Use the BSC to Import the Kafka Data to the Es
Introduction
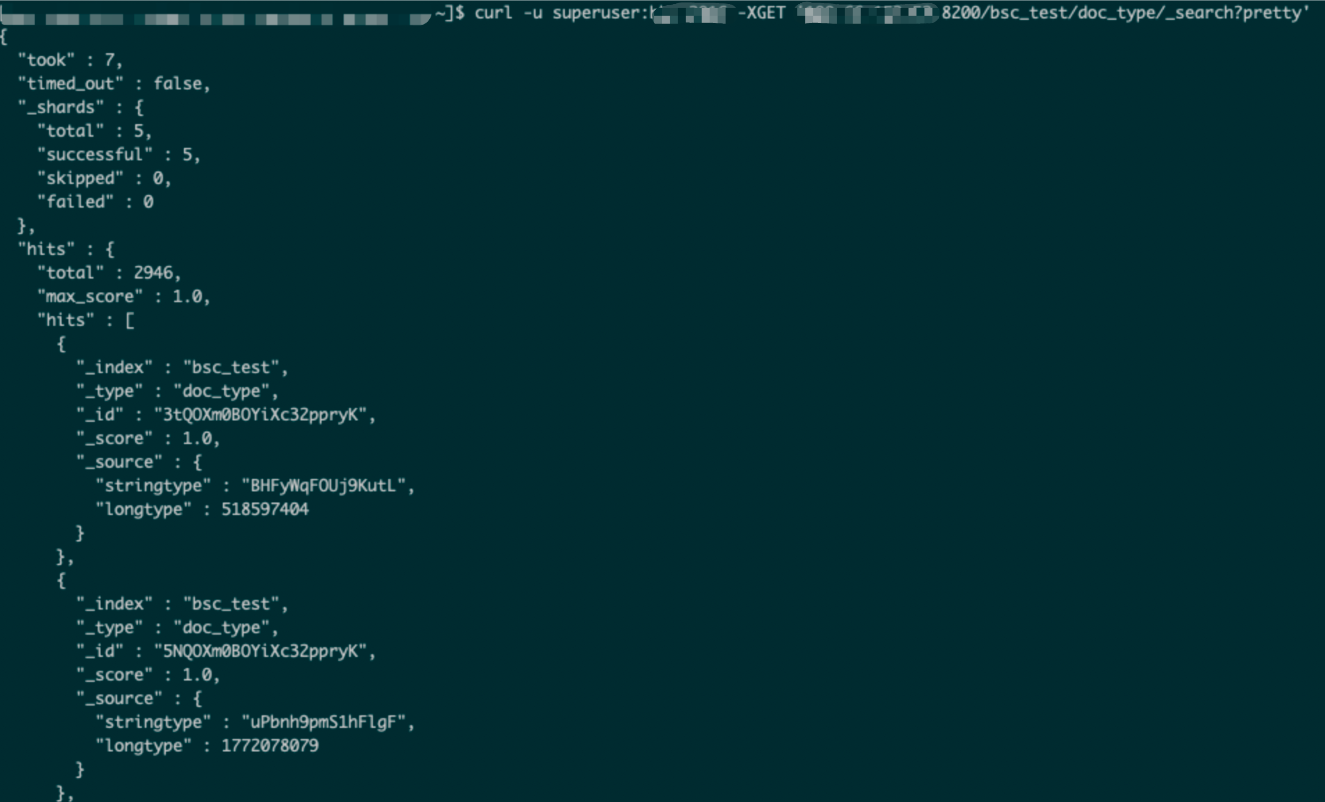
This document mainly introduces how to import the data from "Kafka" to "Es" through the BSC 【Baidu Streaming Computing Service】.
Create a Cluster
Before importing the data into the "Es", you need to create an "Es" cluster on the Baidu Cloud. Assume the created cluster information is as follows:
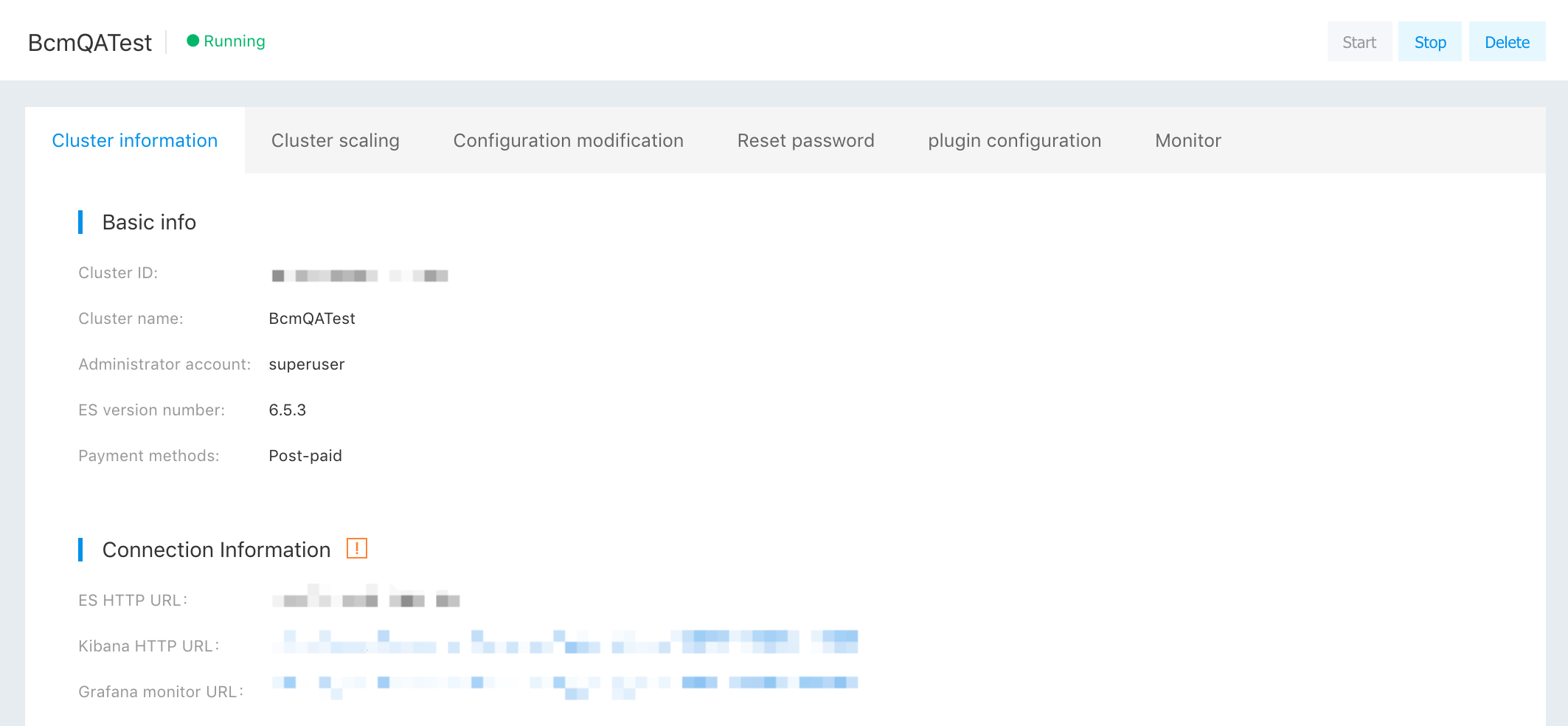
Here, record the following information:
- Cluster ID: 296245916518715392
- Password set during cluster creation: bbs_2016
Create Kafka Topic
Log in to Baidu AI Cloud management console, enter the kafka product interface, create a topic, and inject the data into the created topic. In the example, the injected data is as follows, which includes two json fields. The sample data is as follows:
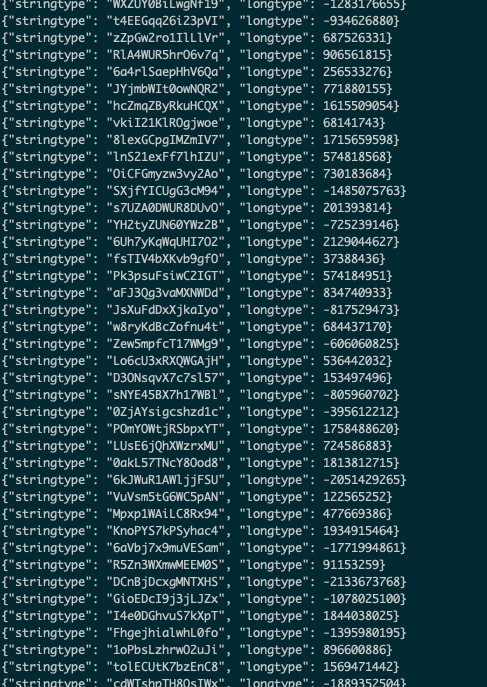
In the example, create a topic: a15fdd9dd5154845b32f7c74ae155ae3__demo_test, and ensure there's a corresponding certificate under this "topic". Then, download the certificate to the local device.
Edit BSC Job
Create a Kafka Source
Enter the BSC edit job interface and create "kafka source table". The "sql" code is as follows:
CREATE table source_table_kafka(
stringtype STRING,
longtype LONG
) with(
type = 'BKAFKA',
topic = 'a15fdd9dd5154845b32f7c74ae155ae3__demo_test',
