Zeppelin
更新时间:2025-08-21
Zeppelin简介
zeppelin 是一个交互式数据分析工具,可支持spark、sql等数据分析工具(详细介绍,请参考zeppelin 官网)。
本文将介绍如何在zeppelin上链接配置hiveserver2,来介绍zeppelin上sql的基本使用。
集群准备
准备百度智能云环境。
-
登录控制台(百度智能云登录平台),选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
- 设置集群名称
- 设置管理员密码
- 关闭日志开关(如果打开,需要选择存放日志用的bos目录,bos目录的bucket必须已经存在
- 选择镜像版本“BMR 2.0(hadoop 3.1)“ (只有BMR2.0 及以上版本的zeppelin方可用)
- 选择内置模板“zeppelin” (默认会自动勾选hive;如果需要使用spark,请手动勾选spark组件)
- 高可用开关默认打开,可选择关闭HA模式
- 集群网络和安全设置保持默认即可
- 点击下一步,选择各个组的机器配置(master节点建议cpu核数 >= 8, 内存 >= 16G)和机器数量(master节点跟上一步中的高可用模式打开或者关闭有关)
保持其他配置为默认值,点击下一步后,再请点击“去支付”可在集群列表页可查看已创建的集群,当集群状态由“初始化中”变为“空闲中”时,集群创建成功。
-
访问集群
- 首先参考访问集群建立本地浏览器能访问集群的网络环境(可以是ssh方式也可以是openvpn方式)
- 登录集群master节点,在终端输入hostname命令可得到集群的fqdn名称(称作hostname_master)
- 浏览器输入$hosname_master:9995即可链接到zeppelin UI界面
-
使用zeppelin
- login 默认账户名和密码是admin/admin
- 新建notebook命名为hive
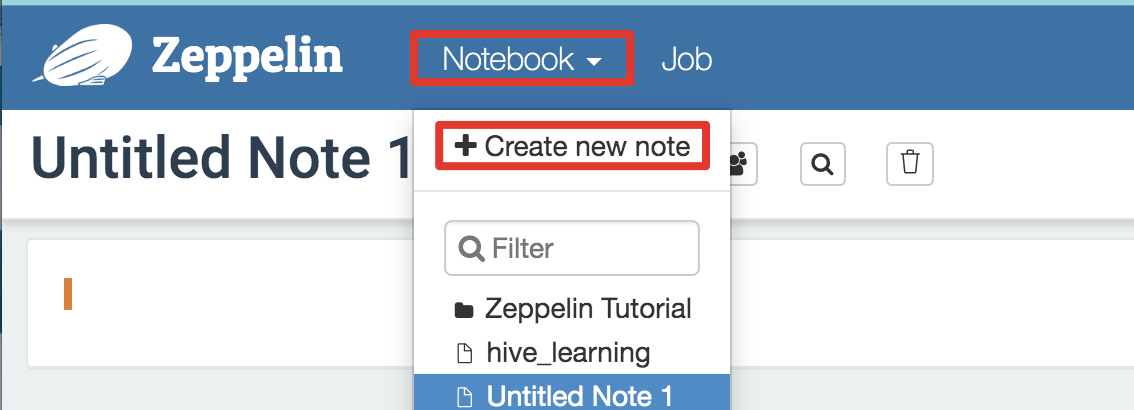
-
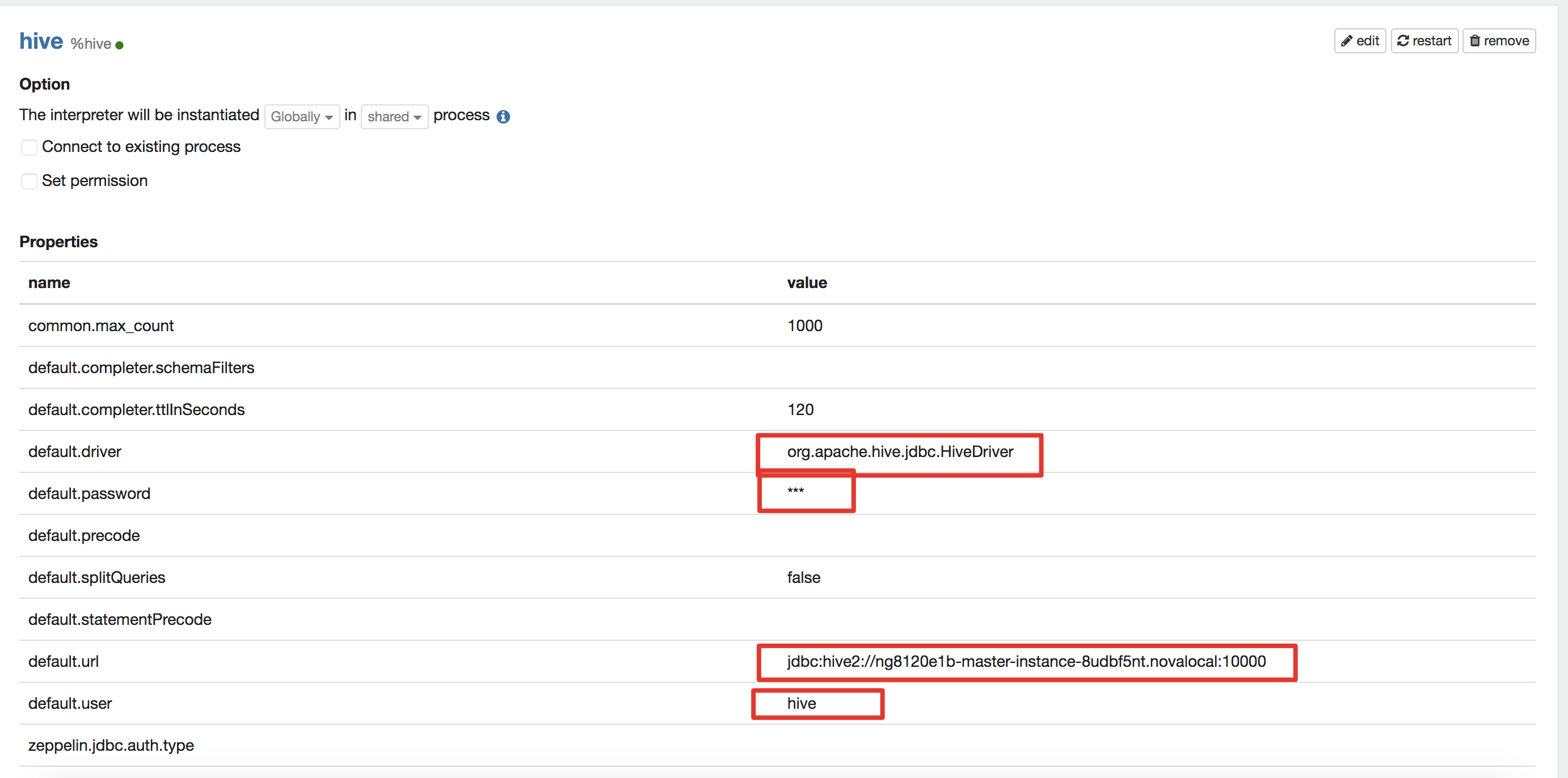
关键参数配置(选择jdbc group,配置hive时,要配置四个选项:driver, user, passwd, jdbc connection url)
- 执行命令