
如何检测GPU常见故障
在GPU云服务器使用过程中可能会出现GPU硬件故障或者亚健康状态,如果您发现应用程序出现报错或者GPU硬件性能下降,可通过以下检测方法检测是否存在故障,发现故障后,可通过重启实例或者重置GPU卡等方式修复,如果问题持续发生,请您提交工单。
掉卡故障检测
您可依次通过以下几种检测方法,判断当前实例是否存在GPU掉卡故障。
方法一:检测GPU掉卡数量
检测步骤
- 登录实例。
- 执行命令:
1lspci -d 10de:|grep "rev ff"- 若结果不为空,则表示有掉卡问题;结果的行数表示掉卡的个数。
解决方法
- 登录控制台重启实例。
- 如果重启无法恢复,请提交工单。
方法二:检测GPU数量
检测步骤
- 登录实例。
- 执行命令:
1lspci -d 10de:|grep -v 1af1- 查看GPU卡数量是否和预期相符。
解决方法
请提交工单。
方法三:检测驱动是否能识别到卡
检测步骤和解决方法见如何采用Xid方法检测故障问题
方法四:驱动冲突检测
检测步骤
- 登录实例。
- 执行命令:
1lsmod |grep nouveau- 结果中包含nouveau,如下图。
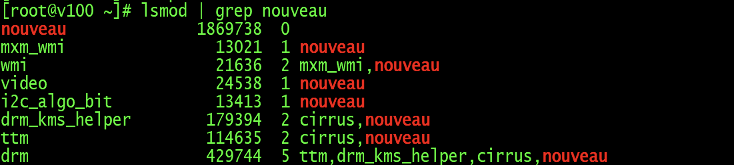
解决方法
参考文档,禁用nouveau模块https://cloud.baidu.com/doc/GPU/s/0kqm6s30y
链路故障检测
您可依次通过以下几种检测方法,判断当前实例是否存在链路故障。
方法一:检测fabricmanager是否启动
检测步骤
- 登录实例。(适用实例:EHC GN5 A100/A800,BCC GN5 A100-40G)
- 执行命令:
1systemctl status nvidia-fabricmanager- 检查结果,fabricmanager未启动为异常状态,下图为正常状态。
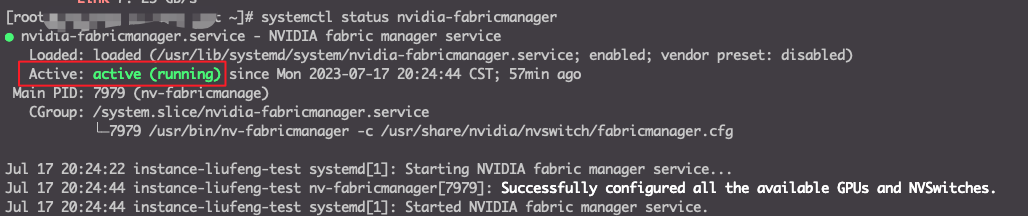
解决方法
请提交工单。
方法二:Nvlink驱动故障检测
检测步骤和解决方法见如何采用Xid方法检测故障问题
内存故障检测
您可根据GPU实例的架构类型(通用架构、ampere架构、其他架构),采用不同的检测方法,判断当前实例是否存在内存故障。
通用架构
适用于所有GPU实例规格族,您可通过以下检测方法,判断当前实例是否存在链路故障。
检测ECC MODE是否开启
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi -q | grep EC- ECC模式已开启则显示"Current ECC Mode : Enabled",未开启则显示"Current ECC Mode : Disabled"。
解决方法
- 登录实例。
- 执行命令:
1nvidia-smi -i [GPU的ID] -e 1其中[GPU的ID]是您未开启ECC模式的GPU的编号,比如0,1,2等。
ampere架构
适用于GN5型A100、A800和A10 GPU实例规格族,您可依次通过以下几种检测方法,判断当前实例是否存在内存故障。
方法一:检测是否出现显存重映射失败
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi -q|grep "Remapping Failure Occurred .+?Yes"- 命令有输出结果,如下图。

解决方法
请提交工单。
方法二:检测是否出现显存重映射阻塞
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi -q|grep -P "Pending .+?Yes"- 命令有输出,如下图。

解决方法
登录控制台,对异常节点进行重启。
方法三:检测显存重映射是否超过阈值
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi -q|grep -P "(Low|None) .+?[0-9]+ bank"|grep -v "0 bank"- 命令有输出,如下图。

