
将自建ClickHouse数据迁移到云ClickHouse中
更新时间:2025-08-21
本工具是为给云上bmr Clickhouse集群做上云或下云数据迁移而准备,采用点对点的方式进行迁移,支持高并行、断点续传。适用于数据量较大、数据表较多且只需保证源和目标集群间数据最终一致的场景。
环境准备
- 本工具使用python3开发,因此执行节点上需要部署python3环境,版本最低要求为3.6,推荐3.7(附件有python安装包以及已经集成好的python环境)。
- 迁移过程需要保存迁移元数据信息,元数据库选择的是mysql(每个bmr集群会自带一个mysql实例,无需另外搭建),因此需要安装python的mysql connector依赖,附件的python_venv中已经集成。
- 迁移需要连接源集群实例和目标集群实例,因此需要安装clickhouse-client依赖,附件的python_venv中已经集成.
- (可选)为了不影响原来的python环境,推荐使用附件中的python_venv集成环境来执行迁移。
- 启动虚拟环境后再启动迁移工具。

启动方式
启动之前需要将迁移任务录入元数据库,此信息对应的mysql 数据表为migrator.jobs,如下所示:
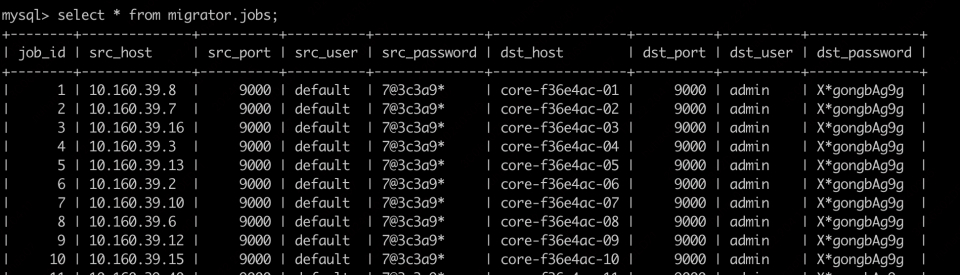
表一 字段说明
| 字段 | 字段说明 |
|---|---|
| job_id | job的标识 |
| src_host | 源集群实例主机名或ip |
| src_port | 源集群实例端口 |
| src_user | 源集群实例用户名 |
| src_password | 源集群实例密码 |
| dst_host | 目标集群实例主机名 |
| dst_port | 目标集群实例端口 |
| dst_user | 目标集群用户名 |
| dst_password | 目标集群密码 |
表二 参数说明
| 参数名称 | 参数说明 |
|---|---|
| hostname | 直接使用bmr提供的hostname,例如:core-0cb9d33-01,切记不要使用ip或者alias后的hostnmae。 |
| taskID | 当前job的task的标识,是为了提高并行度,和taskSize配合使用可以在一个job上执行更高并行度的迁移,加快迁移速度。 |
| taskSize | 当前job总共的task数,一般和taskID配合使用。 |
| runType | 当前迁移任务的类型,目前支持的类型有如下几种: |
使用实例
- 执行命令:
Plain Text
1python ck_migrator.py core-0cb9d33-01 0 5 migration_schema上述命令参数意义为:在core-0cb9d33-01 这个节点上执行job,task 并行度为5(taskID 为0,1,2,3,4),当前task id 为0,任务类型迁移库表结构(migration_schema)
- 上述命令执行后会显示:Will migrator all schemas!,执行完成后会显示以下信息:Migrator all shcema done!如果中间失败了可以重新拉起task进程,参数不变,不用担心数据或表会重复。
注意事项
- 在迁移过程中不要对源集群的库表执行ddl操作,例如增删表字段等
- 如果有物化视图需要单独迁移
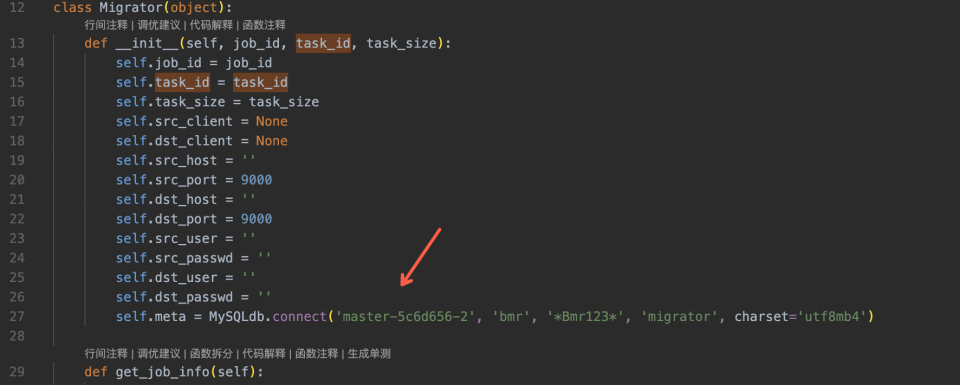
- mysql元数据库访问的用户名和密码指定在工具代码内的如图位置,可以依据实际情况进行修改,若不清楚当前集群mysql的访问密码可以咨询bmr值班同学。
4.如果想过滤自定义的表或者库,可以在工具内的如下位置进行修改:

在filter里面加上不想迁移的表名即可(直接修改代码),如下图。修改后迁移工具将不会迁移表'za_search_info' 和表 'deeptrace_info'。
