诊断、调优
更新时间:2025-08-21
注:自2024年6月30日起,MapReduce暂不提供作业相关功能支持,可通过第三方平台EasyDAP或开源组件Airflow提交任务。
目的
- 诊断运行失败的作业,在日志中定位失败的原因,精确定位到您的程序中错误的位置。
- 调优运行成功的作业,基于经验评价作业的配置和参数的合理性,给予您调优的建议。
适用范围
诊断或调优Hadoop MR作业,Hadoop Streaming作业,Spark作业。后续会增加Hive、Pig、HBase的诊断或调优。
查看失败作业的诊断信息
-
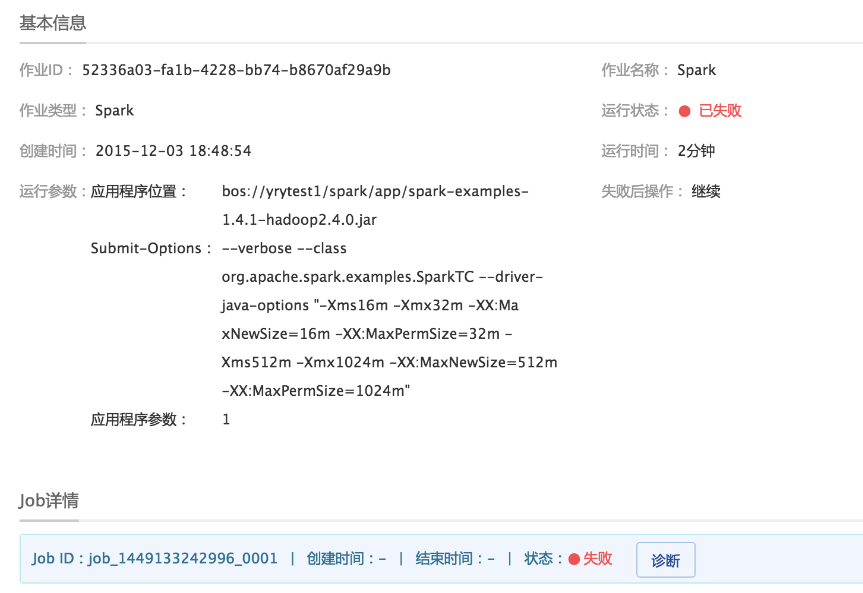
在集群作业页面,点击已失败作业的作业名称可查看该作业详情。
-
在作业详情页面,点击“诊断”,进入诊断页面。
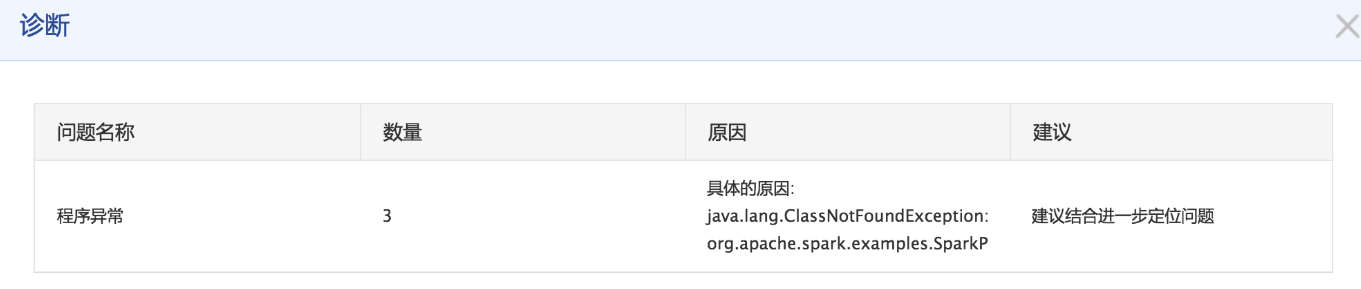
如上图所示,诊断的内容包含了用户的配置或者程序出错的信息,以及给出的建议。其中,如果出错的原因是在您的程序中,诊断功能还会扫描用户的代码中的异常栈或错误栈,剔除框架中可能对您定位问题无用的错误信息,直接定位到您程序中错误的代码。如果您想要了解更加具体的错误,还可以查看bos中的错误文件信息。

