
部署满血版DeepSeek-R1模型SGlangServer(单机&多机部署&参数建议)
概览
本篇介绍如何在GPU云服务器部署671B参数的DeepSeek R1模型推理服务,部署方式为在GPU云服务器下载SGlang容器环境并在容器中构建SGlang Server,可通过单机GPU实例部署以及两机GPU实例部署。同时分享SGlang Server的部署参数建议,您可根据业务需求按需选择。
单机部署SGlang AIAK版服务
通过百度智能云优化版SGlang AIAK镜像可获取更高的性能,使用方式如下:
创建实例并配置环境
1、开通GPU云服务器,GPU建议选择显存容量141G及以上的型号,建议选择535及以上驱动版本:
2、安装docker环境,您可通过云助手的公共命令安装docker或者登陆实例后执行以下脚本安装:
1curl -sL http://mirrors.baidubce.com/nvidia-binary-driver/scripts/gpu_docker.sh | bash -3、(可选)初始化数据盘,因模型容量较大,建议将模型保存在数据盘中,如您购买的实例包含本地盘,可通过云助手公共命令实现本地盘初始化及挂载,示例参数如下:

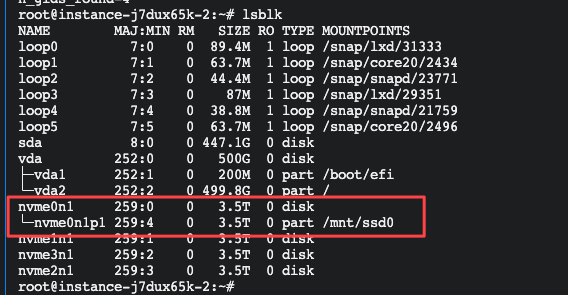
执行后可查看挂载结果:
下载模型及相关数据
建议您下载BOS对象存储CLI工具并从云内网下载模型。
1、安装BOS CLI工具:
下载BOS CLI:https://cloud.baidu.com/doc/BOS/s/Ejwvyqobd 到实例,并执行以下命令
1# 解压并添加链接
2unzip linux-bcecmd-0.5.1.zip #BOS CLI工具定期更新 替换为最新版的名称
3ln -s `pwd`/linux-bcecmd-0.5.1/bcecmd /usr/bin/ #BOS CLI工具定期更新 替换为最新版的名称2、下载模型、镜像及测试数据集,文件保存在/mnt/ssd0中,可按需替换为其他目录:
目前aiak-sglang白名单开放,有需求请提交工单
1* 配置AK/SK,配置的AKSK需要有bosfullcontrolaccess IAM权限,其余参数可通过回车跳过
2bcecmd -c
3* 下载aiak-sglang镜像
4bcecmd bos cp bos://baidu-ai-cloud-iaas-bcc-bj/ai/private_docker/aiak-sglang-v0.4.4-v1.1.tar /mnt/ssd0/images/
5* DeepSeek - R1 模型
6bcecmd bos sync bos://baidu-ai-cloud-iaas-bcc-bj/ai/model/DeepSeek-R1 /mnt/ssd0/model/DeepSeek-R1
7* MTP使能依赖的小模型
8bcecmd bos sync bos://baidu-ai-cloud-iaas-bcc-bj/ai/model/DeepSeek-R1-NextN /mnt/ssd0/model/DeepSeek-R1-NextN
9* 测试数据集:
10bcecmd bos cp bos://baidu-ai-cloud-iaas-bcc-bj/ai/dataset/ShareGPT_V3_unfiltered_cleaned_split.json /mnt/ssd0/dataset/ShareGPT_V3_unfiltered_cleaned_split.json启动Server服务
1、加载容器镜像:
1docker load -i /mnt/ssd0/images/aiak-sglang-v0.4.4-v1.1.tar2、启动docker: 如您创建的GPU云服务器是裸金属形态,可执行以下命令:
1docker run --gpus all -itd --name aiak-sglang --shm-size=32g --privileged --user=root -v /mnt/ssd0/:/mnt/ssd0/ aiak-sglang-v0.4.4:v1.1 /bin/bash如您创建的GPU云服务器是虚拟机形态,则需要将实例中的NCCL拓扑文件挂载到容器内,启动命令更新如下“
1docker run --gpus all -itd --name aiak-sglang --shm-size=32g --privileged --user=root -v /mnt/ssd0/:/mnt/ssd0/ -v /var/run/nvidia-topologyd/virtualTopology.xml:/var/run/nvidia-topologyd/virtualTopology.xml aiak-sglang-v0.4.4:v1.1 /bin/bash3、登陆docker:
1docker exec -it aiak-sglang bash4、通过如下脚本启动SGlang server,因开启pytorch compile, 启动耗时较长,需要等待半小时左右,如您的环境需要更快的启动速度,可关闭此参数:
1export USE_CUDA_ROPE=0
2export USE_FUSED_INPUT_TO_FP8=1
3export ENABLE_SELECT_EXPERTS=1
4export SGL_ENABLE_JIT_DEEPGEMM=1
5R1_MODEL_PATH=/mnt/ssd0/model/DeepSeek-R1 #更改为实际路径
6NextN_MODEL_PATH=/mnt/ssd0/model/DeepSeek-R1-NextN #更改为实际路径
7TP=8
8PORT=8000
9max_running_requests=32 #s控制server支持的最大并发数,数字越大编译所需时间越久
10
11python3 -m sglang.launch_server --model-path $R1_MODEL_PATH --tp $TP --trust-remote-code --port $PORT --host 0.0.0.0 --mem-fraction-static 0.90 --max-running-requests $max_running_requests --enable-flashinfer-mla --enable-torch-compile --enable-flashinfer-mla --speculative-algorithm NEXTN --speculative-draft $NextN_MODEL_PATH --speculative-num-steps 2 --speculative-eagle-topk 1 --speculative-num-draft-tokens 25、Server显示 The server is fired up and ready to roll!,表示 server 已达到运行中状态,可开启一个新的终端并重复上述步骤3 登陆容器内做性能测试,建议通过以下命令和脚本执行性能测试,
1bash test_benchmark.sh > test_benchmark.log 2>&1 & 如下脚本会依次测试1、4、8、16并发下的性能,如需测试更高并发,请更改max_concurrency。 test_benchmark.sh:
1#!/bin/bash
2
3set -e
4
5IC_IP=$(hostname -i)
6PORT=8000
7
8DATASET_PATH='/mnt/ssd0/dataset/ShareGPT_V3_unfiltered_cleaned_split.json'
9MODEL_PATH='/mnt/ssd0/model/'
