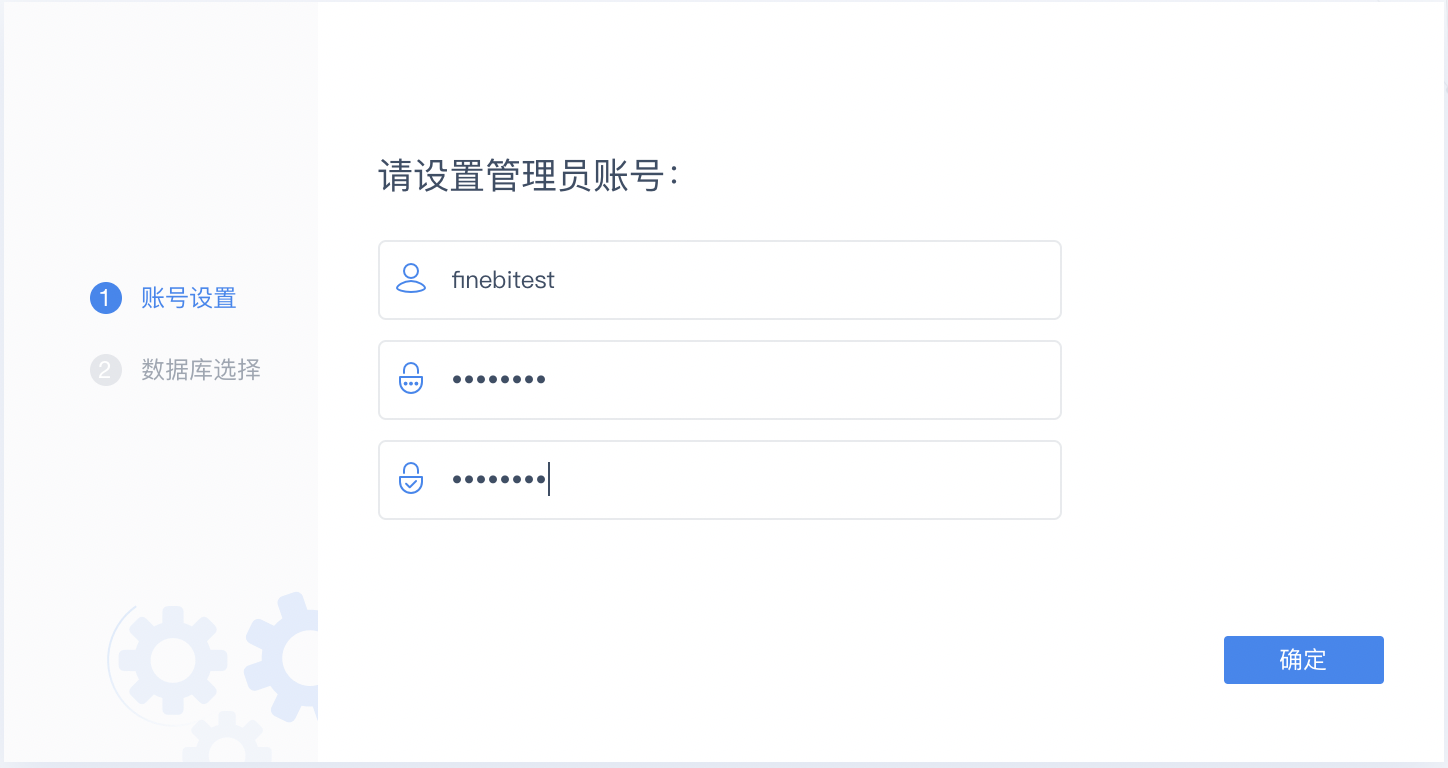
- 账号设置完成之后,进入到第二步,进行数据库选择。
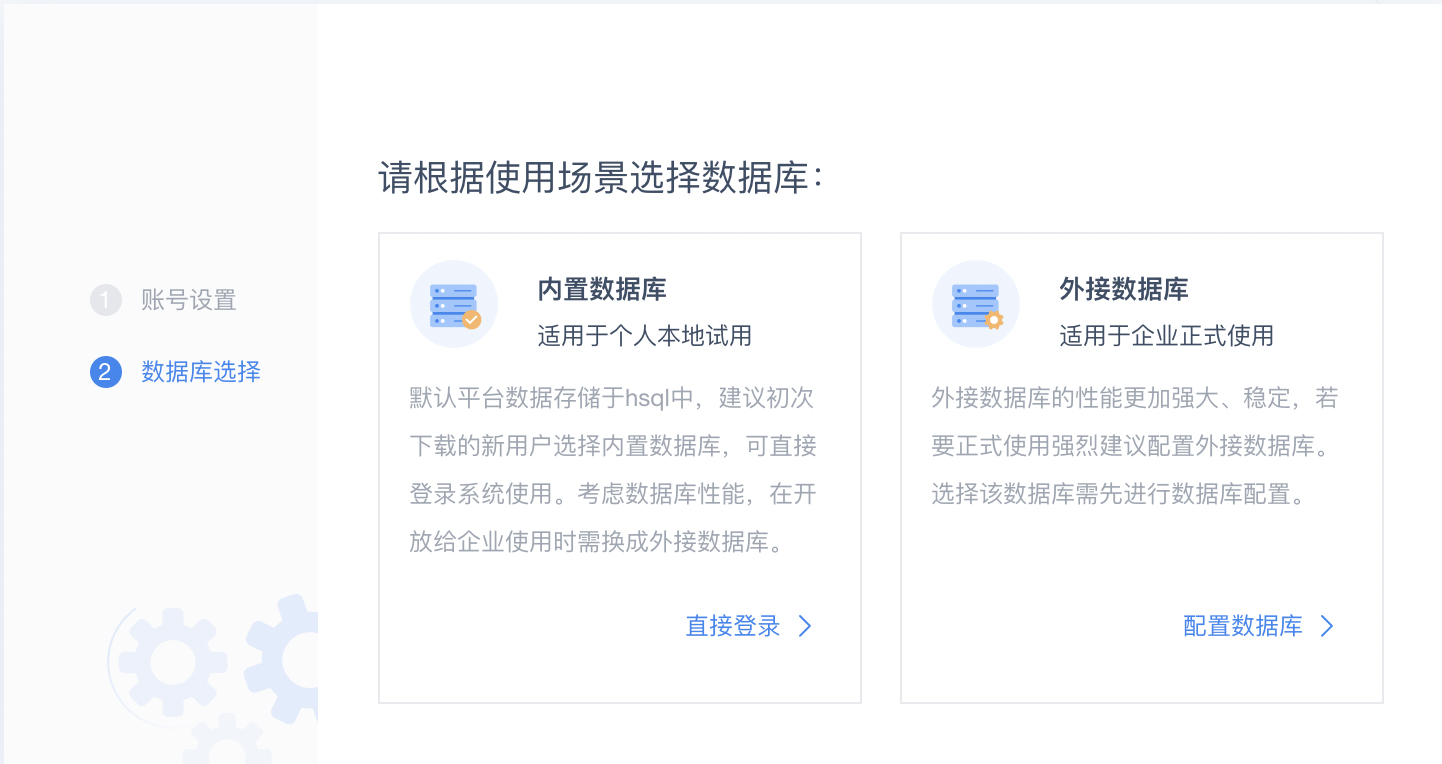
4.选择数据库,进行配置。如果是企业正式使用,可以参考FineBI帮助文档配置外接数据库进行配置。