查看成功作业的调优信息
- 在集群作业页面,点击已完成作业的作业名称可查看该作业详情。

- 在作业详情页面,点击“调优”,进入调优页面。
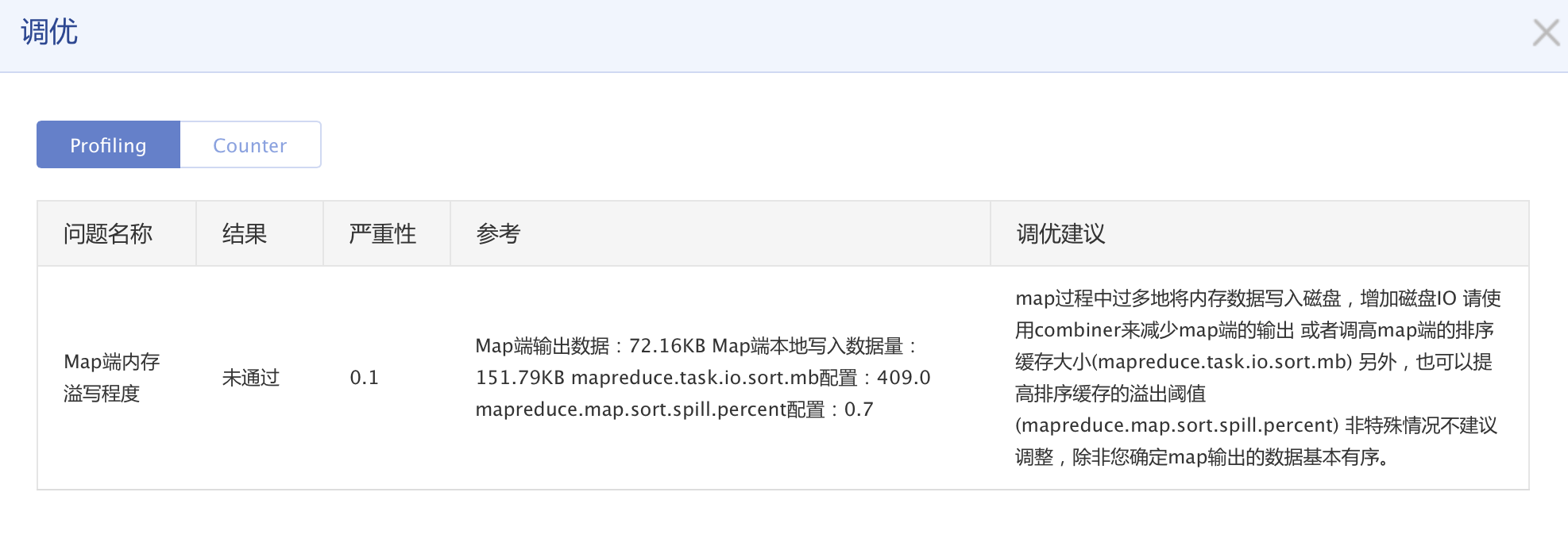 在集群中预设的参数是针对大多数作业的调优权衡的结果,不同作业的最优参数也不同,BMR调优会根据您作业的信息给予合理的作业参数调整。在BMR中内置了Map/Reduce任务数均衡性、内存溢写检查、Reduce分桶均匀度等十多项调优规则,在作业运行过程中收集集群环境数据和作业运行的信息,在作业结束时根据收集到的信息计算这十多种规则的评分情况,一旦超过阈值则给予警告,列出未通过的原因以及调优的方向。未通过的原因通常是因为作业参数设置不合理,或者套餐选择不合理,BMR的调优会自动收集您设置的配置参数和系统参数,对比不同参数对作业运行的影响并给予建议。例如在Map/Reduce任务数均衡性的检查中,BMR会权衡每个Map和Reduce任务所处理的数据量、任务处理时间,根据百度积累多年来的经验值给出合适的Map和Reduce的任务数量建议。
