表计算
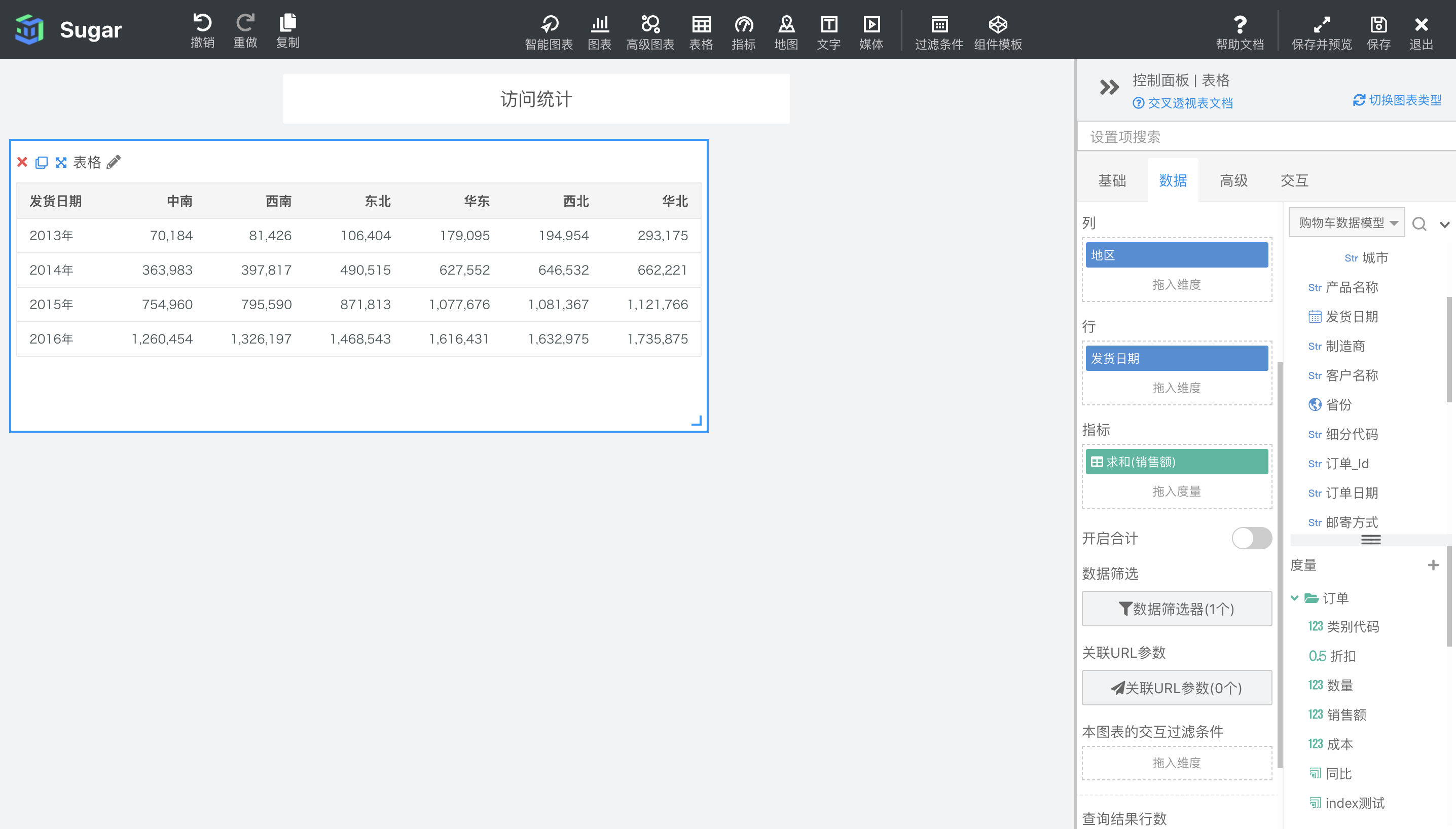
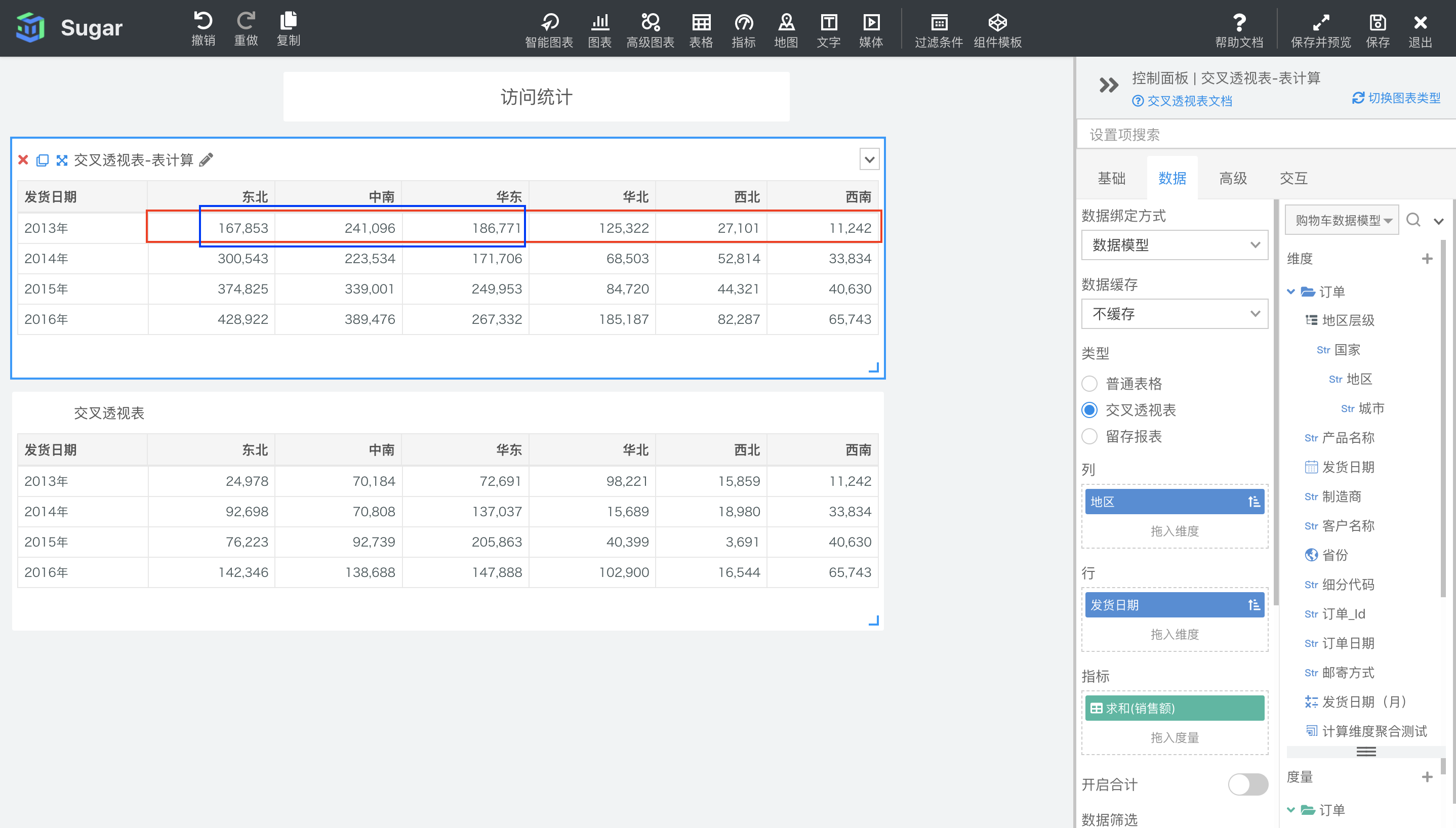
Sugar BI 中的图表除了只能绑定度量或只能绑定维度的图表,都支持表计算。表计算可以对数据模型的查询结果进行二次计算,计算时机在 sql 查询之后。比如我们查询了 2013 年度到 2016 年度各地区的销售额数据汇总,如下图所示。
如果我们想要查看每年各地区销售额的排名情况,就可以简单的通过表计算来实现,不需要写自定义 SQL 在 SQL 中进行计算。在指标区域里的销售额字段上右键,选择快速表计算,选择「排名」即可,如下图所示。
如果我们想查看每年各地区销售额的占比,可以在指标区域里的销售额字段上右键,选择快速表计算,选择「总额百分比」即可,如下图所示。
表计算包括快速表计算和表计算字段,下面将详细阐述这两部分。绝大多数图表都支持表计算,为了方便理解和举例,下面的内容我们都以交叉透视表为例。
快速表计算
快速表计算是在报表或大屏页面使用的,如果当前图表的数据绑定是数据模型,且至少绑定一个维度和度量,在度量上右键,就可以在右键菜单中看到快速表计算这个选项。
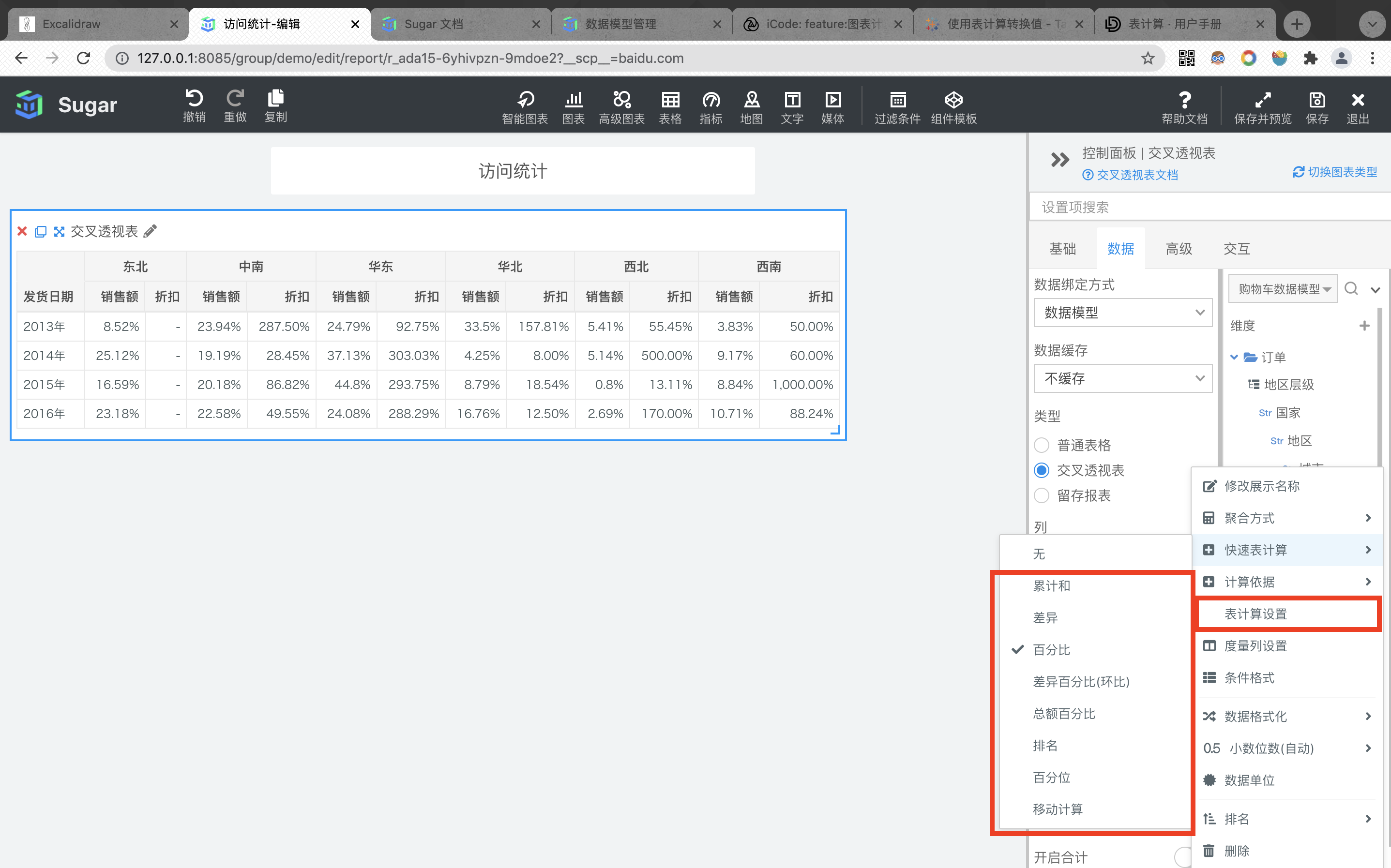