此处便于演示,我们选择“内置数据库”进行直接登录。
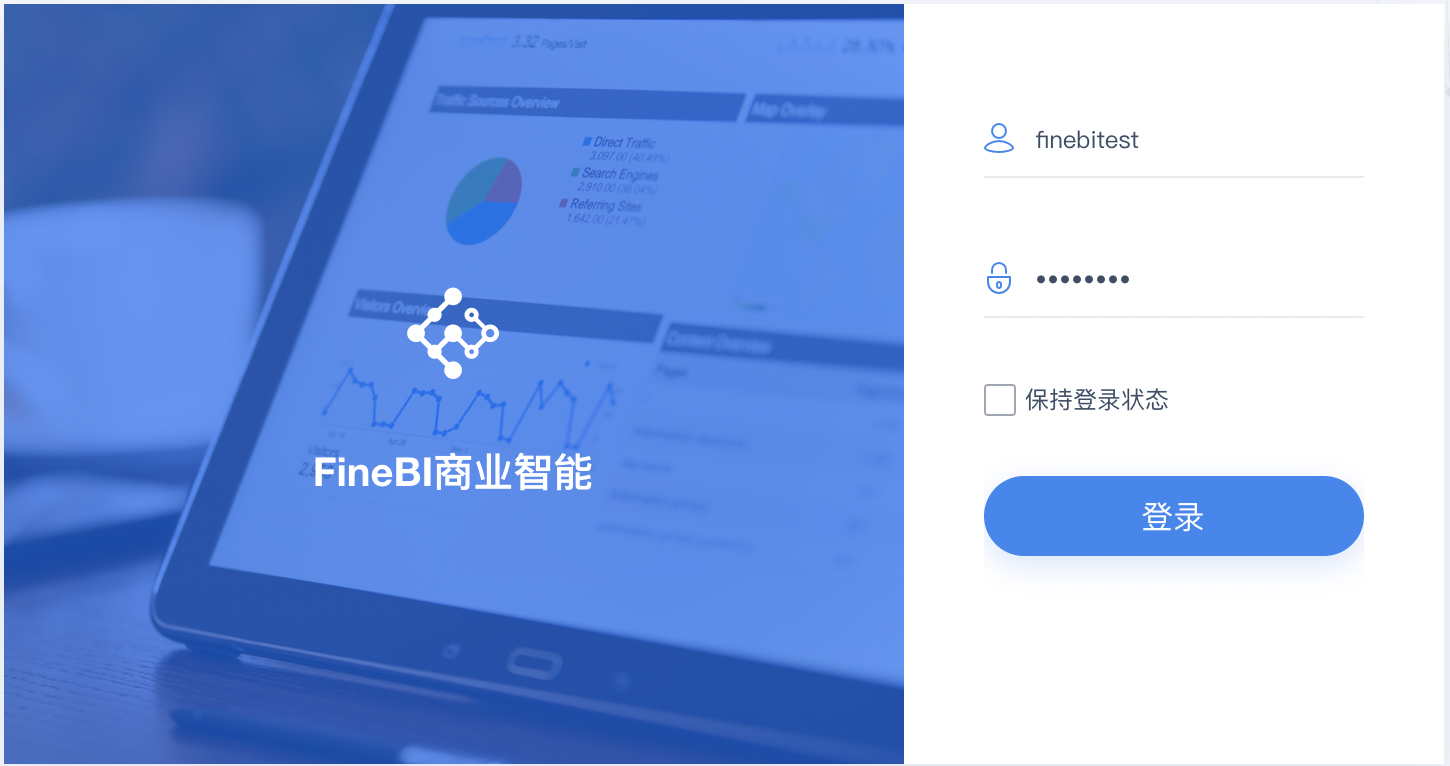
5.登录进入FineBI。
连接Palo
1.点击“系统管理-数据连接-数据连接管理”,选择MySQL类型。