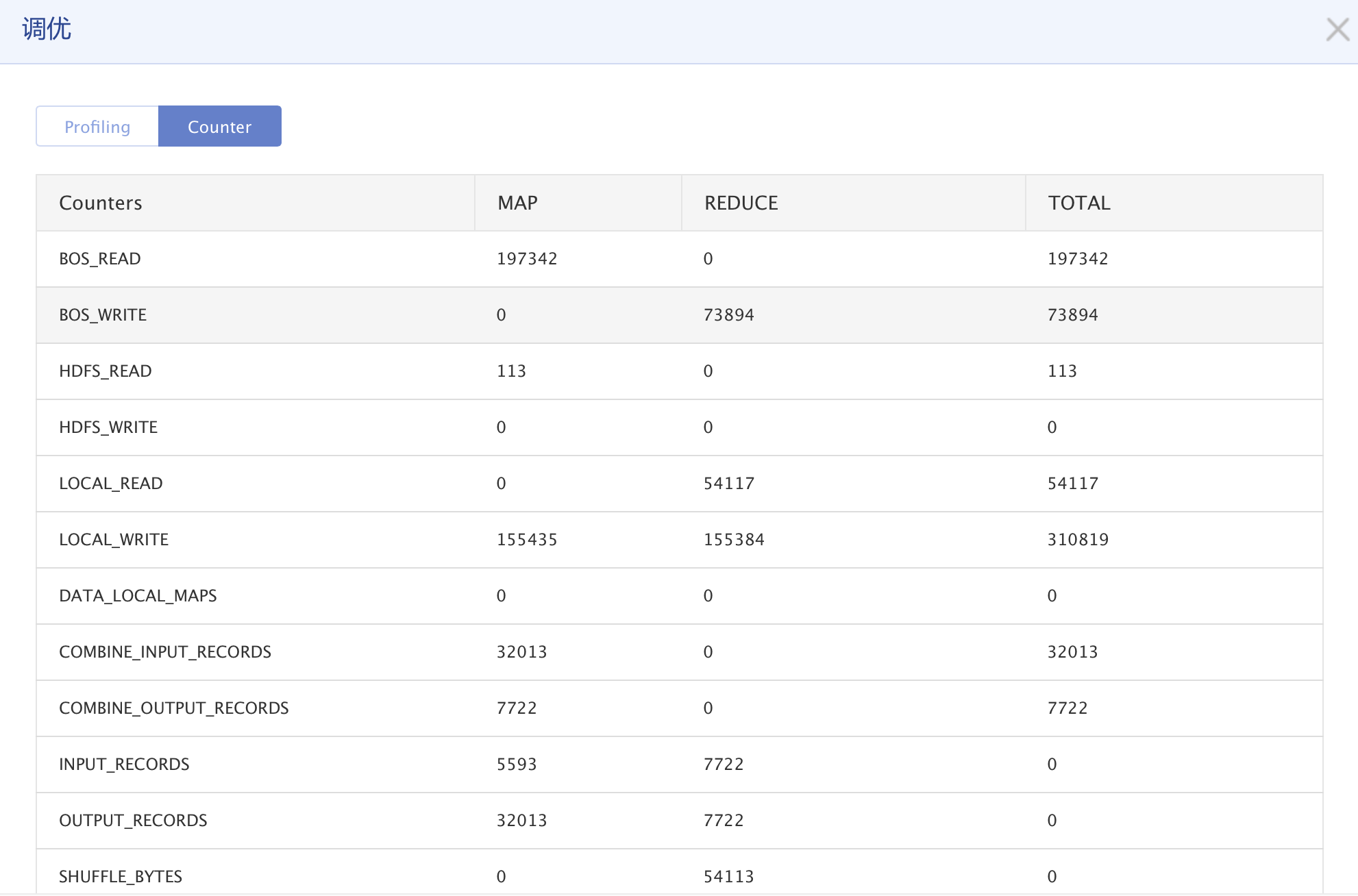
在集群中预设的参数是针对大多数作业的调优权衡的结果,不同作业的最优参数也不同,BMR调优会根据您作业的信息给予合理的作业参数调整。在BMR中内置了Map/Reduce任务数均衡性、内存溢写检查、Reduce分桶均匀度等十多项调优规则,在作业运行过程中收集集群环境数据和作业运行的信息,在作业结束时根据收集到的信息计算这十多种规则的评分情况,一旦超过阈值则给予警告,列出未通过的原因以及调优的方向。未通过的原因通常是因为作业参数设置不合理,或者套餐选择不合理,BMR的调优会自动收集您设置的配置参数和系统参数,对比不同参数对作业运行的影响并给予建议。例如在Map/Reduce任务数均衡性的检查中,BMR会权衡每个Map和Reduce任务所处理的数据量、任务处理时间,根据百度积累多年来的经验值给出合适的Map和Reduce的任务数量建议。 - 查看counter信息。在作业结束后可查看不同counter的信息,根据这些信息,您可以更方便地了解到作业执行时的情况,以及针对这些信息对程序做出相应的改进。