Kudu
1.什么是Kudu
Kudu是一个用于结构化数据的开源存储引擎, 它支持低延迟的随机访问, 以及高效的分析存取模式. Kudu使用水平partition和副本技术来将数据分布式化, 每个partition的副本用Raft协议同步, 保证了低平均恢复时间和低长尾延迟. Kudu围绕着Hadoop生态圈设计, 支持多种存取方式如Apache Impala, Apache Spark和MapReduce。
此外,Kudu还有更多优化的特点:
- OLAP 工作的快速处理。
- 与 MapReduce,Spark 和其他 Hadoop 生态系统组件集成。
- 与 Apache Impala(incubating)紧密集成,使其与 Apache Parquet 一起使用 HDFS 成为一个很好的可变的替代方案。
- 强大而灵活的一致性模型,允许您根据每个 per-request(请求选择)一致性要求,包括 strict-serializable(严格可序列化)一致性的选项。
- 针对同时运行顺序和随机工作负载的情况性能很好。
- High availability(高可用性)。Tablet server 和 Master 使用 Raft Consensus Algorithm 来保证节点的高可用,确保只要有一半以上的副本可用,该 tablet 便可用于读写。例如,如果 3 个副本中有 2 个或 5 个副本中的 3 个可用,则该 tablet 可用。即使在 leader tablet 出现故障的情况下,读取功能也可以通过 read-only(只读的)follower tablets 来进行服务。
- 结构化数据模型。
2.Kudu常见的几个应用场景
- 实时更新的应用。刚刚到达的数据就马上要被终端用户使用访问到。
-
时间序列相关的应用,需要同时支持:
- 根据海量历史数据查询。
- 必须非常快地返回关于单个实体的细粒度查询。
- 实时预测模型的应用,支持根据所有历史数据周期地更新模型。
- 有关这些和其他方案的更多信息,请参阅 Example Use Cases。
3.Kudu使用
准备百度智能云环境。
登录控制台,选择“产品服务->MapReduce BMR”,点击“创建集群”,进入集群创建页,并做如下配置:
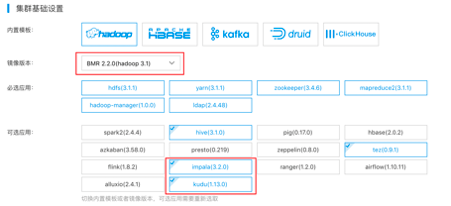
1. 创建一个bmr2.2.0镜像的集群,选择kudu+impala
选择了kudu,则集群必须有2个master节点和至少3个core节点。(由于task节点可以进行弹性伸缩,故而默认不启动tserver进行kudu数据存储。)
2.登录控制台
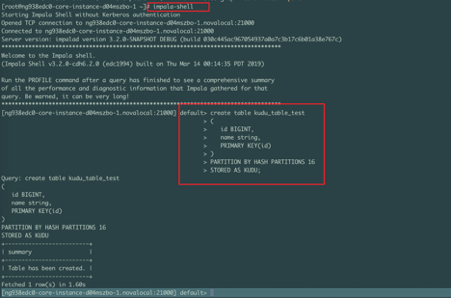
创建完成之后,登录master节点,ssh到impalad所在的host,通过impala-shell进入impala控制台
2.1 通过impala创建kudu表
1create table kudu_table_test
2(
3 id BIGINT,
4 name string,
5 PRIMARY KEY(id)
6)
7PARTITION BY HASH PARTITIONS 16
8STORED AS KUDU;具体如下图所示:
2.2 insert
insert into kudu_table_test values(1, "baidu_bmr");

2.3 update
update kudu_table_test set name='baidu_bmr2' where id=1;

2.4 select
select * from kudu_table_test;

2.5 delete
delete from kudu_table_test where id=1;

3、kudu cli使用
同时可以在集群上通过kudu cli对kudu进行管理。
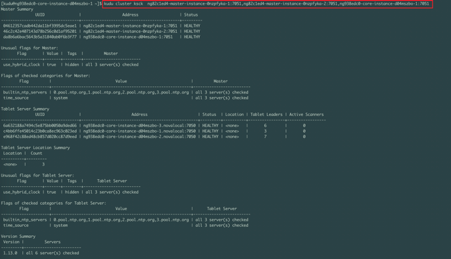
3.1 查看kudu集群状态
kudu cluster ksck ng82c1ed4-master-instance-0nzpfyka-1:7051,ng82c1ed4-master-instance-0nzpfyka-2:7051,ng938edc0-core-instance-d04mszbo-1:7051
需要指定三个kudu master的地址
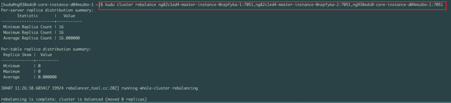
3.2 rebalance
kudu cluster rebalance ng82c1ed4-master-instance-0nzpfyka-1:7051,ng82c1ed4-master-instance-0nzpfyka-2:7051,ng938edc0-core-instance-d04mszbo-1:7051
当kudu集群上tserver数据分配不合理时,可以手动通过kudu cli进行数据rebalance