
百度NLP中文分词词典动态更新
更新时间:2025-08-20
百度智能云Elasticsearch的NLP中文分词插件支持用户添加自定义词典干预NLP模型,从而进行分词词典动态热更新。
用户可以根据需求,通过上传词典文件或输入文本两种方式添加自定义词典。
注意:NLP中文分词词典动态更新目前支持功能发布后新创建的7.4.2版本的实例(即2021年01月20日后创建的7.4.2版本的实例),不支持的集群请提交工单,BES团队会协助升级集群,升级方式参见ES版本升级。
使用方式
- 登录百度智能云Elasticsearch控制台,并点击集群名称,进入集群详情界面。
- 在左侧导航栏,单击插件配置。
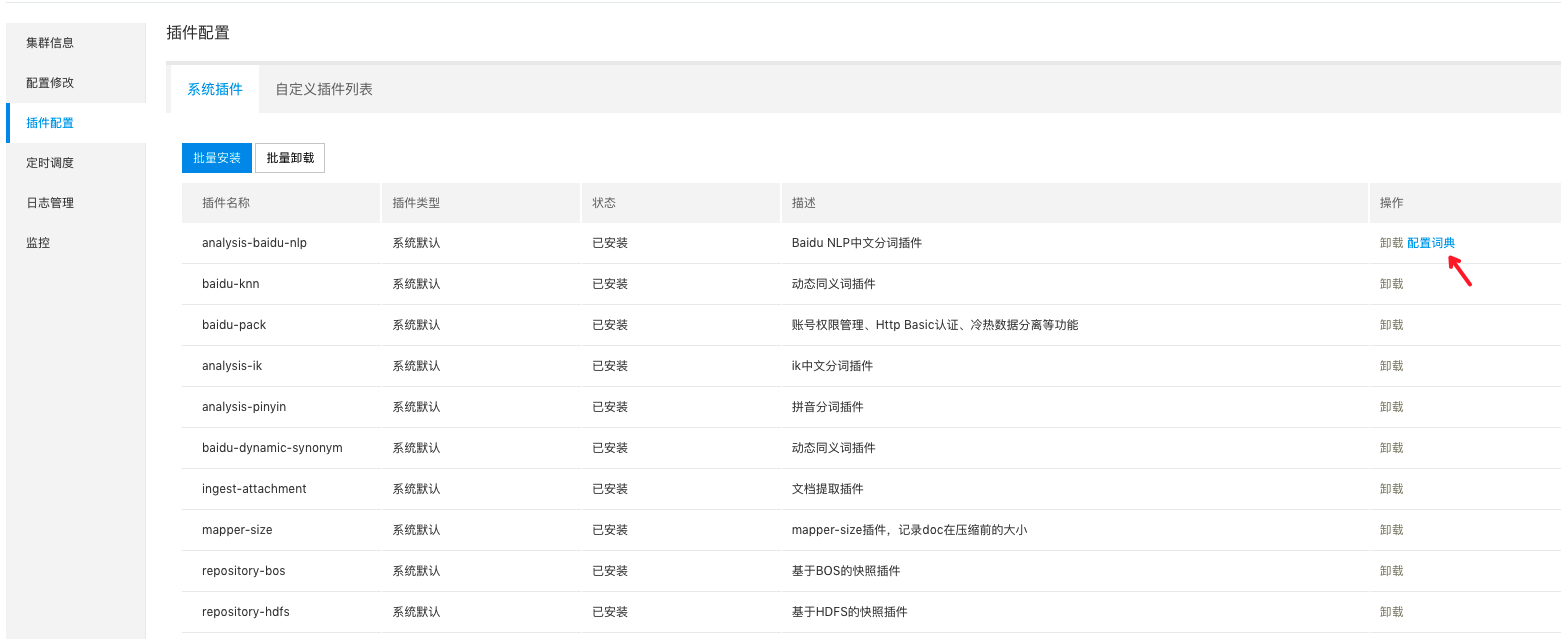
- 点击“配置词典”,在弹出的页面添加自定义词典。用户可以通过上传词典文件或输入文本两种方式添加自定义词典。
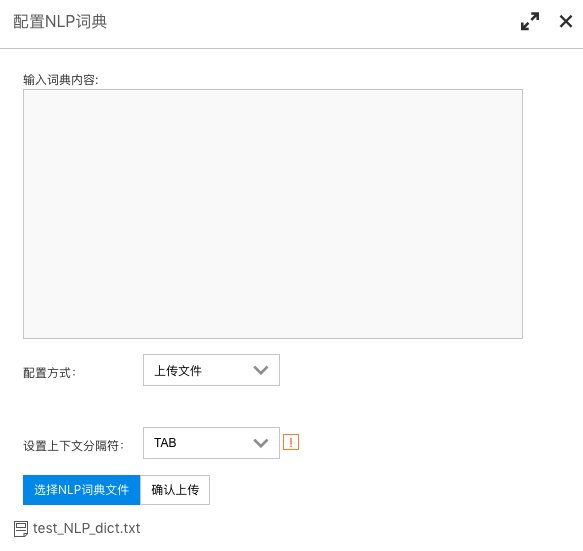
- 通过上传文件的方式:
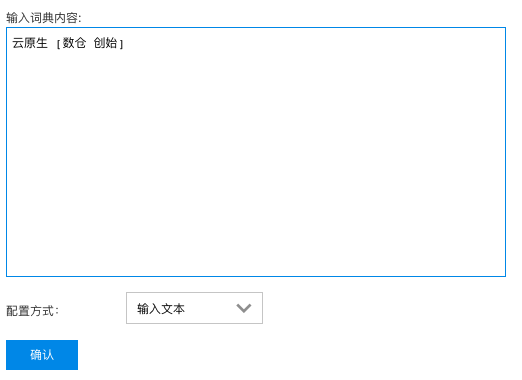
- 通过直接输入文本的方式:
- 上传成功后,即完成词典更新,可以使用以下语句测试自定义词典的效果。
Plain Text
1POST /_analyze
2{
3 "analyzer": "bd-nlp-basic",
4 "text": "测试语句"
5}自定义词典
词典格式说明
- 干预规则按行分割(
\n)。 - 上传词典文件时,可以选择使用空格或使用TAB(
\t)来进行干预规则内的词典分词;直接输入文本的方式则只能使用空格作为分隔符。 - 干预规则内可以使用
[ ]对basic模型和phrase模型同时干预。
干预规则说明
用户可以按照以下格式对自定义词典进行配置:
Plain Text
1中华 人民 共和国
2中华 [人民 共和国]
3中华
4人民
5共和国例如:未进行干预前,bd-nlp-basic(basic模型)和bd-nlp-phrase(phrase模型)对中华人民共和国分词的结果是:
Plain Text
1中华人民共和国干预 basic 模型分词
干预词典:
带上下文关系的干预规则:
Plain Text
1中华 人民 共和国不带上下文关系的干预规则:
Plain Text
1中华
2人民
3共和国干预后两种力度的切词结果一样:
Plain Text
1{
2 "tokens":[
3 {
4 "token":"中华",
5 "position":0
6 },
7 {
8 "token":"人民",
9 "position":1
10 },
11 {
12 "token":"共和国",
13 "position":2
14 }
15 ]
16}注意:
上下文关系表示是不是切出这个词是由这个词的前后词来决定,例如用户如果将干预规则配置为:
Plain Text
1中华 人民 共和国则只会对中华人民共和国进行按照该规则进行分词,而不会对中华人民或人民共和国进行分词;而如果将干预规则配置为:
Plain Text
1中华
2人民
3共和国则可以对中华人民或人民共和国进行分词。
- 干预基础粒度分词,会有一定概率影响phrase粒度分词结果,因为phrase模型是对basic结果进行智能组合,会有无法重组回原粒度切词结果的情况出现
同时干预 basic 模型和 phrase 模型
干预词典规则:
Plain Text
1中华 [人民 共和国]bd-nlp-basic分词结果:
Plain Text
1{
2 "tokens":[