可以看到 Sugar BI 中一共支持 8 种快速表计算方式:累计和、差异、百分比、差异百分比、总额百分比、排名、百分位和移动计算。当选择了某一种快速表计算之后,度量右键菜单中会多出一个表计算设置的选项,可以对当前选定的快速表计算方式进行进一步的配置。此外,还支持表计算的计算依据设定,表计算都是在当前分区内计算的,可以通过设置计算依据来改变分区。默认情况下,计算依据是表横穿,计算依据会在后续章节中详细阐述。
接下来详细介绍各种快速表计算方式。
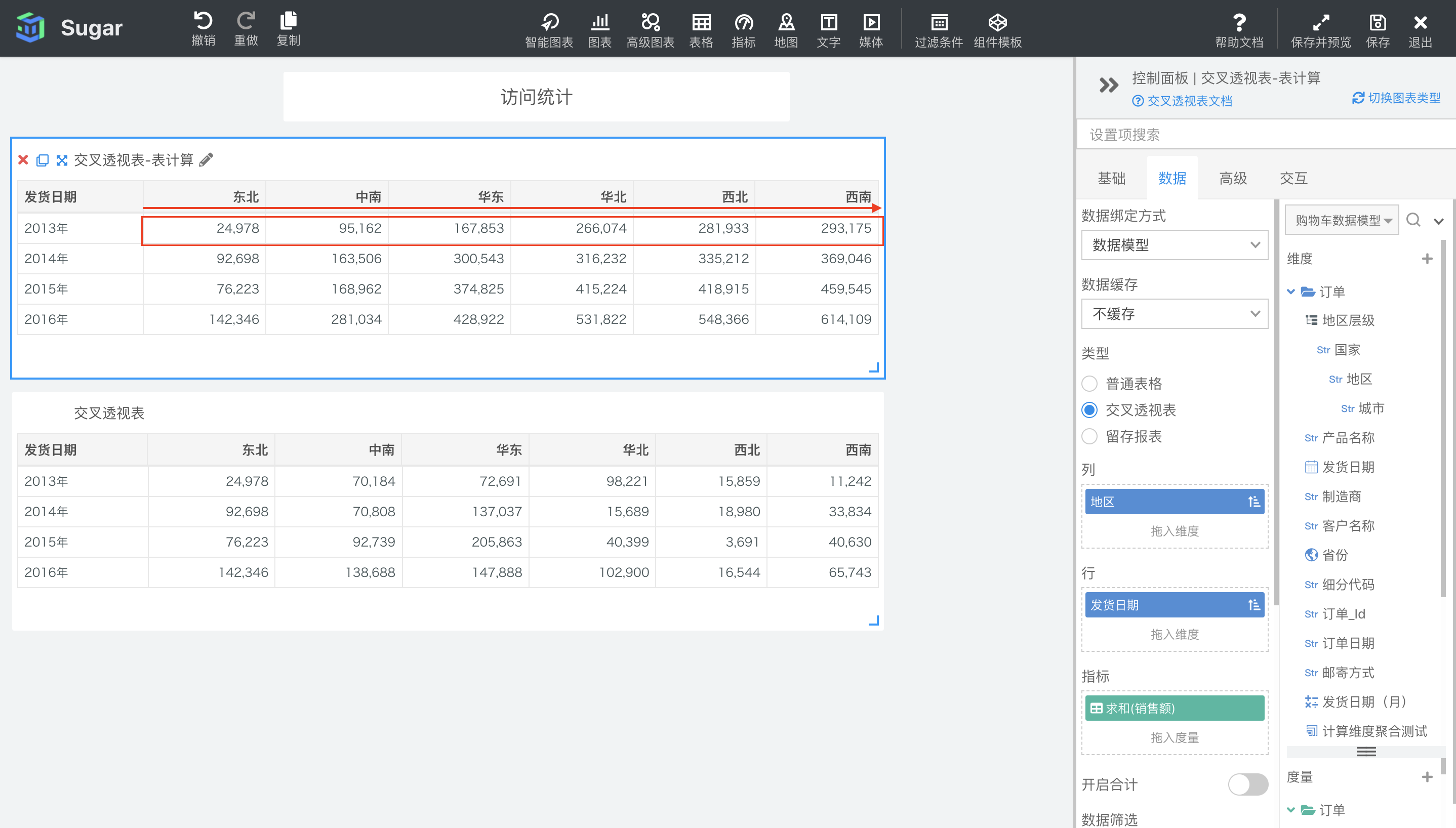
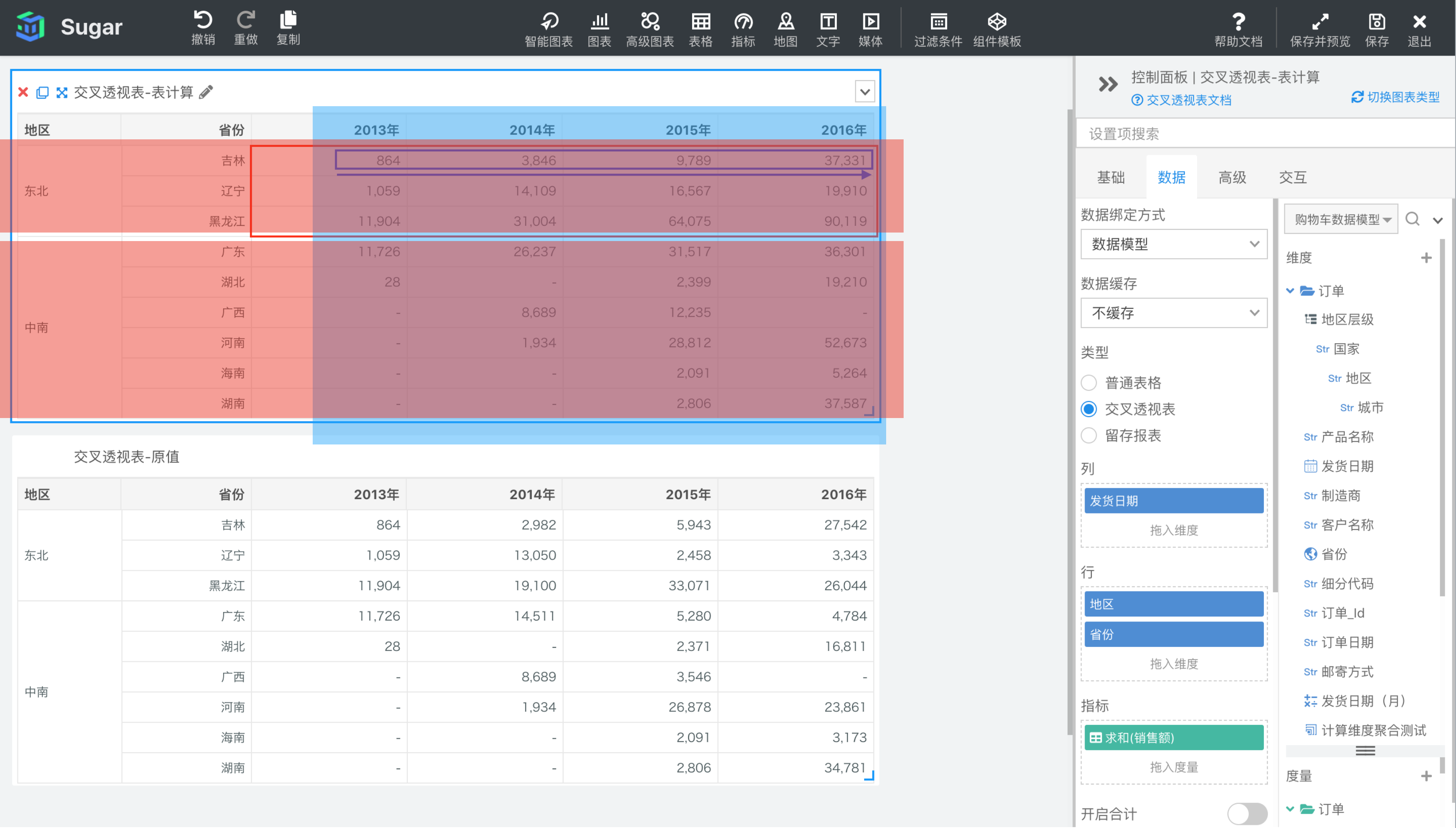
累计和
默认配置下,累计和会按照表横穿的方向,对设置了累计和的度量进行累加。如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值,可以看到第一个表中的值是在每行中按照从左到右的方向进行累加。例如,东北地区作为第一列,表一中,东北地区的值都是自己本身,中南地区的值就等于自身加上东北地区的值。例如 2014 年华东地区的销售额的累计和就等于 92698(2014 年东北地区销售额) + 70808(2014 年中南地区的销售额) + 137037(2014 年华东地区的销售额)= 300543。
