
创建作业
注:自2024年6月30日起,MapReduce暂不提供作业相关功能支持,可通过第三方平台EasyDAP或开源组件Airflow提交任务。
使用hadoop镜像的集群可添加的作业类型是:java,streaming。使用spark镜像的集群可添加作业类型:spark,java,streaming。集群中添加了应用后便可添加该应用的作业,即创建集群时添加了hive应用,则可创建hive作业,添加了pig应用,则可创建pig作业。
BMR将为用户保留一年的作业历史记录,超过此期限的作业历史将被清空,请注意保存和复制相关作业。
创建作业的操作步骤如下:
- 在“产品服务>MapReduce>MapReduce-作业列表”页中,点击“创建作业”,进入创建作业页。
-
请在创建作业页选择作业类型并配置作业类型对应的参数。以下列举了所有作业类型对应参数配置说明:
-
Streaming作业
- 作业名称:输入作业名称,长度不可超过255个字符。
- Mapper:Mapper是负责把您输入的作业分解成多个作业,对作业进行处理。Mapper对应的输入地址是应用程序在BOS中的地址。
- Reducer:Reducer是负责把分解后多任务处理的结果汇总起来。Reducer对应的输入地址是应用程序在BOS中的地址。
- bos输入地址:这个地址必须已经存在,并且您有权限读取这个地址的文件。
- bos输出地址:写入的bucket之后的地址必须是不存在的,但您有权限对这个地址进行写操作,否则作业运行会失败。
- 失败后操作:选择作业运行失败后的操作:继续(作业执行失败后,继续执行下一个作业)和等待(作业执行失败后,查看作业运行的状态,并且取消后续作业)。
- 应用程序参数:除了以上五种streaming program作业必须输入的参数外,若您还有其他参数的设置,请在参数输入框中以空格为分隔符输入参数配置。用户输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。
-
Java作业
- 作业名称:输入作业名称,长度不可超过255个字符。
- 应用程序位置:输入JAR包在bos上的地址。
- 失败后操作:选择作业运行失败后的操作:继续(作业执行失败后,继续执行下一个作业)和等待(作业执行失败后,查看作业运行的状态,并且取消后续作业)。
- MainClass:写入org.apache.MyClass指定主程序的类名。
- 应用程序参数:输入参数,且参数不做任何修改传给MainClass中的main函数。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。
-
Spark作业
- 作业名称:输入作业名称,长度不可超过255个字符。
- 应用程序位置:输入JAR包在bos上的地址。
- 失败后操作:选择作业运行失败后的操作:继续(作业执行失败后,继续执行下一个作业)和等待(作业执行失败后,查看作业运行的状态,并且取消后续作业)。
-
Spark-submit:Spark的系统参数,Spark在判定Spark-submit输入时遵循如下规则:
- 当对以下的参数进行多次设置时,只有最后一次设置才会生效:--name、--driver-memory、--driver-java-options、--driver-library-path、--driver-class-path、--executor-memory、--executor-cores、--queue、--num-executors、--properties-file、--jars、--files、--archives。