解决方法
请提交工单。
方法四:检测不可恢复SRAM的值
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi --query-gpu=ecc.errors.uncorrected.volatile.sram --format=csv -i ${bus_id}- 命令输出结果非0。
解决方法
请提交工单。
方法五:检测是否出现ECC错误
检测步骤和解决方法见如何采用Xid方法检测故障问题
其他架构
适用于GN1型P4,GN3型V100和T4 GPU实例规格族,您可依次通过以下几种检测方法,判断当前实例是否存在内存故障。
方法一:检测Single Bit ECC
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi --query-gpu=retired_pages.single_bit_ecc.count --format=csv- 结果之和>60。
解决方法
请提交工单。
方法二:检测Double Bit ECC
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi --query-gpu=retired_pages.double_bit.count --format=csv- 结果之和>5。
解决方法
请提交工单。
方法三:检测不可恢复的Cache的值
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi --query-gpu=ecc.errors.uncorrected.aggregate.l1_cache,ecc.errors.uncorrected.aggregate.l2_cache,ecc.errors.uncorrected.aggregate.register_file --format=csv- 返回的结果任意一行,和值大于5(每一行表示一张GPU卡的结果值)。

解决方法
请提交工单。
方法四:检测是否出现ECC错误
检测步骤和解决方法见如何采用Xid方法检测故障问题
其他硬件故障检测
您可依次检测以下几项,判断当前实例是否存在其他硬件故障。
GPU温度检测
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi --query-gpu=temperature.gpu --format=csv- 结果中任意一行的值大于85(每一行表示一个GPU卡的温度)。
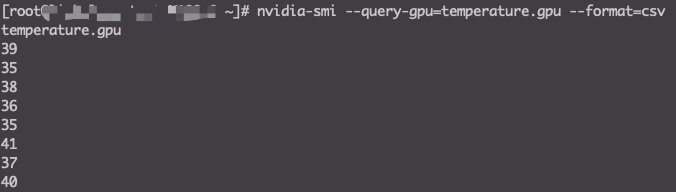
解决方法
请提交工单。
GPU功耗检测
检测步骤
- 登录实例。
- 执行命令:
1nvidia-smi- 存在某张卡的功率一栏是Unknown或者err。
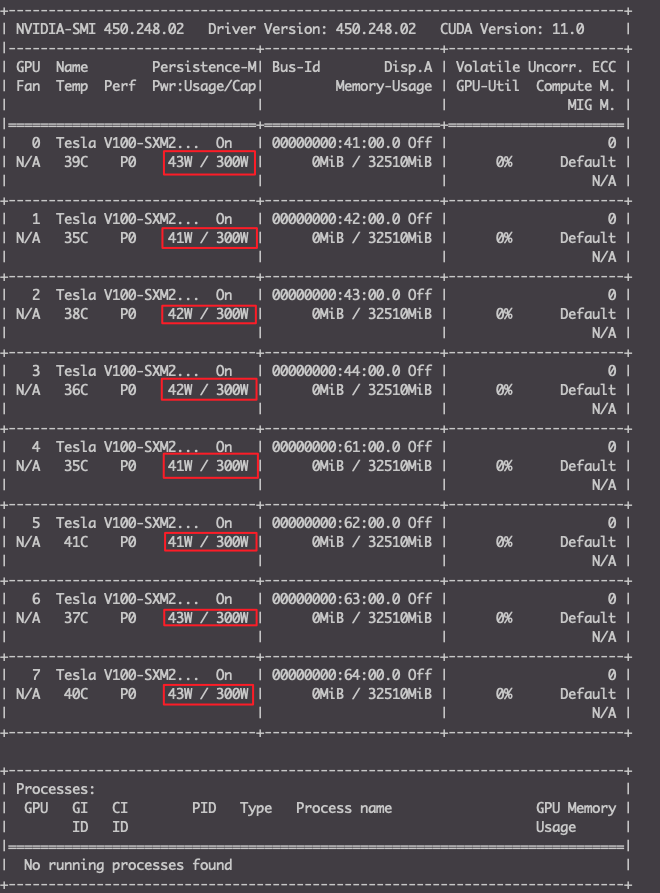
解决方法
- 登录控制台重启实例。
- 如果重启无法恢复,请提交工单。
如何采用Xid方法检测故障问题
检测步骤
- 登录实例。
-
执行命令。
- centos:
Plain Text1dmesg -T |grep Xid- ubuntu:
Plain Text1journalctl --since `date -d "10 days ago" "+%Y-%m-%d"`|grep Xid - 查看结果。
结果中包含Xid 79,如下图,则存在GPU掉卡故障。

结果中包含Xid 74,如下图,则存在GPU链路故障。

结果中包含Xid 48/63/94/95,如下图,则存在内存故障。


解决方法
- 登录控制台重启实例。
- 如果重启无法恢复,请提交工单。