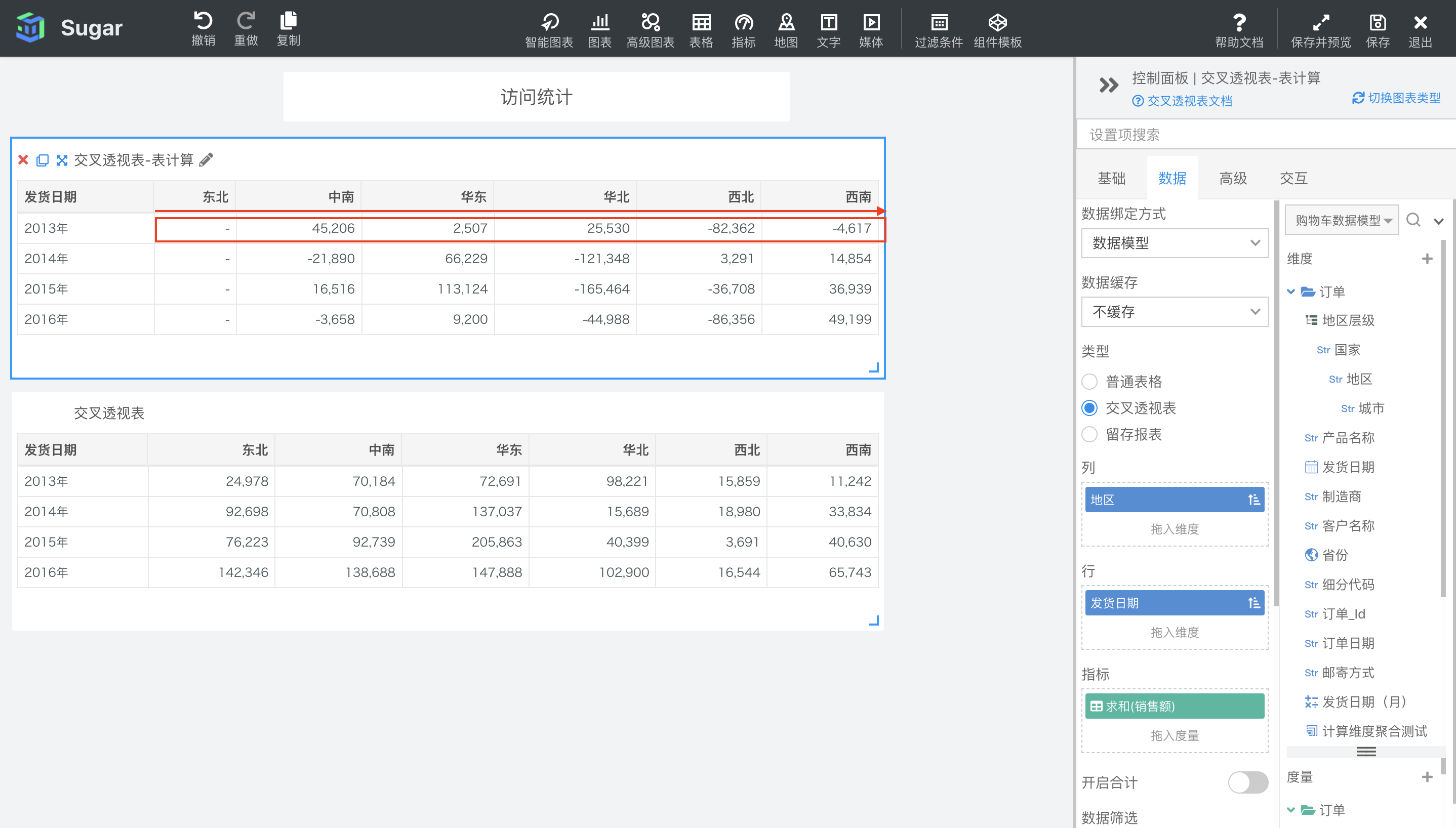
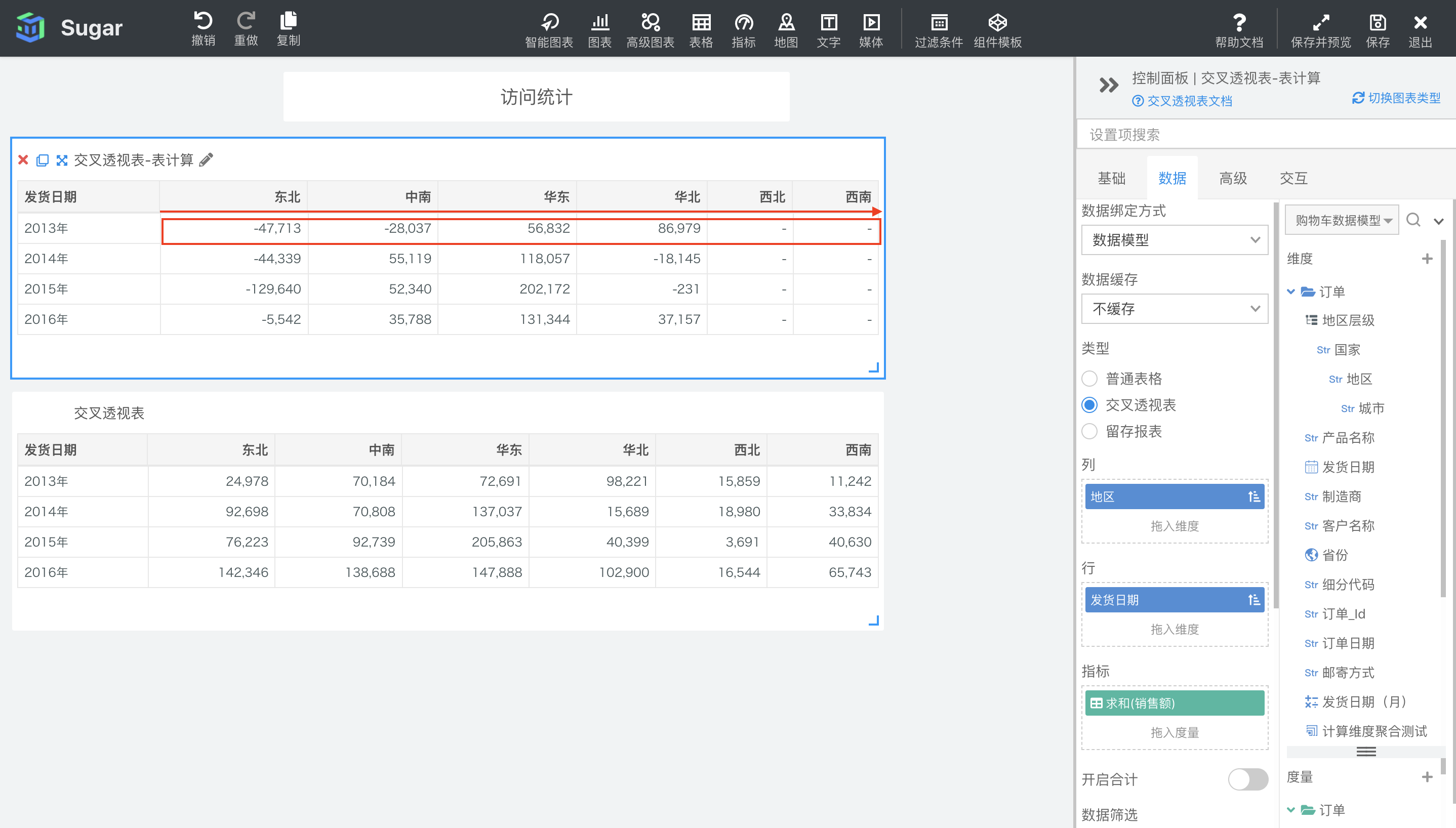
差异
默认配置下,差异会按照表横穿的方向,计算当前项和当前行中前一项的差值。如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值。例如,东北地区作为第一列,没有前一项,所以表一中东北地区没有计算结果,展示为-。中南地区的值就等于自身减去东北地区的值。例如 2014 年华东地区的销售额的差值就等于 137037(2014 年华东地区的销售额) - 70808(2014 年中南地区的销售额))= 66229。
此外,差异还可以在度量右键表计算设置中配置计算对象为前一项、后一项、第一项、最后一项、往前第 n 项和往后第 n 项,这些都是在当前分区内的,默认分区是表横穿,分区也就是当前行。(分区会在下一节中详细介绍)
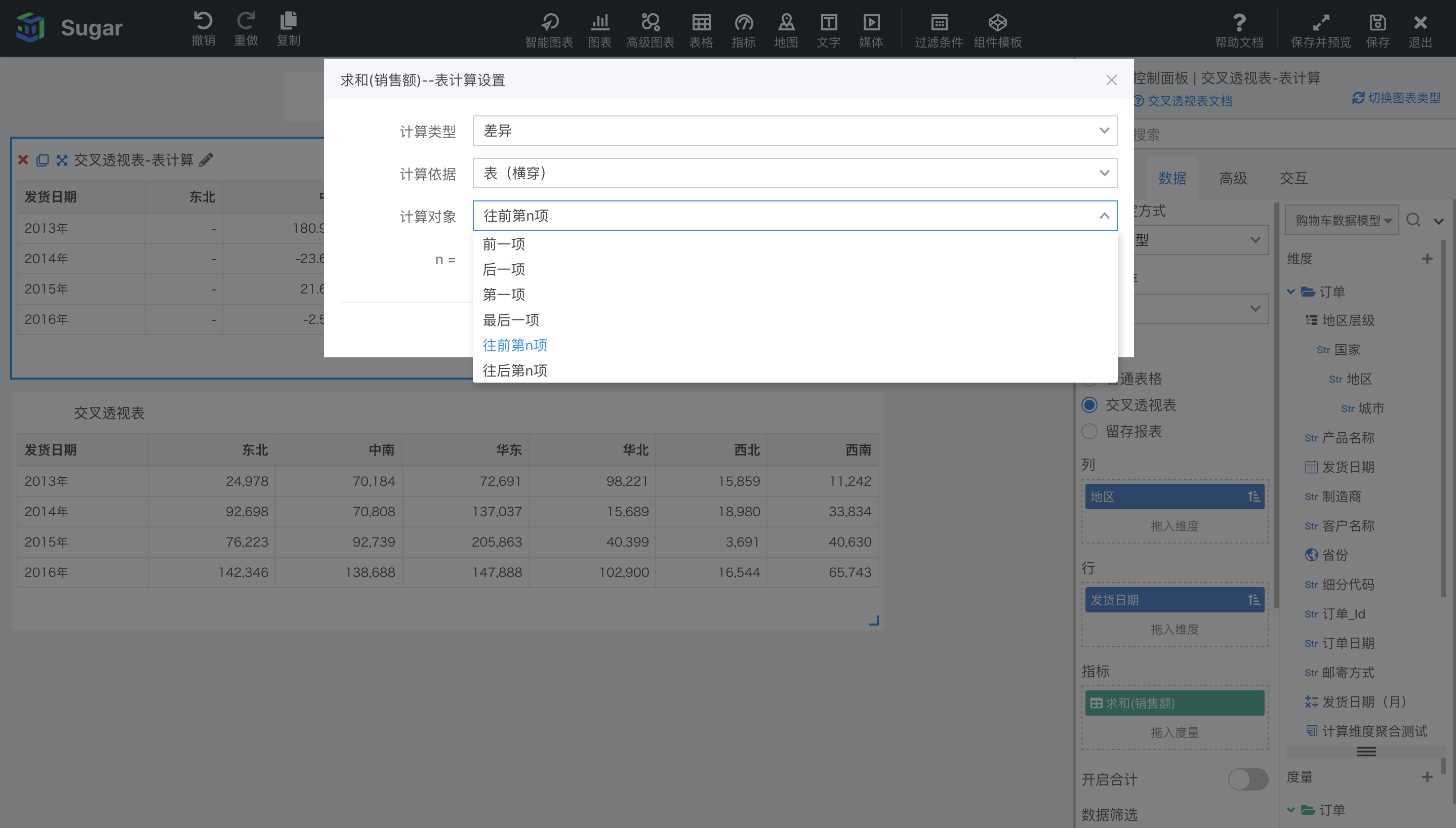
比如设置了计算对象为往后第 2 项,就会计算当前值 和 从当前值往后两个的值 的差值。
百分比
默认配置下,百分比会按照表横穿的方向,计算当前项 除以 当前行中前一项的值,计算百分比。