- 不可以指定的参数有:--master、--deploy-mode、--py-files、--driver-cores、--total-executor-cores、--supervise、--help。对于不可以指定的参数,若指定了不会生效。
- 输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。
- 应用程序参数:输入自定义参数。
-
Pig作业
- 作业名称:输入作业名称,长度不可超过255个字符。
- bos脚本地址:bos的脚本地址必须是一个有效的bos路径,并且指向Hive脚本。
- bos输入地址:这个地址必须已经存在,并且您有权限读取这个地址的文件。可在脚本中通过${INPUT}引用这个地址。
- bos输出地址:写入的bucket之后的地址必须是不存在的,但您有权限对这个地址进行写操作,否则作业运行会失败。可在脚本中通过${OUTPUT}引用这个地址。
- 失败后操作:选择作业运行失败后的操作:继续(作业执行失败后,继续执行下一个作业)和等待(作业执行失败后,查看作业运行的状态,并且取消后续作业)。
- 应用程序参数:输入以下指定的参数进行相关的配置:-D key=value指定配置,-p KEY=VALUE指定变量,也可加入自定义参数。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。
-
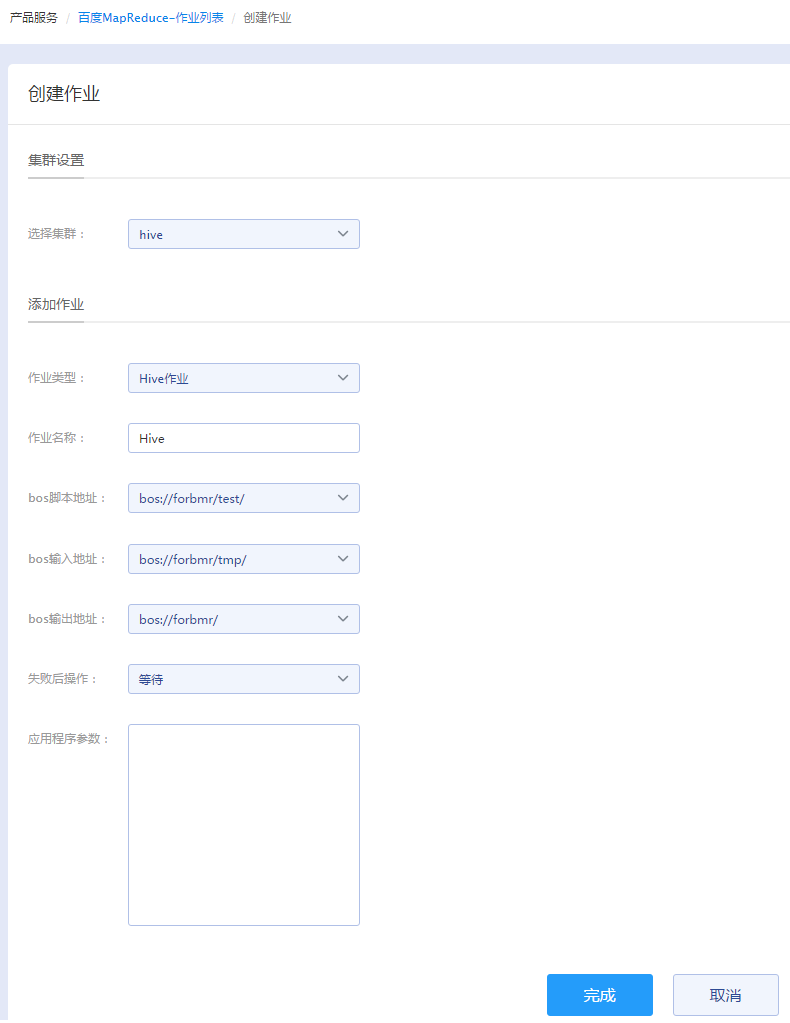
Hive作业
- 作业名称:输入作业名称,长度不可超过255个字符。
- bos脚本地址:BOS的脚本地址必须是一个有效的BOS路径,并且指向Hive脚本。
- bos输入地址:这个地址必须已经存在,并且您有权限读取这个地址的文件。可在脚本中通过${INPUT}引用这个地址。
- bos输出地址:写入的bucket之后的地址必须是不存在的,但您有权限对这个地址进行写操作,否则作业运行会失败。可在脚本中通过${OUTPUT}引用这个地址。
- 失败后操作:选择作业运行失败后的操作:继续(作业执行失败后,继续执行下一个作业)和等待(作业执行失败后,查看作业运行的状态,并且取消后续作业)。
- 应用程序参数:只接受两种参数类型,分别是--hiveconf key=value 和 --hivevar key=value。前一种参数是用来覆盖hive执行时的配置。后一种参数是用来声明自定义的变量,可以在脚本中通过${KEY}来引用。输入参数时,只需要输入参数本身字符串即可,用空格分隔,无需参数转义和url encode。
-
- 选择适配的集群。
-
点击“完成”,则作业创建完成。
- 当作业状态会由“等待中”更新为“运行中”状态,作业运行完毕后状态更新为“已完成”。
- (可选)只有等待中或运行中的作业可被取消,点击“取消作业”即可。
使用远程文件
如果您的作业参数需要依赖本地文件,可以选择使用“附加文件”功能,将远程文件映射到本地路径,即可直接使用远程文件。例如hadoop中的-libjars参数只支持本地文件,通过添加附加文件参数就可以让-libjars使用BOS上的文件,您只需将文件上传至BOS,Hadoop作业即可读取到文件。
需要注意的是,在应用程序参数中使用的文件名需要和本地文件路径设置的文件名保持一致。例如,附加文件:远程文件路径bos://path/to/testA.jar,本地文件路径testB.jar,应用程序参数-libjars testB.jar。
- 操作步骤:
在创建作业页面,填写“附加文件”中的“远程路径”和“本地路径”;“远程路径”对应的是BOS上的文件路径,“本地路径”对应的是作业参数中需要使用的文件名。

- 查看详情:
作业详情页面的“运行参数”中显示有附加文件的远程路径和本地路径。
集群详情中的作业列表也有附加文件的信息。
- 注意 定时任务的作业中添加附加文件,步骤与上述一致。