
Sqoop应用文档
更新时间:2025-08-21
场景描述
通过BMR Sqoop可以将RDS上的数据导入BMR Hive:
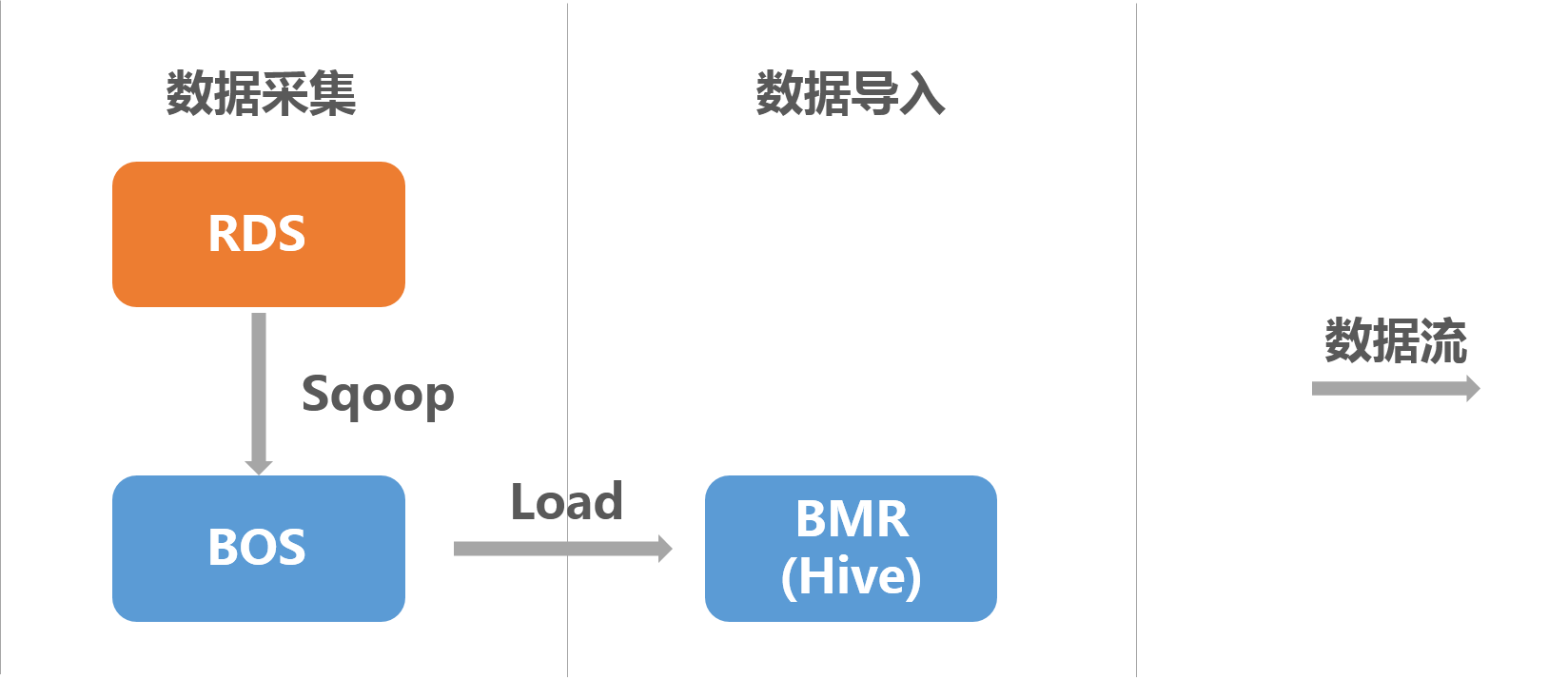
在本示例中,hive数据表的location为BOS路径,hive数据表的partition为dt(string),根据dt指定日期,区分每一天的导入数据。
说明
由于hive数据表的location为BOS,无法直接通过sqoop将RDS的数据导入hive,因为hive在加载数据时,会先将数据写入本地hdfs,然后将数据所在目录移动到hive表的location上。由于本地hdfs和BOS数据两个不同的文件系统,直接进行移动操作会抛出异常。因此,本场景需要“数据导入BOS”和“数据导入hive”两个步骤。
准备阶段
本示例所用数据为BMR Samples公共数据集。
第一步 准备数据
本示例的建表以及数据可以通过sql文件进行,下载地址。
第二步 建表并导入数据
- 关于如何登录RDS数据库,参考文档。
- 登录RDS后,选择一个数据库导入下载的sql文件,构建bmr_public_data_logs数据表,导入公共数据集。
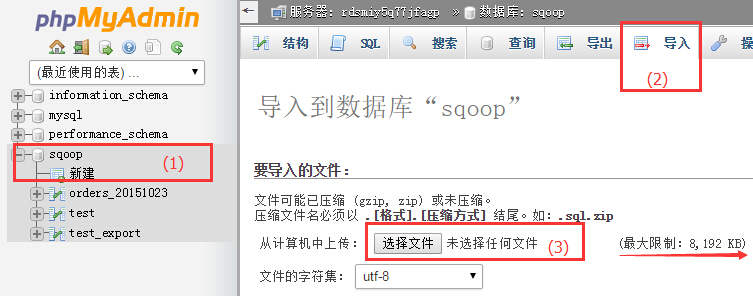
步骤如下:
- 选中数据库sqoop;
- 点击导入;
- 选择下载的sql文件,注意如果是自己的sql文件,不能超过8M,超过8M可以先尝试压缩成zip文件,注意压缩文件结尾为.sql.zip。
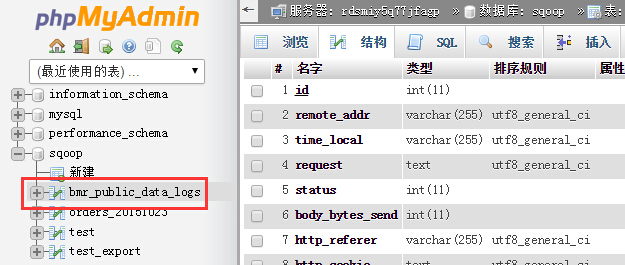
结果如下图所示:
第三步 创建Hive数据表
登录BMR集群,切换到hdfs用户,创建hive数据表。
Plain Text
1# eip可以在BMR Console集群详情页的实例列表获取
2ssh root@eip
3
4# 切换到hdfs用户
5su hdfs
6cd
7
8# 启动hive shell
9hive
10
11# 输入以下建表语句
12CREATE EXTERNAL TABLE `bmr_public_data_logs`(
13 `id` int,
14 `remote_addr` string,
15 `time_local` string,
16 `request` string,
17 `status` int,
18 `body_bytes_send` int,
19 `http_referer` string,
20 `http_cookie` string,
21 `remote_user` string,
22 `http_user_agent` string,
23 `request_time` double,
24 `host` string,
25 `msec` double)
26PARTITIONED BY (
27 `dt` string)
28ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
29STORED AS INPUTFORMAT
30 'org.apache.hadoop.mapred.TextInputFormat'
31OUTPUTFORMAT