如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值。例如,东北地区作为第一列,没有前一项,所以表一中东北地区没有计算结果,展示为-。中南地区的值就等于自身除以东北地区的值。例如 2014 年华东地区的销售额的百分比就等于 (137037(2014 年华东地区的销售额)/ 70808(2014 年中南地区的销售额))) x 100 = 193.53%
表计算配置同差异。
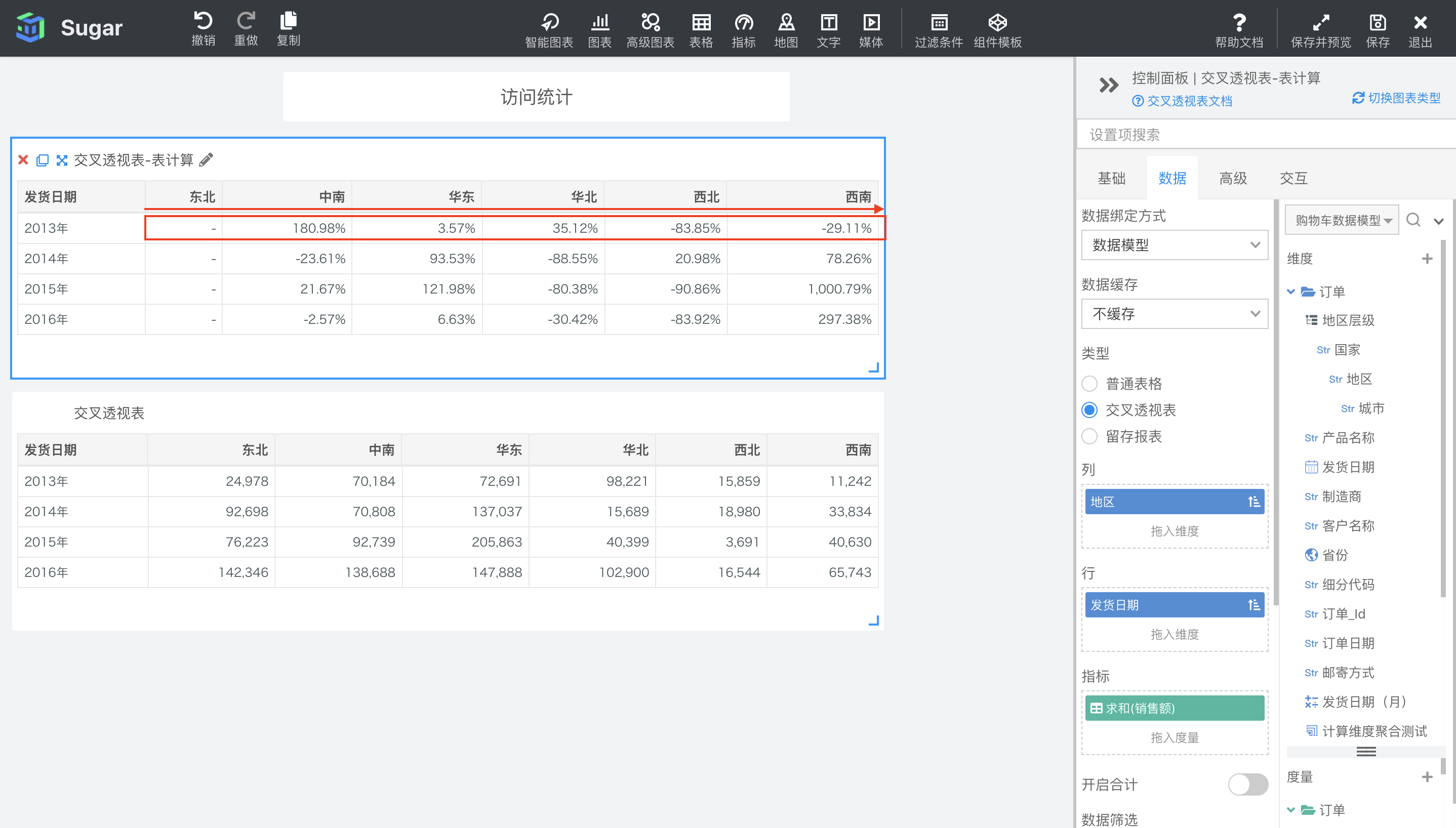
差异百分比
默认配置下,差异百分比会按照表横穿的方向,计算当前项与当前行前一项的差值 除以 当前行中前一项的值,计算百分比。
如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值。例如,东北地区作为第一列,没有前一项,所以表一中东北地区没有计算结果,展示为-。中南地区的值就等于自身与东北地区的差异值,除以东北地区的值。例如 2014 年华东地区的销售额的差异百分比就等于( (137037(2014 年华东地区的销售额) - 70808(2014 年中南地区的销售额))/ 70808(2014 年中南地区的销售额))) x 100 = 93.53%
表计算配置同差异。
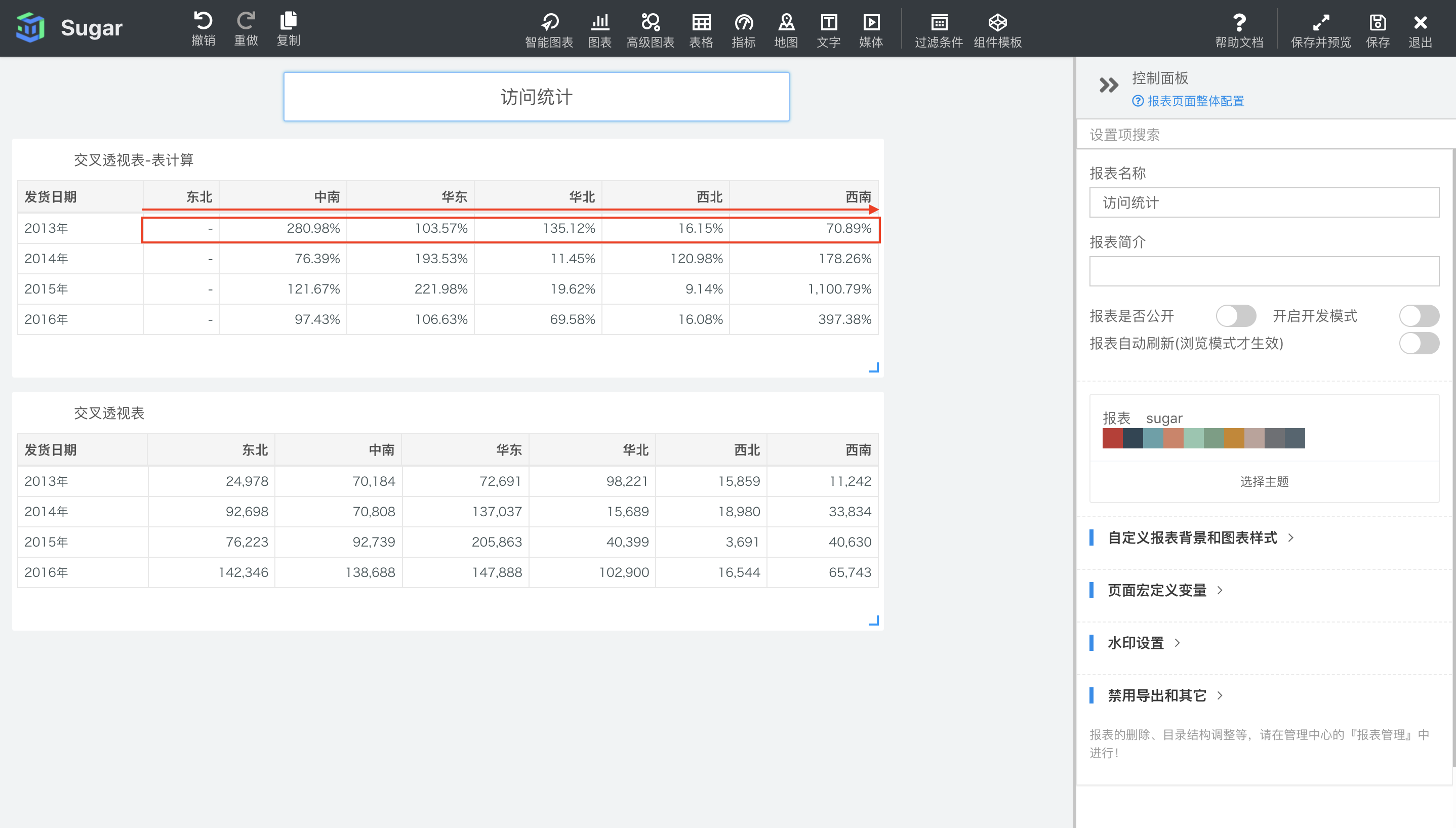
总额百分比