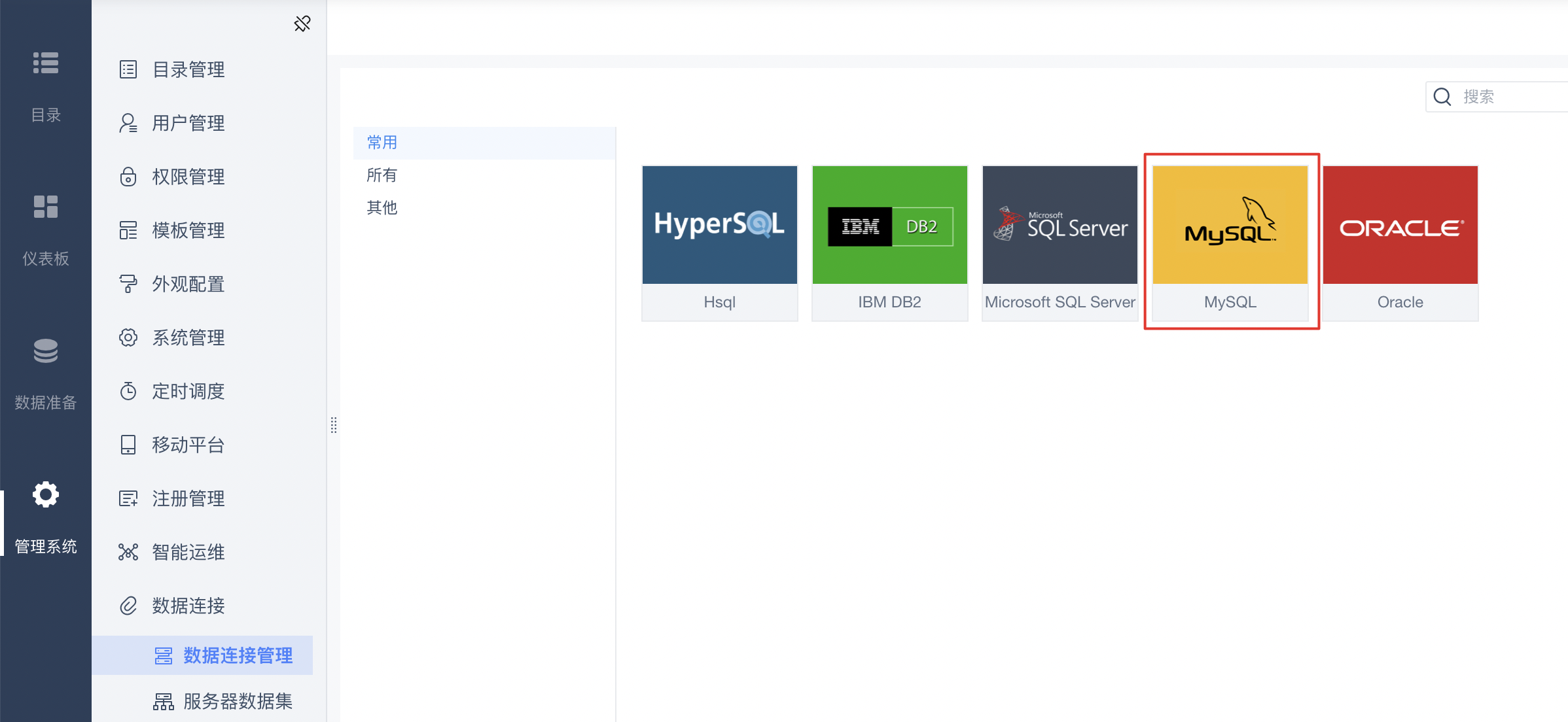
2.在数据库配置页面,填写Palo集群连接信息。
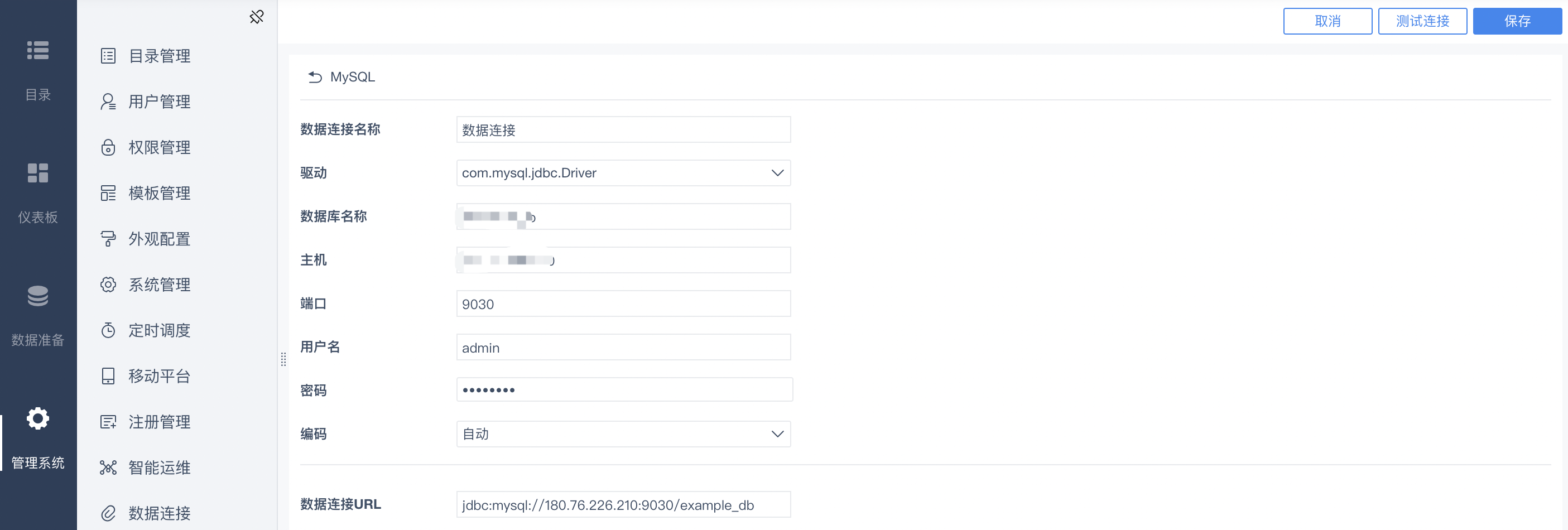
| 配置项 | 填写说明 |
|---|---|