32 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
33LOCATION
34 'bos://test-sqoop-example/bmr-public-data-logs/';注意
- 由于sqoop import默认的字段分隔符是',',所以在建表的时候将hive表的字段分隔设为',',即建表语句中:ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
- 将location的bos路径修改为自己的bos路径
数据导入BOS
使用Sqoop将RDS上的数据导入BOS,关于Sqoop的更多用法,参考文档。
Plain Text
1# eip可以在BMR Console集群详情页的实例列表获取
2ssh root@eip
3
4# 切换到hdfs用户
5su hdfs
6cd
7
8# 使用sqoop命令将数据导入bos
9sqoop import --connect jdbc//rds_mysql_hostname:port/sqoop --username test --password test --table bmr_public_data_logs --split-by id --target-dir bos://test-sqoop-example/bmr-log-test备注:
Sqoop命令中需要替换的地方,如下图所示:

(1)RDS域名; (2)RDS数据库; (3)RDS数据库用户名; (4)RDS数据库密码; (5)BOS上的目标路径(不能在sqoop导入前存在);
数据导入Hive
使用hive进行加载data
Plain Text
1# eip可以在BMR Console集群详情页的实例列表获取
2ssh root@eip
3
4# 切换到hdfs用户
5su hdfs
6cd
7
8# 启动hive shell
9hive
10
11# 导入数据
12load data inpath 'bos://test-sqoop-example/bmr-log-test' into table bmr_public_data_logs partition (dt='2015-11-02');说明:
bos://test-sqoop-example/bmr-log-test是sqoop导入数据到bos上的目标路径。- 加载数据过程中,hive将sqoop导入bos上的数据移动到hive表所指定的location中,在location(
bos://test-sqoop-example/bmr-public-data-logs/)中新建目录“dt=2015-11-02”,将数据移动到这个目录下,而sqoop导入到bos上的原目录已经成为空目录,可以进行删除。 - 在加载数据过程中,可以带有overwrite,例如“load data inpath 'bos://test-sqoop-example/bmr-log-test' overwrite into table bmr_public_data_logs partition (dt='2015-11-02');”覆盖原有partition,如果不覆盖,只会将重名文件重命名,这样如果数据文件中有重复数据,则hive表中就会存在重复数据。