
概述
更新时间:2025-08-21
BMR支持创建开启Kerberos认证的集群,在创建集群时打开安全模式开关。在这种高安全级别的集群中,所有开源组件均采用Kerberos安全模式启动,确保只有经过Kerberos认证的客户端能够访问集群提供的服务(例如HDFS)。
背景信息
集群开启Kerberos之后:
- 客户端:可以对可信任的客户端提供认证,使得可信任客户端能够正确提交作业,恶意用户无法伪装成其他用户侵入到集群当中,能够有效防止恶意冒充客户端提交作业的情况。
- 服务端:集群中的服务都是可以信任的,集群服务之间使用密钥进行通信,避免了冒充服务的情况。
开启Kerberos能够提升集群的安全性,但是也会增加用户使用集群的复杂度:
- 开启Kerberos前需要用户对Kerberos的原理、使用有一些了解,才能更好地使用Kerberos。
- 由于集群服务间的通信加入了Kerberos认证机制,认证过程会有一些轻微的时间消耗,相同作业相较于没有开启Kerberos的同规格集群执行速度会有一些下降。
Kerberos身份认证原理
Kerberos是一种基于对称密钥技术的身份认证协议,可以为其他服务提供身份认证功能,且支持SSO(即客户端身份认证后,可以访问多个服务,例如HBase和HDFS)。
Kerberos组成内容如下:
- KDC:Kerberos的服务端程序。
- Client:需要访问服务的用户(Principal),KDC和Service会对用户的身份进行认证。
- Service:集成了Kerberos的服务。例如,HDFS、YARN和HBase。
Kerberos协议认证过程如下图所示。
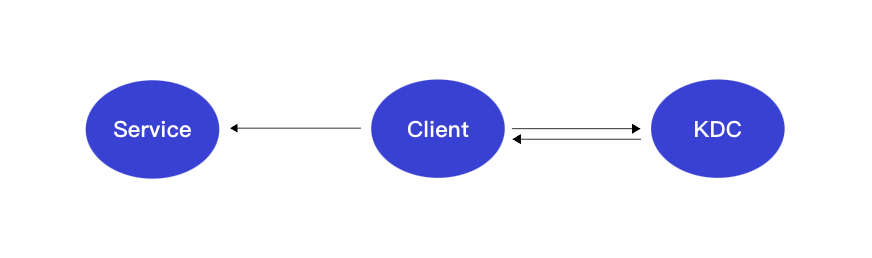
Kerberos协议认证过程主要有以下两个阶段:
- 第一阶段:KDC对Client进行身份认证
当客户端用户(Principal)访问一个集成了Kerberos的服务之前,需要先通过KDC的身份认证。
如果身份认证通过,则客户端会获取到一个TGT(Ticket Granting Ticket),后续就可以使用该TGT去访问集成了Kerberos的服务。
- 第二阶段:Service对Client进行身份认证
当用户获取TGT后,就可以继续访问Service服务。
使用TGT以及需要访问的服务名称(例如HDFS)去KDC获取SGT(Service Granting Ticket),然后使用SGT去访问Service。Service会利用相关信息对Client进行身份认证,认证通过后就可以正常访问Service服务。