| 数据连接名称 | 创建一个连接的名称以便于后续管理 |
| 驱动 | 选择com.mysql.jdbc.Driver |
| 数据库名称 | Palo中的数据库名称 |
| 主机 | 在Palo集群详情页面-配置信息,给LeaderNode绑定Eip,填写这个IP地址即可 |
| 端口 | 9030 |
| 用户名 | Palo集群中创建的账号,管理员账号admin |
| 密码 | 集群创建时设置的连接密码 |
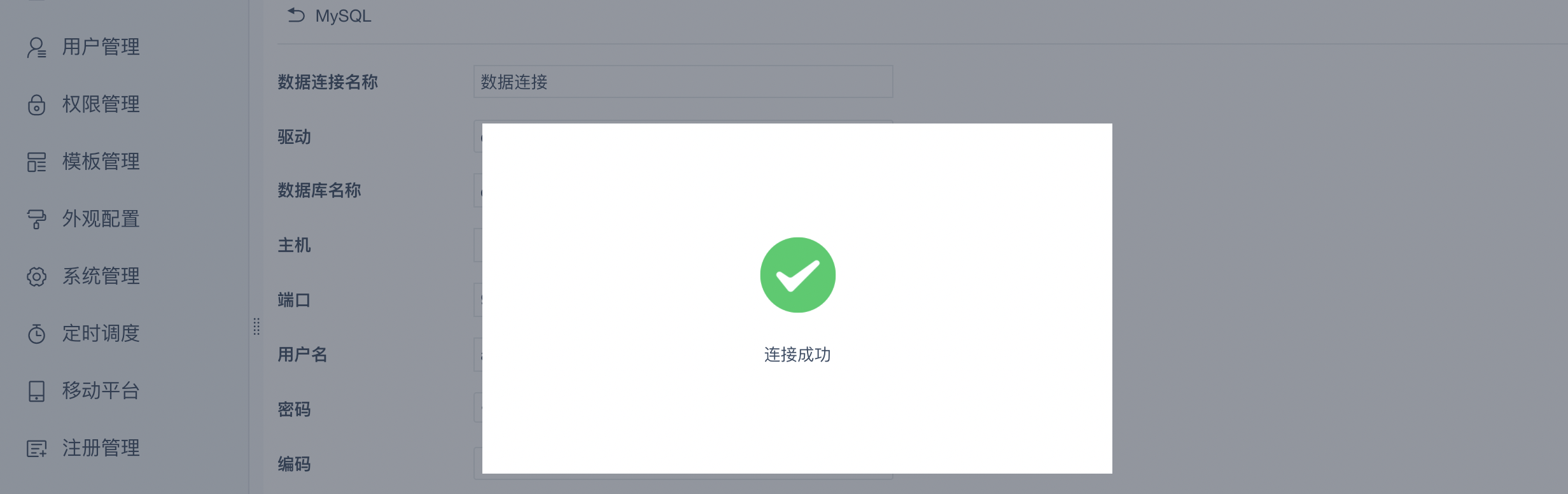
3.填写完配置信息之后,点击右上角的“测试连接”进行连通测试,系统提示连接成功后,单击页面右上角的保存按钮。