3 {
4 "token":"中华",
5 "position":0
6 },
7 {
8 "token":"人民",
9 "position":1
10 },
11 {
12 "token":"共和国",
13 "position":2
14 }
15 ]
16}bd-nlp-phrase分词结果:
Plain Text
1{
2 "tokens":[
3 {
4 "token":"中华",
5 "position":0
6 },
7 {
8 "token":"人民共和国",
9 "position":1
10 }
11 ]
12}phrase模型会对[]内的词(basic可以分词)重组成一个词。
利用上下文语义进行干预 basic 和 phrase 模型
[]内的词是对phrase模型进行干预,phrase模型会对[]内的词(basic模型可以切出来)智能组合- 没有
[]只会根据上下文语义对basic模型进行干预
干预词典规则:
Plain Text
1云原生 [数仓 创始]原始文本内容:
Plain Text
1云原生数仓创始和数仓创始规则生效前:
basic模型分词结果:
Plain Text
1[云原生, 数, 仓, 创始, 和, 数, 仓, 创始]phrase模型分词结果:
Plain Text
1[云原生, 数, 仓, 创始, 和, 数, 仓, 创始]规则生效后:
Plain Text
1{
2 "tokens":[
3 {
4 "token":"云原生",
5 "position":0
6 },
7 {
8 "token":"数仓",
9 "position":1
10 },
11 {
12 "token":"创始",
13 "position":2
14 },
15 {
16 "token":"和",
17 "position":3
18 },
19 {
20 "token":"数",
21 "position":4
22 },
23 {
24 "token":"仓",
25 "position":5
26 },
27 {
28 "token":"创始",
29 "position":6
30 }
31 ]
32}分词结果为:
Plain Text
1[云原生, 数仓, 创始, 和, 数, 仓, 创始]可以看到文本中第二个的数仓创始,由于不满足上下文关系(该词前面的词不是云原生),所以不会切出数仓。
nlp-bd-phrase分词结果:
Plain Text
1{
2 "tokens":[
3 {
4 "token":"云原生",
5 "position":0
6 },
7 {
8 "token":"数仓创始",
9 "position":1
10 },
11 {
12 "token":"和",
13 "position":2
14 },
15 {
16 "token":"数",
17 "position":3
18 },
19 {
20 "token":"仓",
21 "position":4
22 },
23 {
24 "token":"创始",
25 "position":5
26 }
27 ]
28}切词结果:
Plain Text
1[云原生, 数仓创始, 和, 数, 仓, 创始]可以看到数仓和创始被phrase模型智能组合为数仓创始。
说明: 云原生可以放在干预词典规则的前面和后面, 具体可以根据业务的上下文语义需求。
注意
- 不是所有的干预规则都会成功,会有一个模型匹配的概率问题。
- 上传的文件用UTF-8编码,扩展名为txt。
- 上传的词典文件最大为10M。