默认配置下,总额百分比会按照表横穿的方向,计算当前项 除以 当前行的总和,然后计算百分比。
如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值。例如,2014 年华东地区的销售额的总额百分比就等于(137037(2014 年华东地区的销售额) / 369046(2014 年销售额总和)) x 100 = 37.13%。
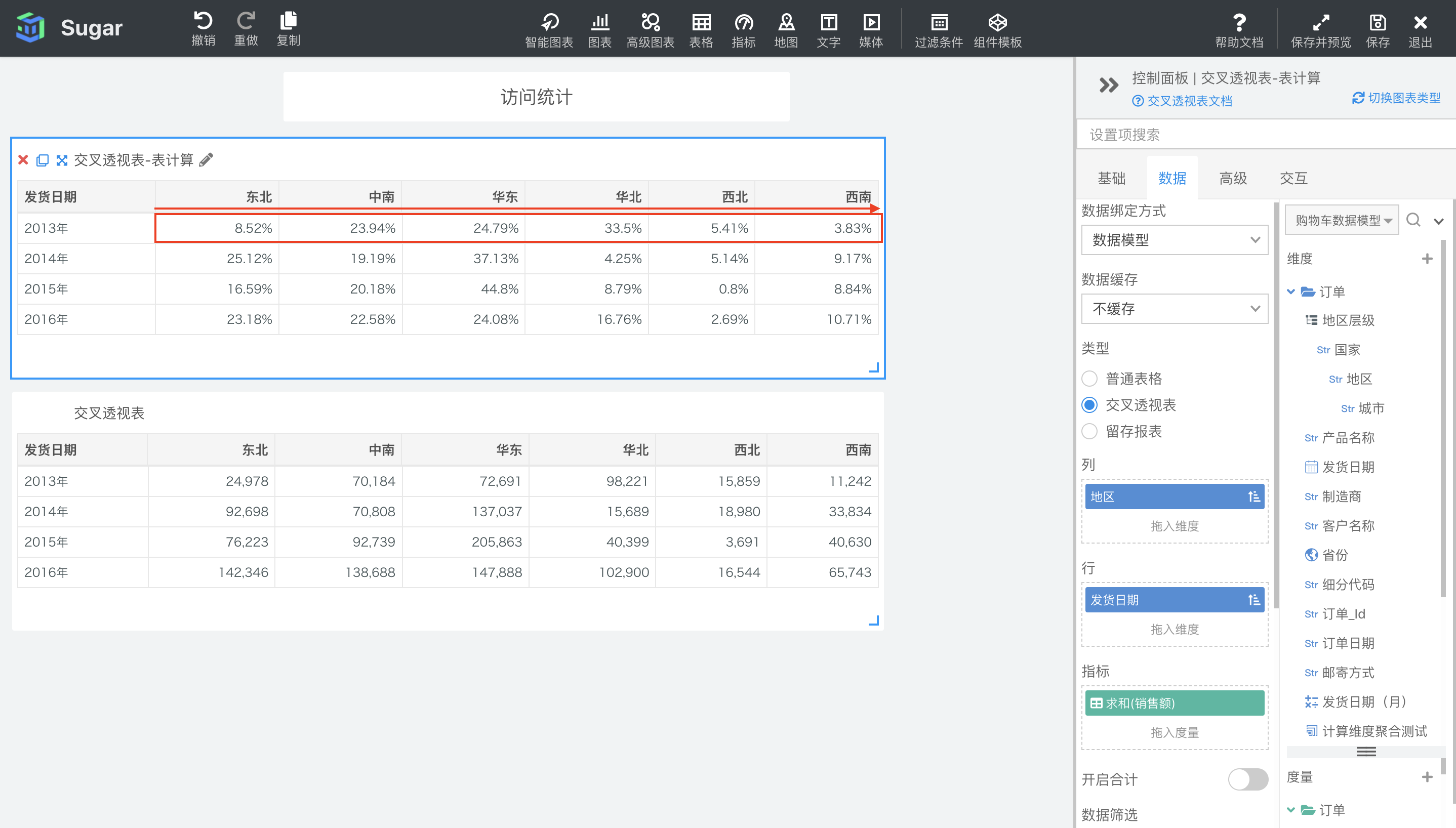
排名
默认配置下,排名会按照表横穿的方向,计算当前项在当前行中的排名,默认使用升序,可在表计算设置中设置升序还是降序。
如下图中所示,第一个交叉透视表是设置了表计算的,第二个交叉透视表是原值。例如,2014 年华东地区的销售额是 137037,在 2014 年度各地区销售额中排名第 6,是销售额最高的地区。
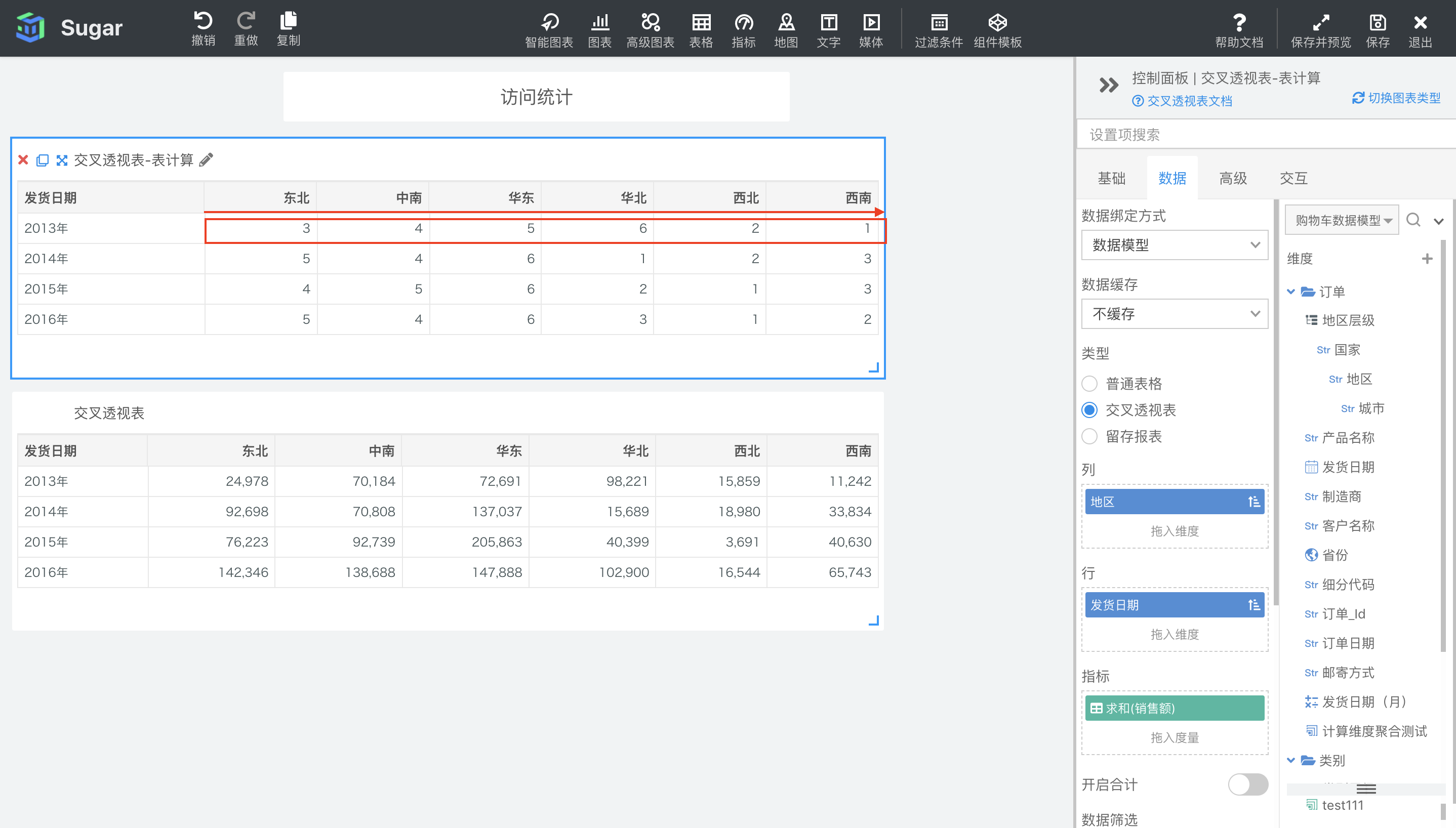
百分位
默认配置下,百分比排名会按照表横穿的方向,计算当前项在当前行中的百分比排名,默认使用升序,可在表计算设置中设置升序还是降序。百分比排名是用“百分比”的方式来展示排名,转换公式为 (排名 - 1) * 100 / (总个数 - 1)。如下图中所示,第一个交叉透视表是销售额的百分位排名,第二个交叉透视表是销售额的具体值。例如,2013 年西南地区的销售额是 11242,在 2013 年度各地区销售额中的升序排名第 1,百分位排名是 0%。