kafka.bootstrap.servers = 'kafka.bj.baidubce.com:9091',
sslFilePath = 'kafka_key.zip',
encode = 'json'
);Where, "sslFilePath" = 'kafka-key.zip', which is the "kafka" certificate downloaded to the local device at the previous step.
Upload a Kafka Certificate
Click "Advanced Setting", and upload the "kafka" certificate.
After uploading, display the following figure.
Create Es Sink Table
The "sql" code is as follows:
create table sink_table_es(
stringtype String,
longtype Long
)with(
type = 'ES',
es.net.http.auth.user = 'superuser',
es.net.http.auth.pass = 'bbs_2016',
es.resource = 'bsc_test/doc_type',
es.clusterId = '296245916518715392',
es.region = 'bd',
es.port = '8200',
es.version = '6.5.3'
);Where:
- "Es.resource" corresponds to the index and type of "es". "Es" automatically creates the specified index when "bsc" writes data.
- “Es.clusterId” corresponds to the cluster "ID" of "es".
- “Es.region” indicates the code of the region for "Es" service. You can refer to the "Es" service region code to query the correspondence between the region and code.
Edit Import Statement
The "sql" statement is as follows:
insert into
sink_table_es(stringtype, longtype) outputmode append
select
stringtype,
longtype
from
source_table_kafka;
Save a job, and release and run it
View the Data in the Es