至此,FineBI成功连接Palo数据库。
使用FineBI
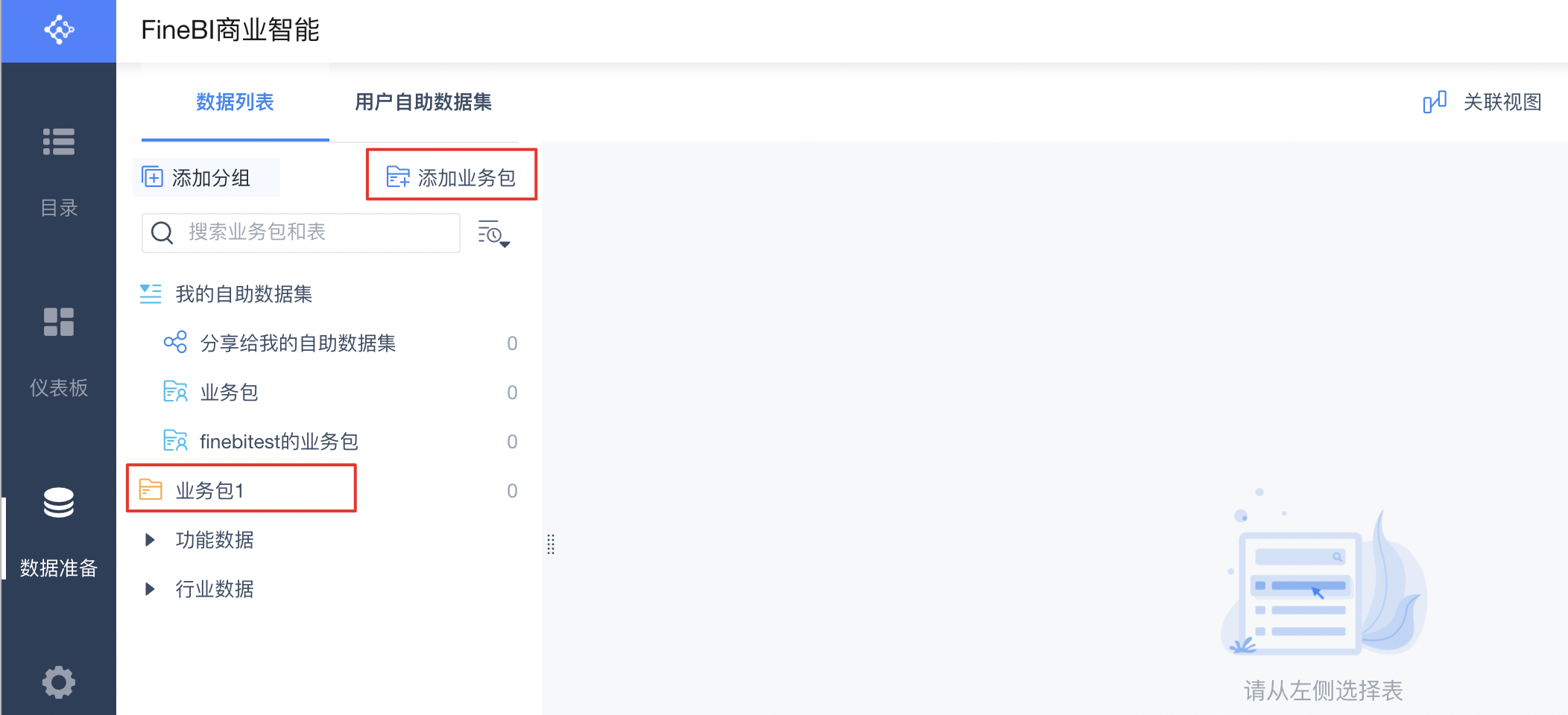
1.数据库连接完成之后,就可以在FineBI中对Palo中的数据进行分析了。点击“数据准备”,添加业务包。