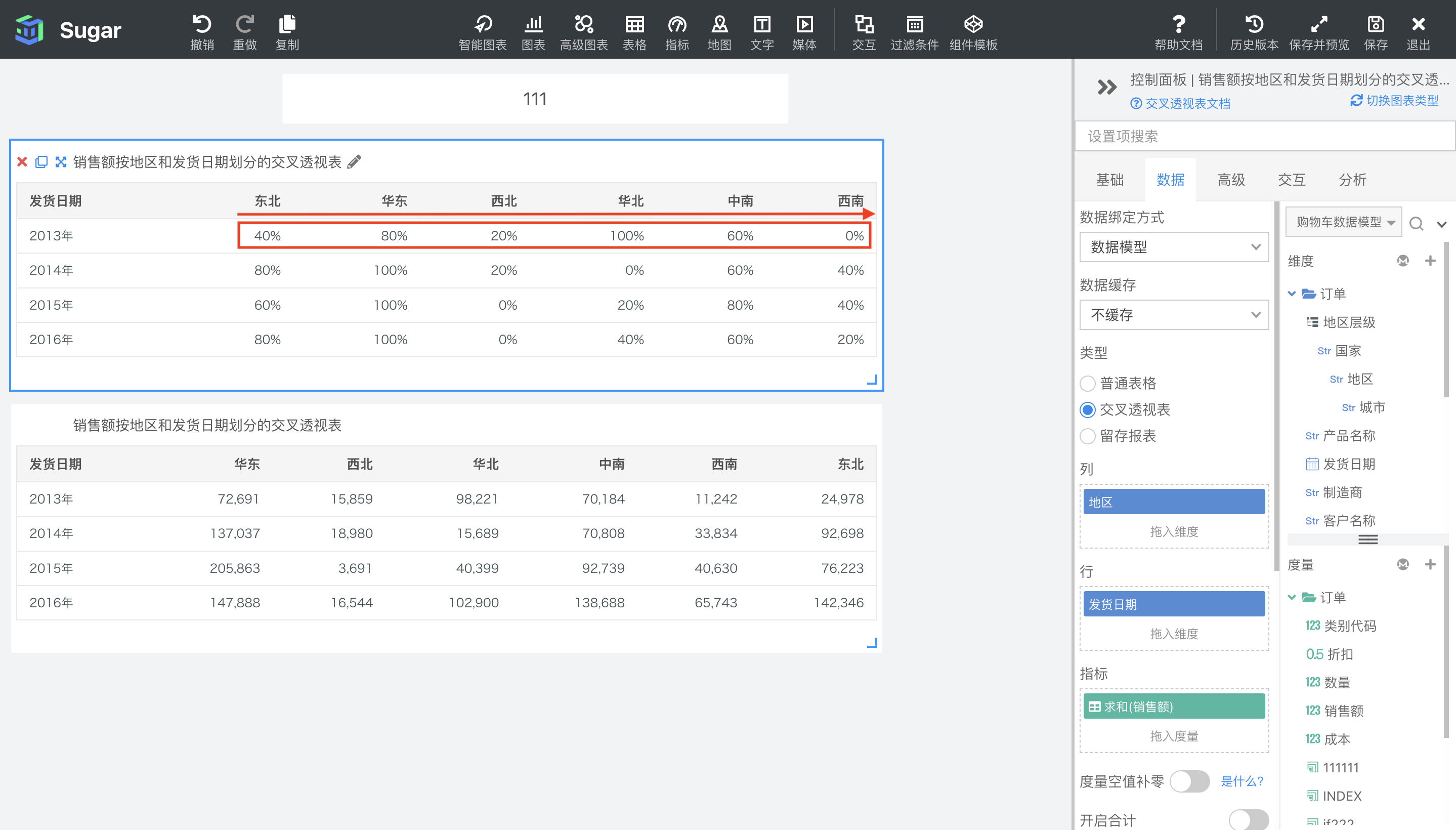
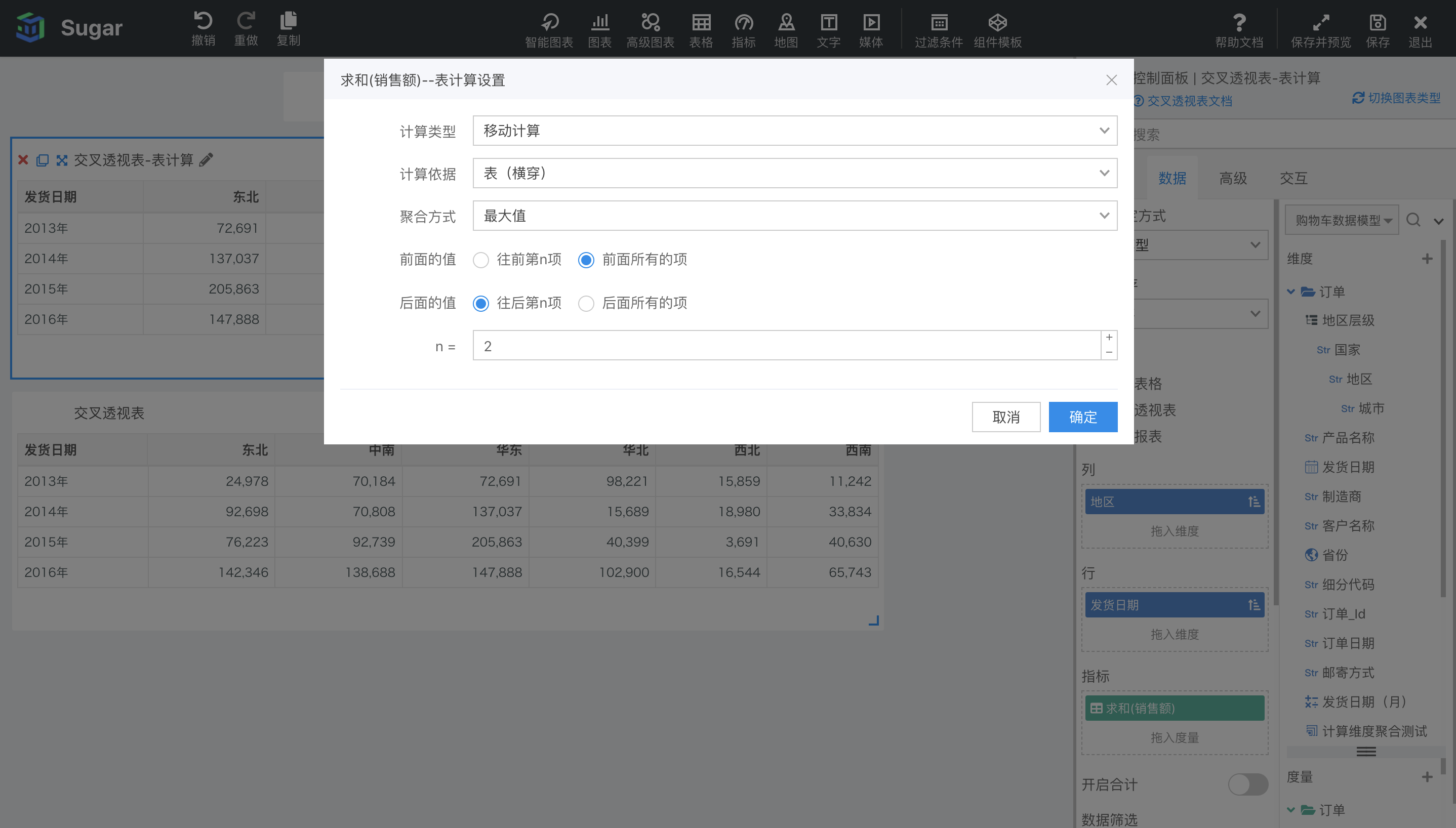
移动计算
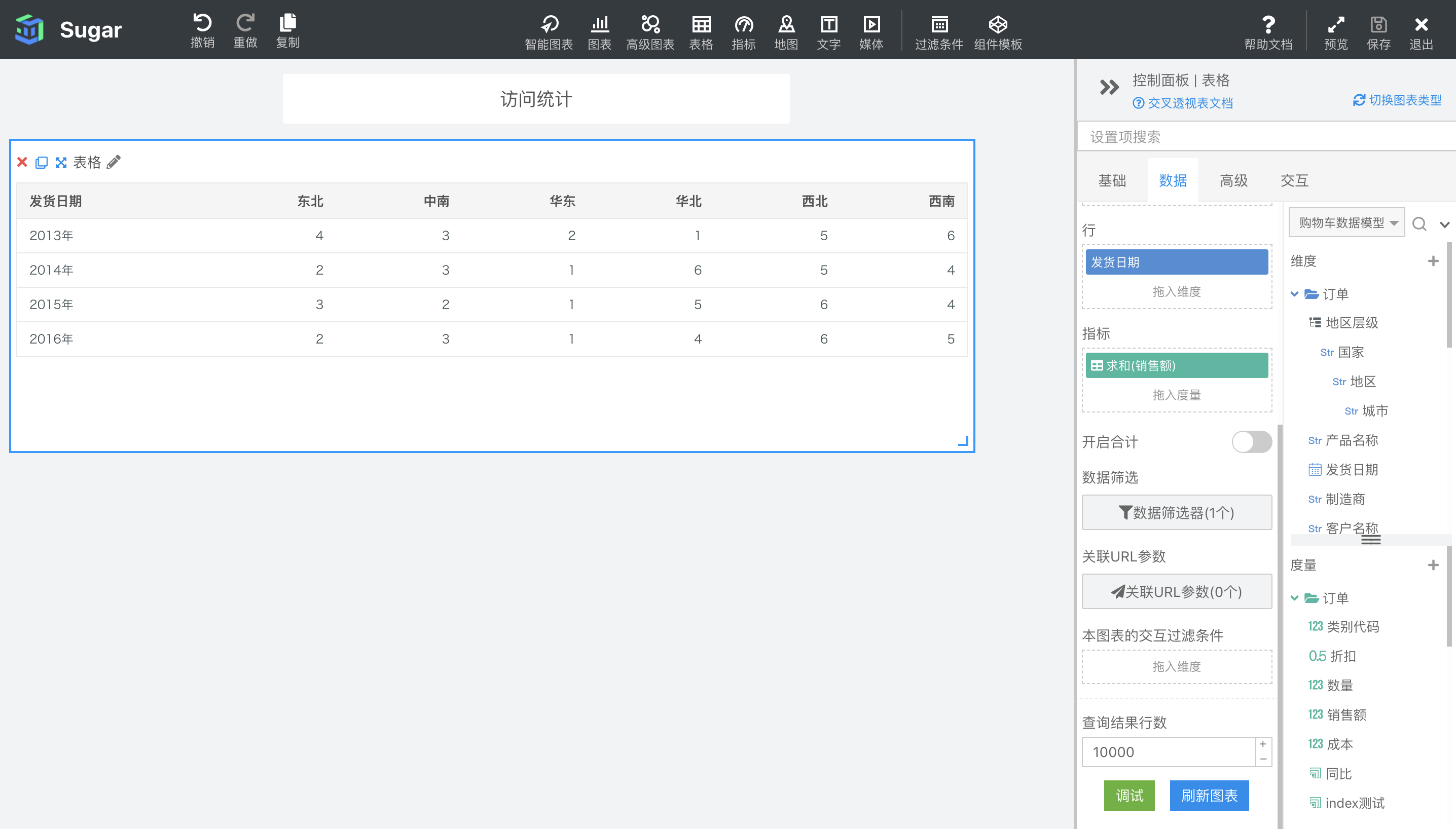
移动计算的表计算配置如下图所示,支持在当前分区内,计算移动窗口内的求和(默认)、平均值、移动最大值、移动最小值。在聚合方式中可以设置是计算求和、平均等,还可以通过前面的值和后面的值设置移动窗口的范围。 以下图中 2014 年为例,聚合方式选择移动求和,窗口选择前面第 0 项(也就是当前项),到后面第 2 项。那么 2014 年东北地区的移动求和就是自己 92698 加上后面两项中南 70808 和华东 137037 的值,等于 300543。2014 年中南地区的移动求和就是自己 70808 加上后面两项华东 137037 和华北 15689 的值,等于 223534。以此类推。
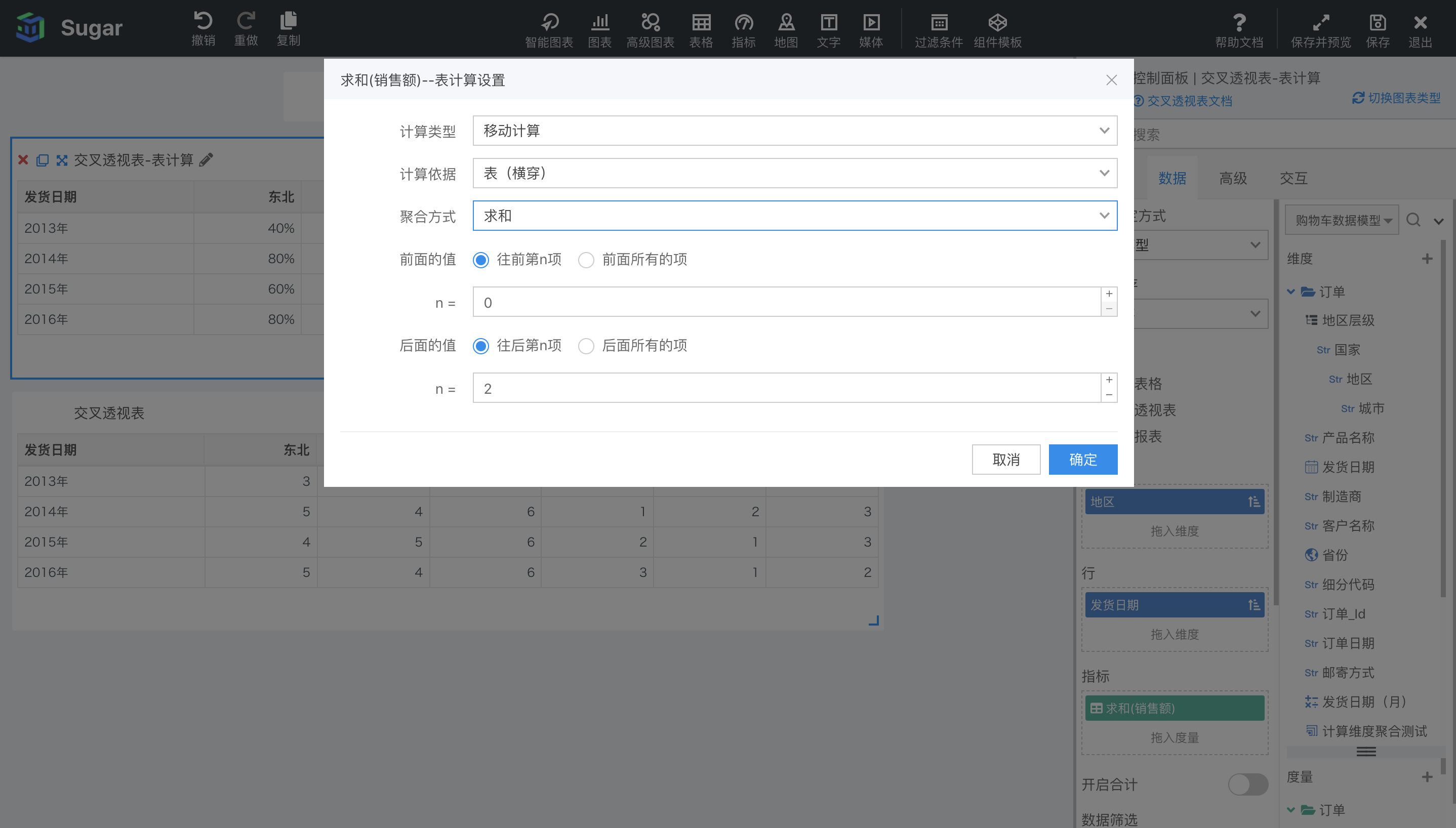
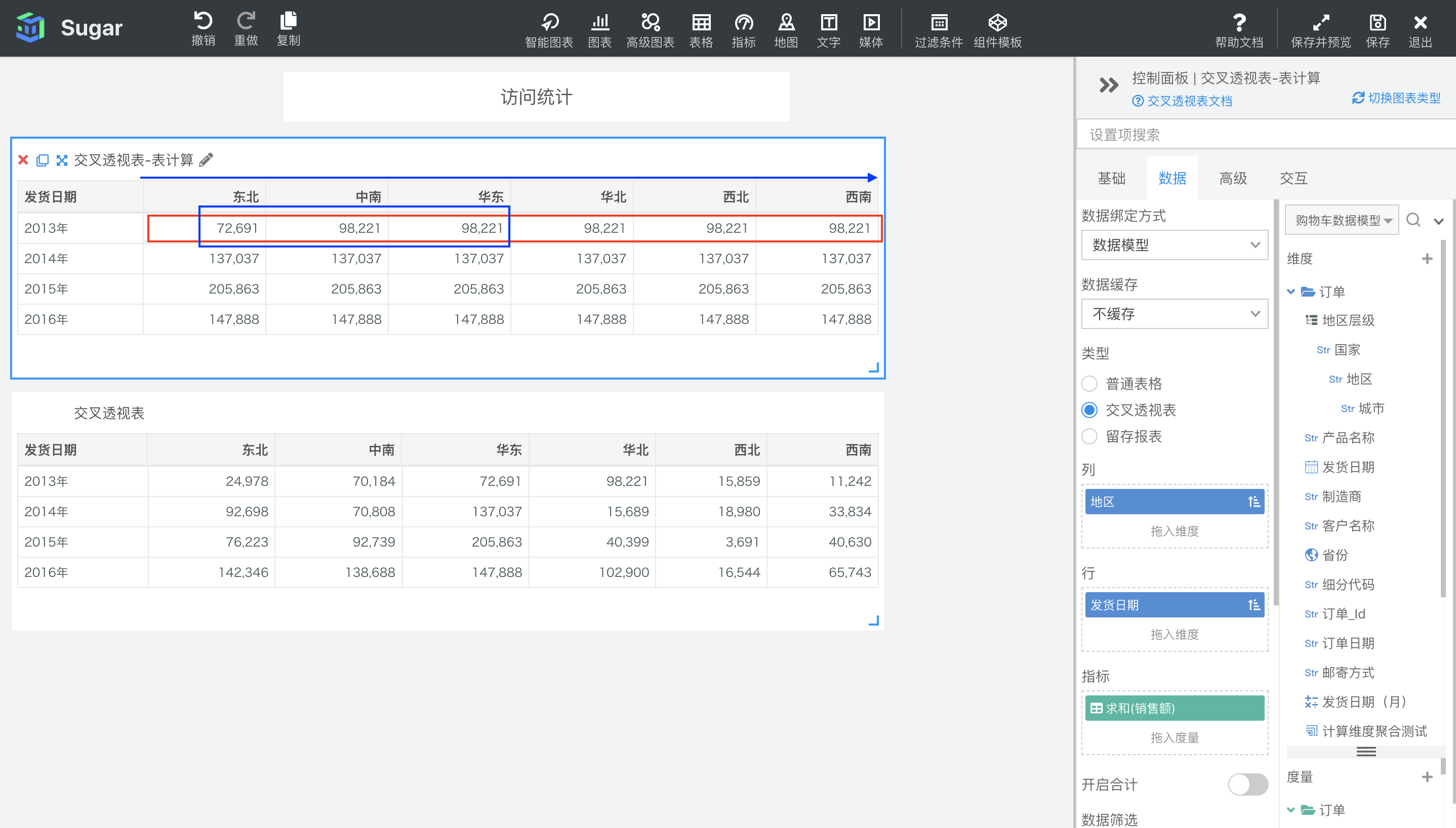