10MODEL='DeepSeek-R1/'
11LOG_PATH='logs/'
12
13function run_bench() {
14 for i in "${max_concurrency[@]}"; do
15 num_prompts+=($((i * $MULTIPLE)))
16 done
17
18 # warm up
19 aiakperf -if $INPUT_LEN -of $OUTPUT_LEN -m ${MODEL_PATH}${MODEL} -r openai -d raw_sharegpt -D ${DATASET_PATH} -a $IC_IP:8000 -n 16 -w 16 -M ds-test-model -igr False -o ${LOG_PATH}
20 sleep 5
21
22 for i in "${!max_concurrency[@]}"; do
23 CONCURRENCY=${max_concurrency[$i]}
24 PROMPTS=${num_prompts[$i]}
25
26 echo "Running benchmark with concurrency $CONCURRENCY, prompts $PROMPTS"
27
28 aiakperf -if $INPUT_LEN -of $OUTPUT_LEN -m ${MODEL_PATH}${MODEL} -r openai -d raw_sharegpt -D ${DATASET_PATH} -a $IC_IP:8000 -n $PROMPTS -w $CONCURRENCY -M ds-test-model -igr False -o ${LOG_PATH} > ${LOG_PATH}${INPUT_LEN}_${OUTPUT_LEN}_${CONCURRENCY}_`date +%s`
29 sleep 5
30
31 done
32}
33
34# 3.5kinput / 1.5koutput
35INPUT_LEN=3500
36OUTPUT_LEN=1500
37MULTIPLE=10
38declare -a max_concurrency=(1 4 8 16)
39declare -a num_prompts=()
40run_bench单机部署SGlang 社区版服务
创建实例并配置环境
1、开通GPU云服务器,GPU建议选择显存容量96G及以上的型号,建议选择如下的GPU环境:

2、安装docker环境,您可通过云助手的公共命令安装docker或者登陆实例后执行以下脚本安装:
1curl -sL http://mirrors.baidubce.com/nvidia-binary-driver/scripts/gpu_docker.sh | bash -3、(可选)初始化数据盘,因模型容量较大,建议将模型保存在数据盘中,如您购买的实例包含本地盘,可通过云助手公共命令实现本地盘初始化及挂载,示例参数如下:
执行后可查看挂载结果:
下载模型及相关数据
建议您下载BOS对象存储CLI工具并从云内网下载模型。
1、安装BOS CLI工具:
1# 下载bcecmd程序
2wget http://mirrors.baidubce.com/nvidia-binary-driver/scripts/linux-bcecmd-0.3.9.zip
3# 解压
4unzip linux-bcecmd-0.3.9.zip
5ln -s `pwd`/linux-bcecmd-0.3.9/bcecmd /usr/bin/2、下载模型、镜像及测试数据集,文件保存在/mnt/ssd0中,可按需替换为其他目录:
1* 下载sglang镜像