2.进入业务包,点击“添加表”按钮,选择数据库表进入。
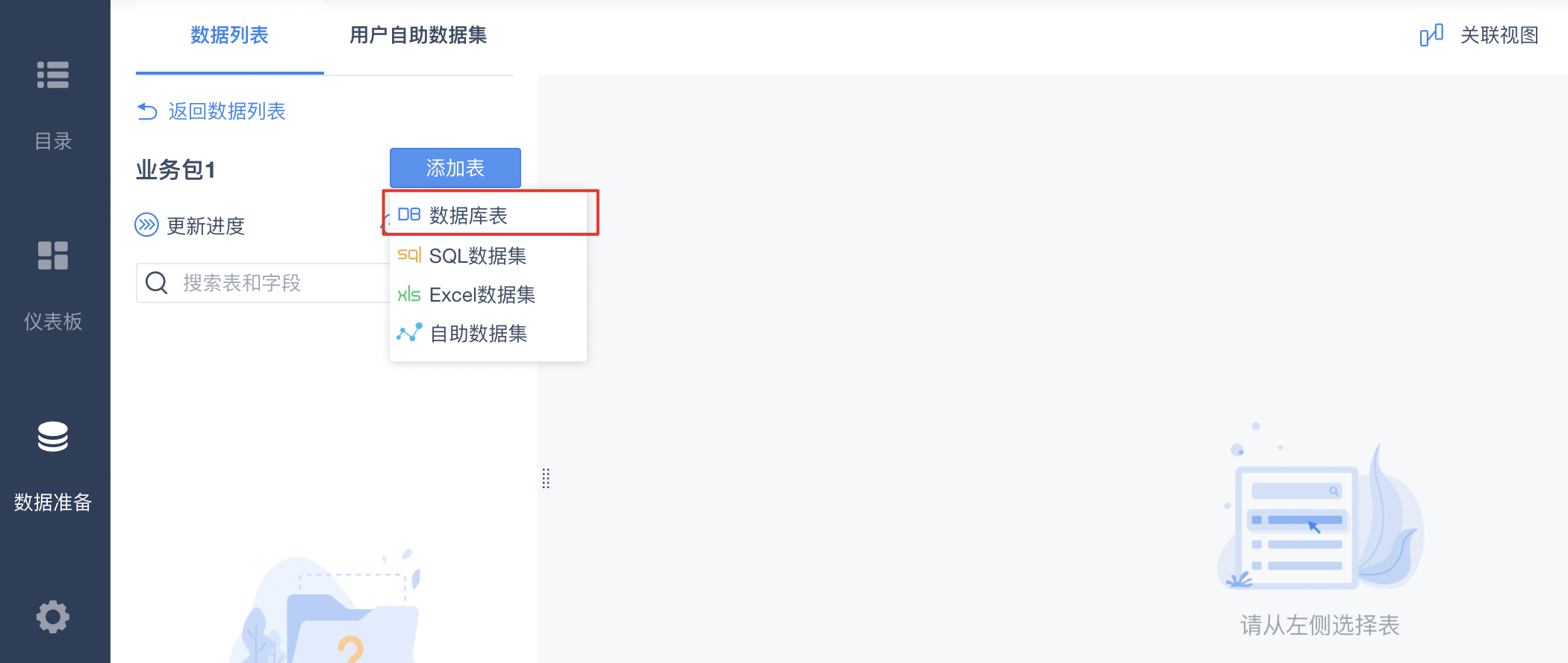
3.在数据库表页面,可以看到已连接的Palo数据库中的表。
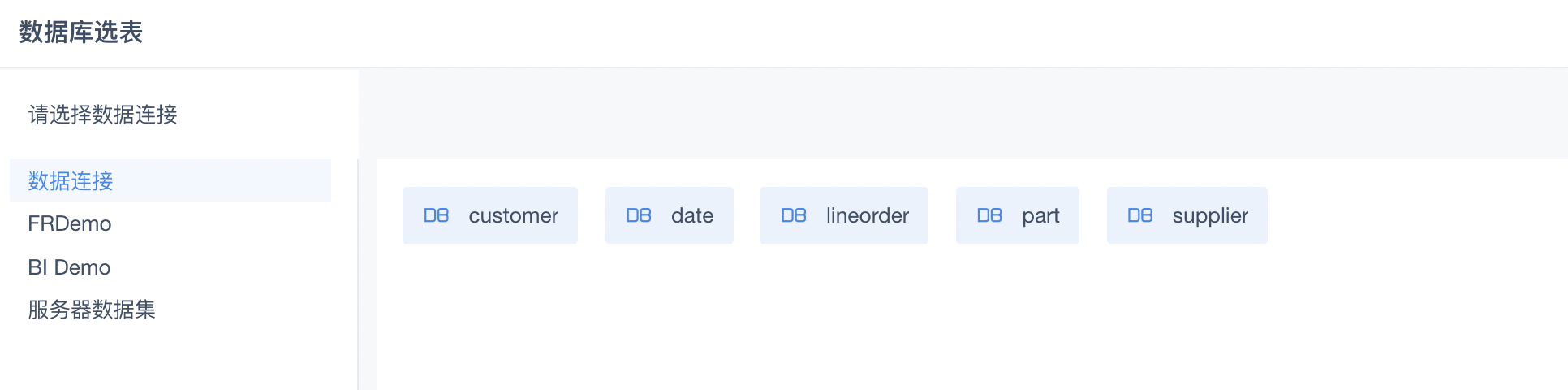