如果聚合方式选择了移动最大值,窗口选择了前面所有的项,到后面第 2 项。那么 2014 年东北地区的移动最大值就是从第一项开始到自己后面两项 中的最大值,等同于求 2014 年东北、中南和华东地区的最大销售额,也就是 137057。2014 年中南地区的移动最大值同样也是求从第一项开始到自己后面两项中的最大值,等同于求 2014 年东北、中南、华东和华北地区的最大销售额,也就是 137057。以此类推。
计算依据
从上述中可以看出,所有表计算都是基于分区的和寻址方向(可以理解为计算方向)的,比如默认的计算依据表横穿的情况,分区就是交叉透视表中的行,寻址方向就是从左到右,即在每行中,从左到右计算表计算的值。
通过设置计算依据,可以改变分区和寻址。分区和寻址是根据当前图表绑定的所有维度进行划分的,用于划分分区,即指定表计算所针对的数据范围的维度成为分区字段,Sugar BI 会在每个分区内单独执行表计算。指定表计算所针对的其余维度成为寻址字段,可以确定表计算在当前分区范围中的计算方向。
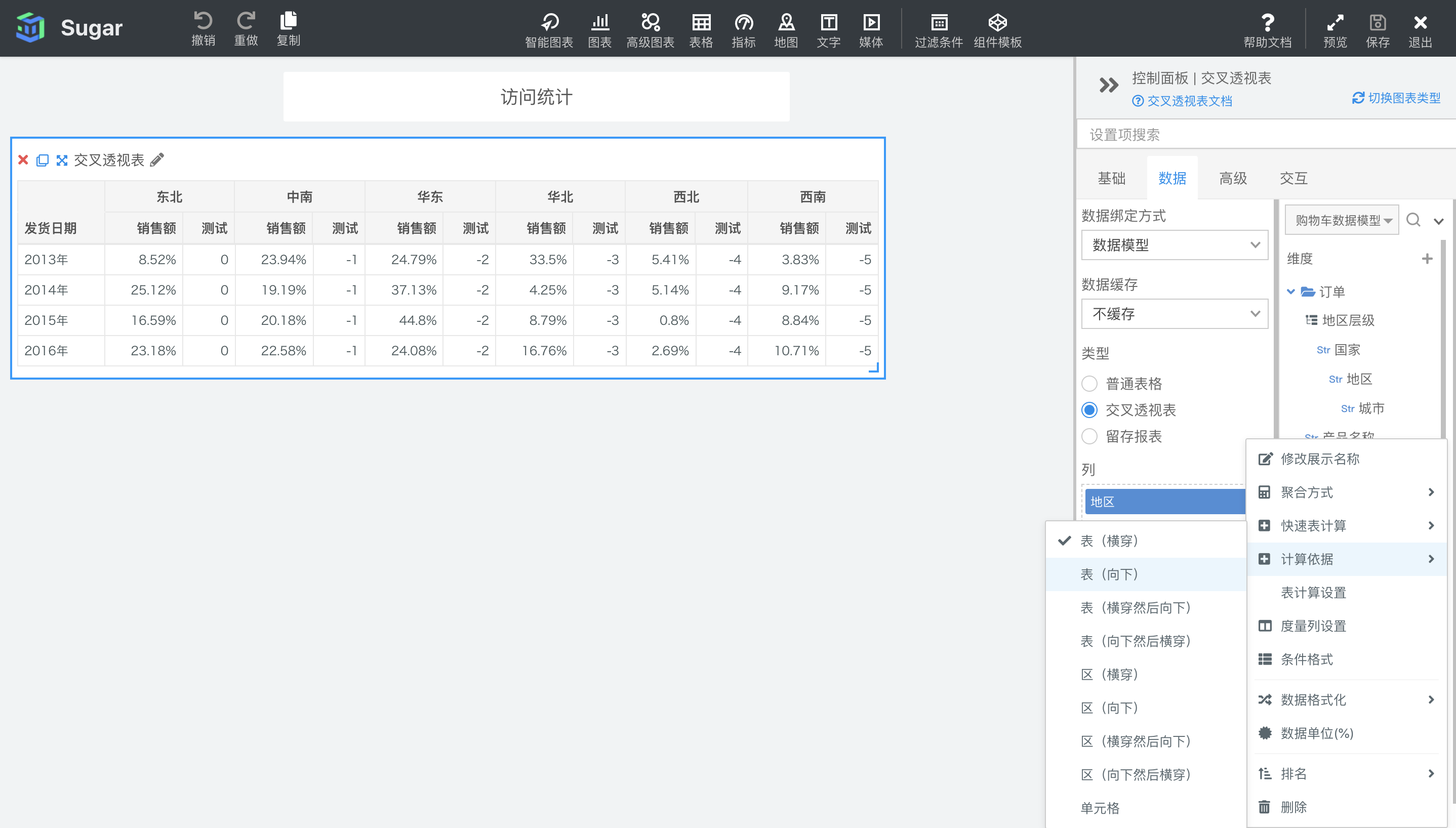
Sugar BI 中共支持了表横穿、表向下、表横穿然后向下、表向下然后横穿、区横穿、区向下、区横穿然后向下、区向下然后横穿、单元格和特定维度这 10 种计算依据,前 9 种计算依据相当于快捷划分分区维度和寻址维度,指定维度相当于可以自由指定分区维度和寻址维度,只在表计算设置中可以对其进行选择和配置。下面我们详细介绍这十种分区方式。