2bcecmd bos cp bos://baidu-ai-cloud-iaas-bcc-bj/ai/docker/sglang_v0.4.3.post2-cu124.tar /mnt/ssd0/images/sglang_v0.4.3.post2-cu124.tar
3* DeepSeek - R1 模型
4bcecmd bos sync bos://baidu-ai-cloud-iaas-bcc-bj/ai/model/DeepSeek-R1 /mnt/ssd0/model/DeepSeek-R1
5* 测试数据集:
6bcecmd bos cp bos://baidu-ai-cloud-iaas-bcc-bj/ai/dataset/ShareGPT_V3_unfiltered_cleaned_split.json /mnt/ssd0/dataset/ShareGPT_V3_unfiltered_cleaned_split.json启动Server服务
1、加载容器镜像:
1docker load -i /mnt/ssd0/images/sglang_v0.4.3.post2-cu124.tar2、启动docker: 如您创建的GPU云服务器是裸金属形态,可执行以下命令:
1docker run --gpus all -itd --name sglang_deepseek --shm-size=32g --privileged --user=root --network=host -v /mnt/ssd0/:/workspace/ lmsysorg/sglang:v0.4.3.post2-cu124 /bin/bash如您创建的GPU云服务器是虚拟机形态,则需要将实例中的NCCL拓扑文件挂载到容器内,启动命令更新如下“
1docker run --gpus all -itd --name sglang_deepseek --shm-size=32g --privileged --user=root --network=host -v /mnt/ssd0/:/workspace/ -v /var/run/nvidia-topologyd/virtualTopology.xml:/var/run/nvidia-topologyd/virtualTopology.xml lmsysorg/sglang:v0.4.3.post2-cu124 /bin/bash3、登陆docker:
1docker exec -it sglang_deepseek bash4、启动Sglang server:
1python3 -m sglang.launch_server --model-path /workspace/model/DeepSeek-R1/ --port 30000 --mem-fraction-static 0.9 --tp 8 --trust-remote-codeSGlang的启动参数建议:
| 参数名称 | 参数功能 | 使用建议 |
|---|---|---|
| --mem-fraction-static | 控制 sglang 初始化静态显存占用量系数,包含模型及kvcache占用,默认值0.8 | 建议调高--mem-fraction-static 保证有足够的显存支持kvcache或者更高性能,如遇到运行时cuda graph 初始化和 pytorch 运行时OOM报错,则调低该参数确保能正常运行 |
| --enable-dp-attention | 使能attention数据并行 | dp-attention 能够节省kvcache 1. 注重并发场景建议开启 dp attention 来提升吞吐 token throughput 。2. 注重延时场景建议关闭 dp atttention 来降低首 token 延时 TTFT。 当前仅建议单机部署开启该参数。 |
5、测试服务,server启动后,可在该GPU实例打开新的终端,通过如下命令测试:
1curl http://localhost:30000/generate \
2 -H "Content-Type: application/json" \
3 -d '{
4 "text": "什么是deepseek r1?",
5 "sampling_params": {
6 "temperature": 0.3,
7 "repetition_penalty": 1.2,
8 "stop_token_ids": [7]
9 }
10}'
双机部署社区版SGlang服务
如您的业务需要Server支持更高的并发量,可通过双机部署Server提高性能,本实践介绍TP=16的双机部署方案。
1、创建2台同规格的GPU云服务器,并按照如上单机部署服务直男,完成启动server前的所有操作。
2、登陆2台实例并加载docker镜像:
1docker load -i /mnt/ssd0/images/sglang_v0.4.3.post2-cu124.tar3、在2台实例启动docker:
1docker run --gpus all -itd --name sglang_deepseek --shm-size=32g --privileged --user=root --network=host -v /mnt/ssd0/:/workspace/ lmsysorg/sglang:v0.4.3.post2-cu124 /bin/bash3、登陆2台实例的docker:
1docker exec -it sglang_deepseek bash4、在2台实例docker中设置NCCL环境变量:
1export NCCL_SOCKET_IFNAME=eth0
2export NCCL_IB_GID_INDEX=3
3export NCCL_IB_TIMEOUT=22
4export NCCL_IB_RETRY_CNT=7
5export NCCL_IB_QPS_PER_CONNECTION=8
6export NCCL_DEBUG=INFO4、在2台实例docker中分别执行以下命令,注意确保2台实例所在的安全组已放开20000端口,dist-init-addr替换为主节点私有网络IP地址:
1#主节点:
2python3 -m sglang.launch_server --model-path /workspace/model/DeepSeek-R1/ --tp 16 --dist-init-addr 192.168.0.6:20000 --nnodes 2 --node-rank 0 --trust-remote-code --host 0.0.0.0 --port 30000
3
4#从节点:
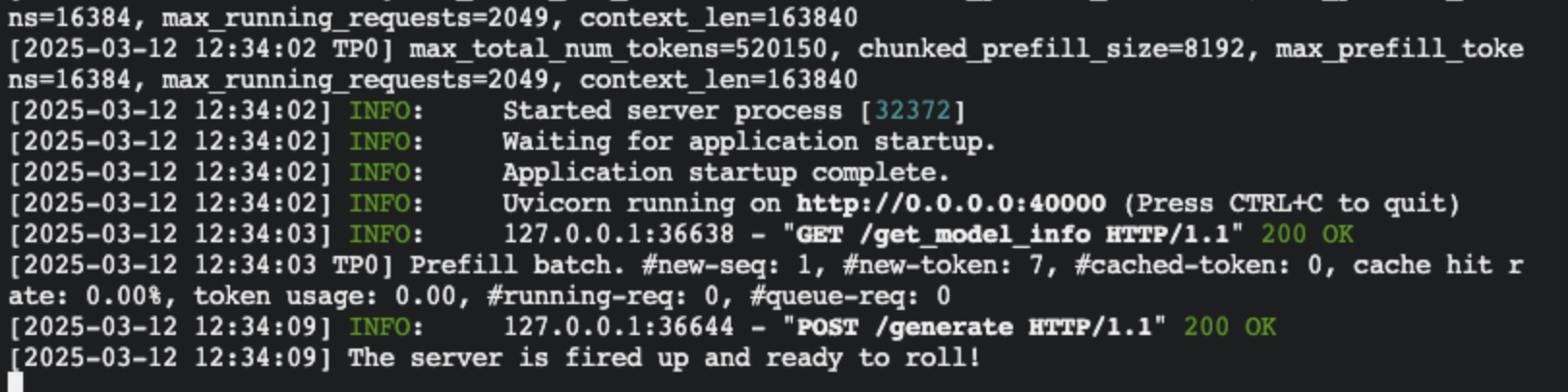
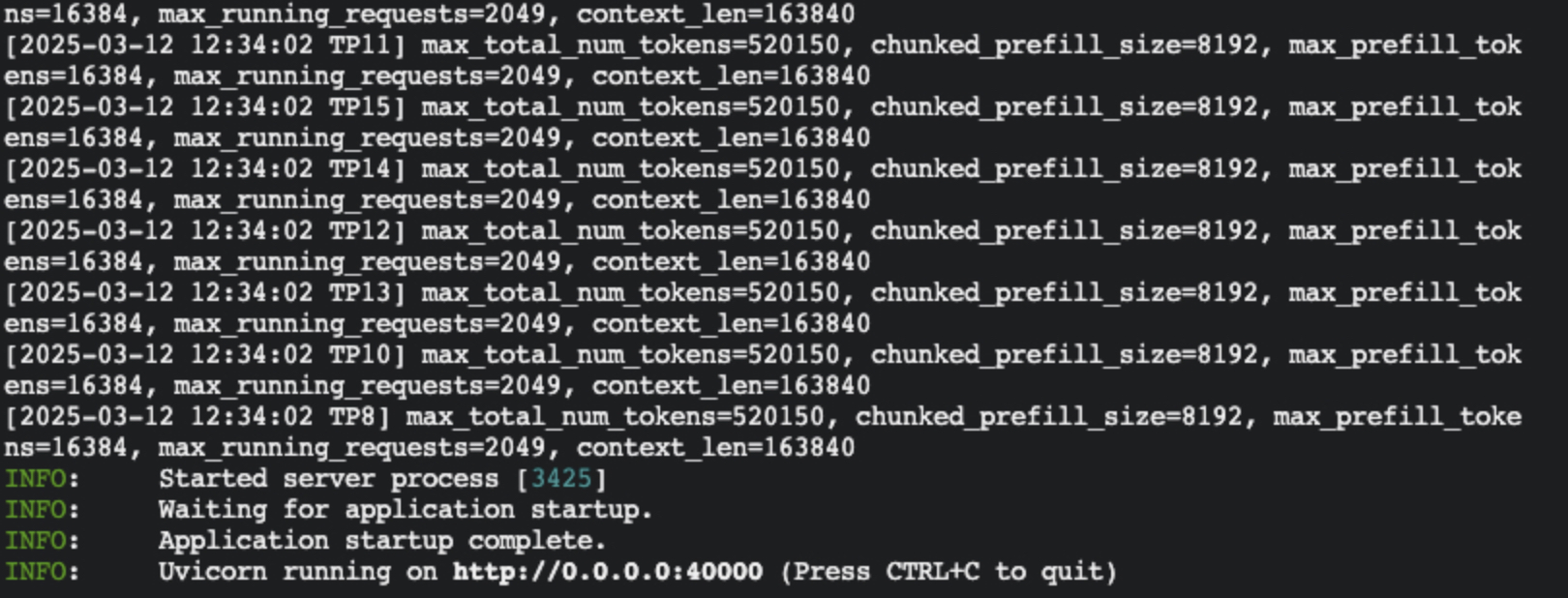
5python3 -m sglang.launch_server --model-path /workspace/model/DeepSeek-R1/ --tp 16 --dist-init-addr 192.168.0.6:20000 --nnodes 2 --node-rank 1 --trust-remote-code --host 0.0.0.0 --port 30000 如看到以下打印,则代表server已正常工作。
5、测试server方法同单机部署。
常见Q&A
1、如在启动sglang server过程中遇到Fatal Python error: Segmentation fault错误,可尝试升级容器中NCCL版本解决,升级命令如下:
1pip install nvidia-nccl-cu12==2.25.1 -i http://mirrors.baidubce.com/pypi/simple --trusted-host=mirrors.baidubce.com