4.选择需要分析的数据,点击“确定”进行数据库连接。

5.数据库连接成功之后,就可以使用FineBI对数据进行可视化分析了。
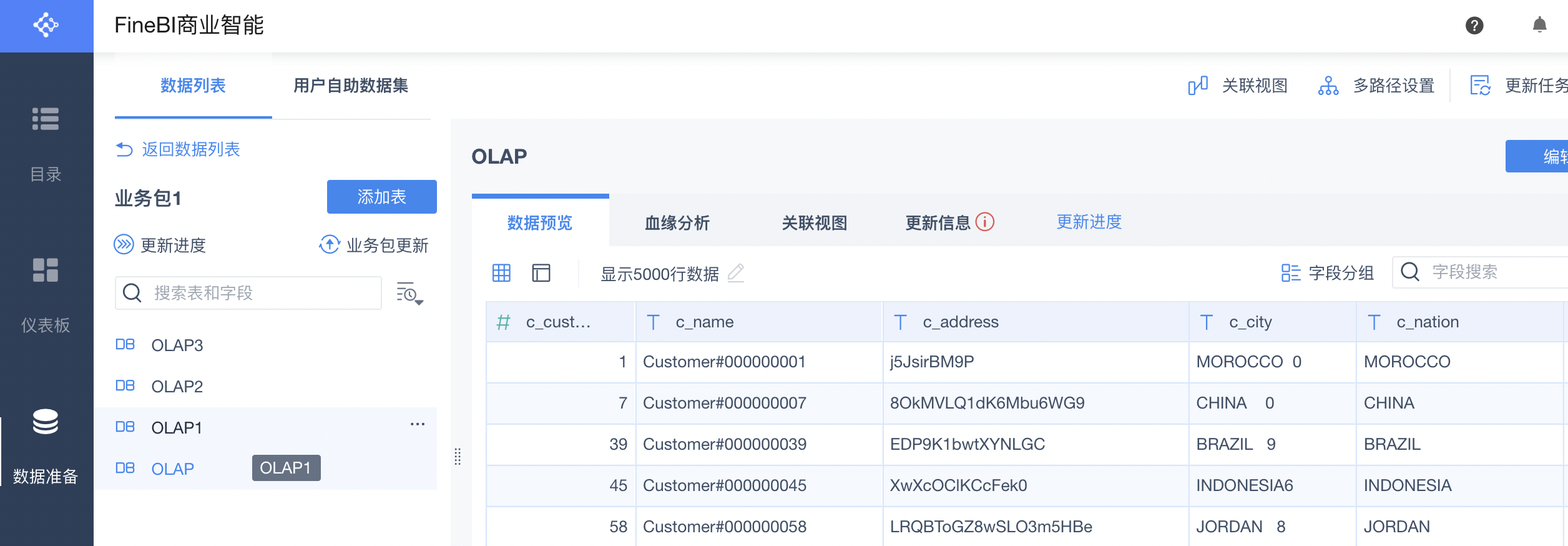
关于更多使用FineBI的操作指南,请参考FineBI帮助文档。