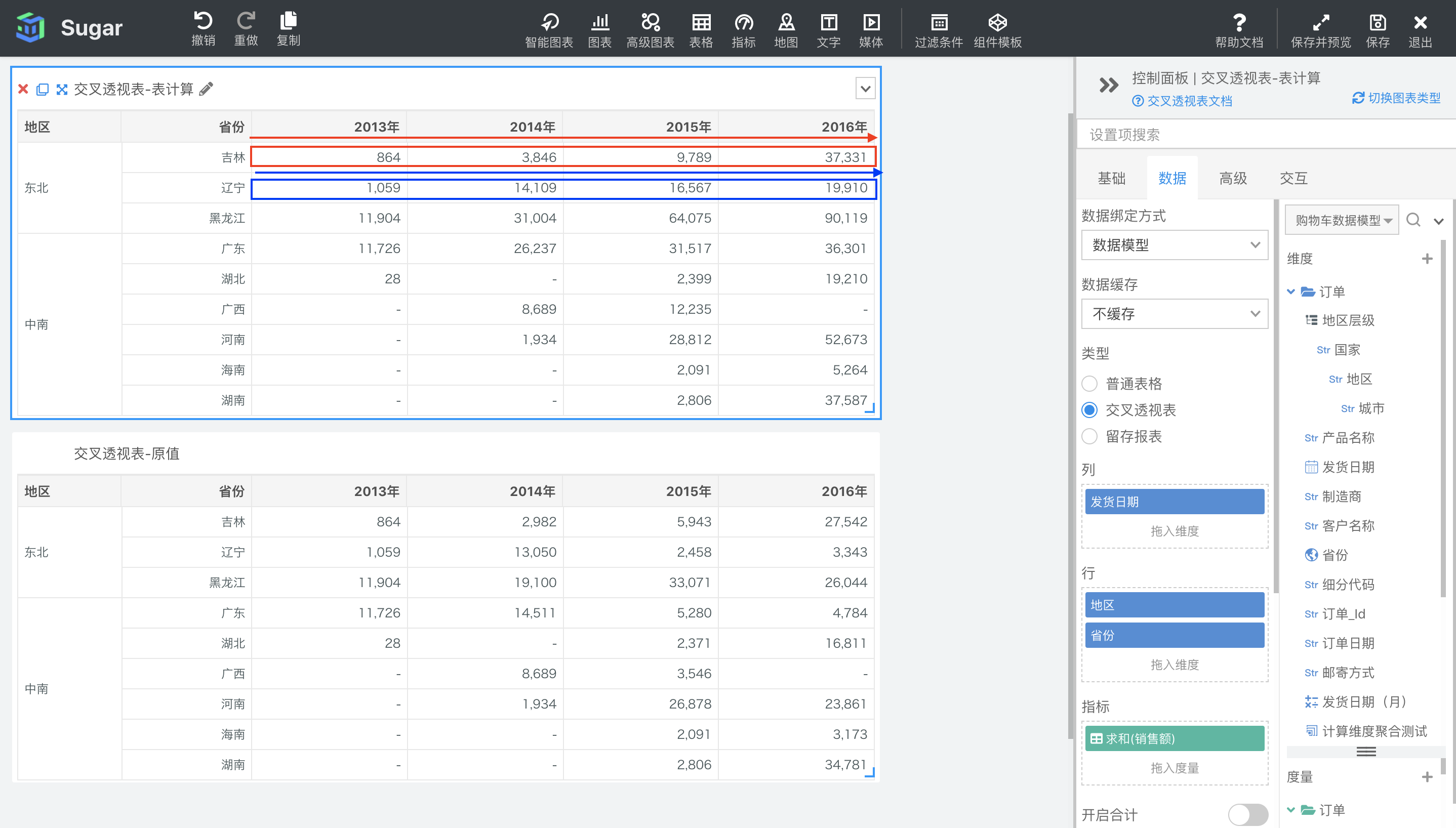
表横穿
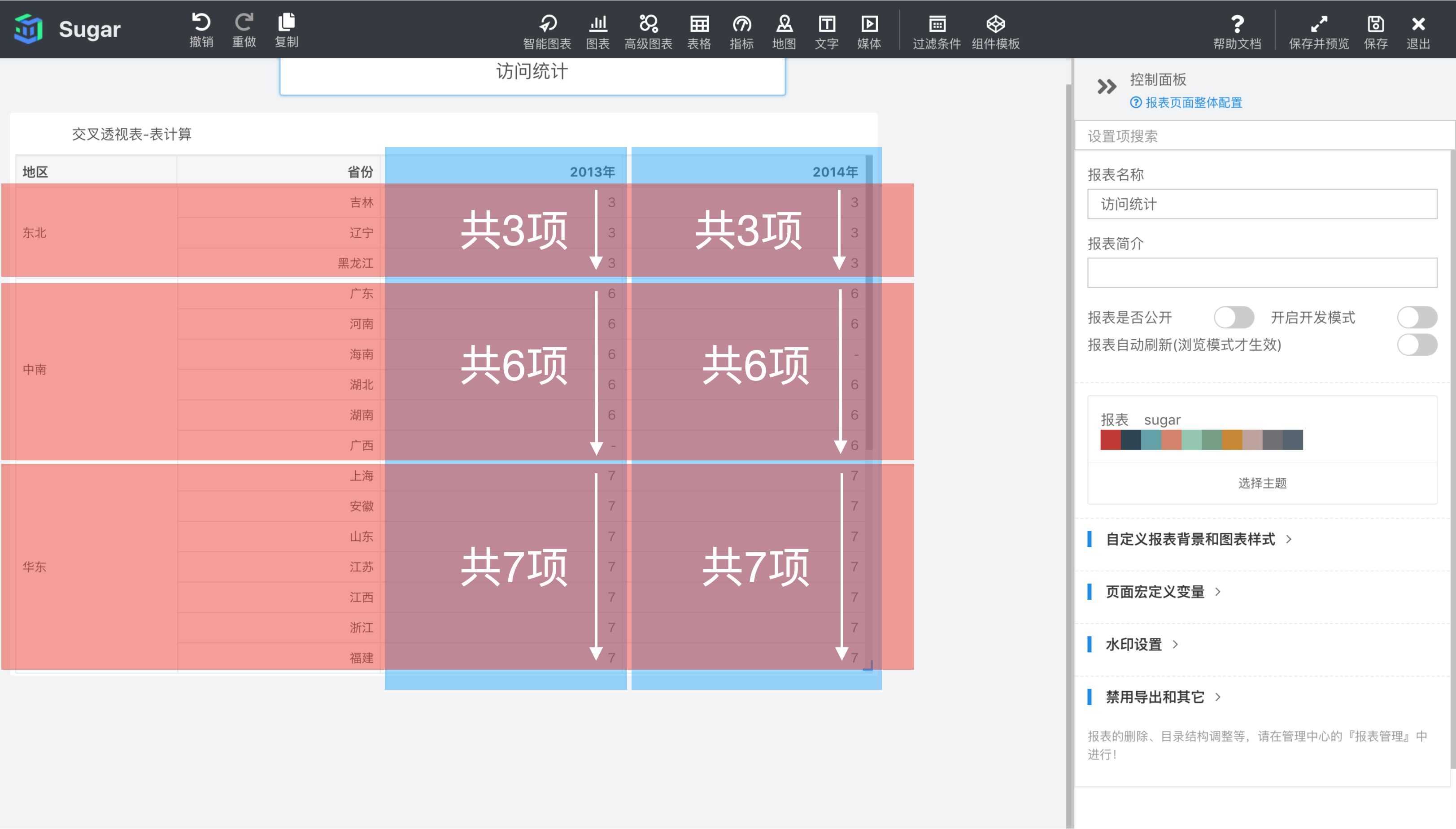
表横穿是以绘出的交叉透视表中的每行为一个分区,从左到右为寻址方向,进行表计算。如下图所示,表一设置了表横穿方向的累计和计算,表二是原值,可以看出,数据会在每行从左到右进行累加,但下一行(下一个分区)又会重新开始计算,并不会累计上一行的结果。
此时分区维度为地区、省份,寻址维度为发货日期。
表向下
表向下是以绘出的交叉透视表中每列为一个分区,从上到下为寻址方向,进行表计算。如下图所示,表一设置了表向下方向的累计和计算,表二是原值,可以看出,数据会在每列中从上到下进行累加,但右边的列(下一个分区)又会重新开始计算,并不会累计上一列的结果。
此时分区维度为发货日期,寻址维度为地区和省份。
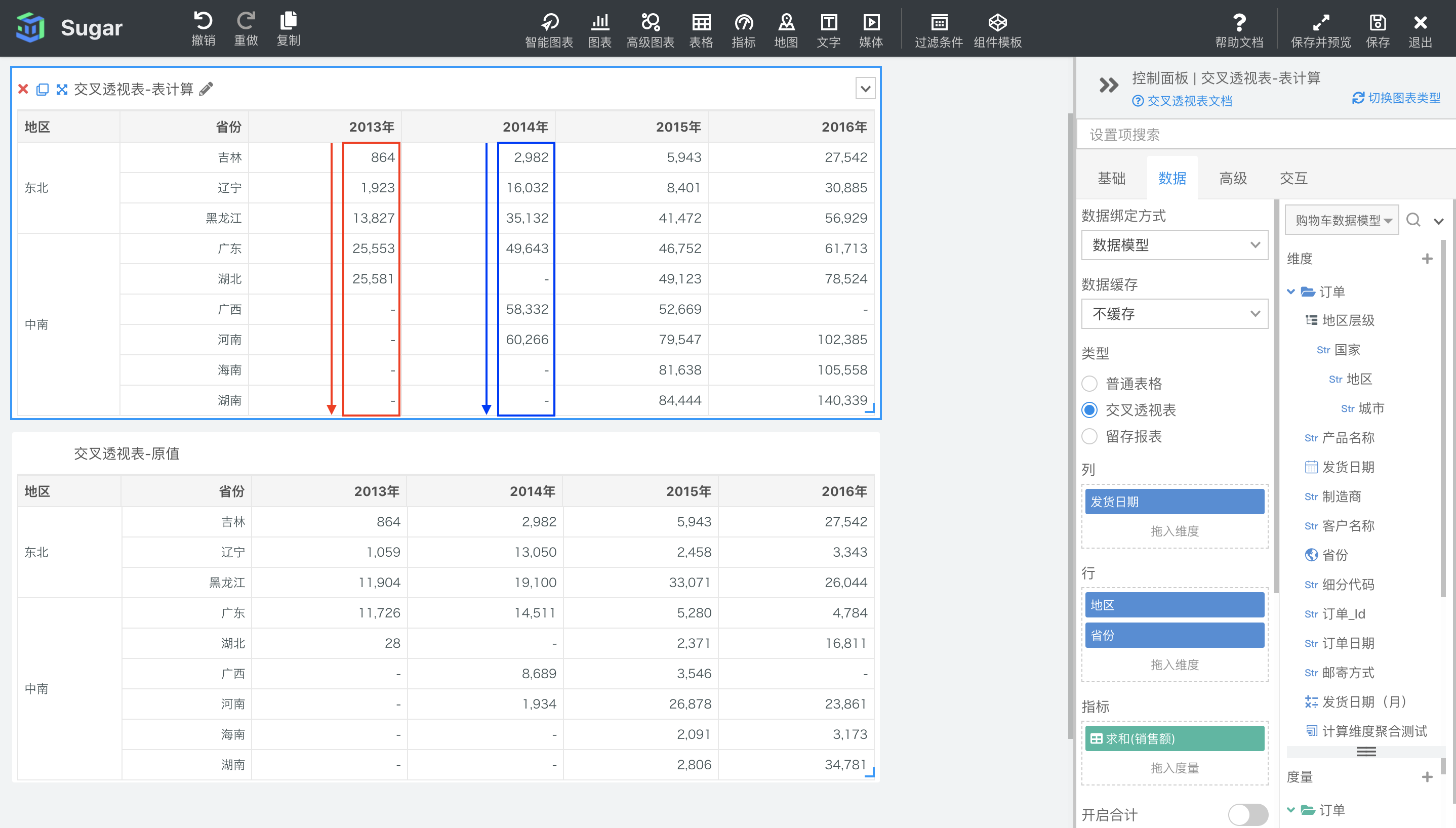
表横穿然后向下
表横穿然后向下是以绘出的交叉透视表的整表为分区,先按行从左到右,再累加到下一行从左到右为寻址方向,进行表计算。如下图所示,表一设置了表向下方向的累计和计算,表二是原值,可以看出,数据会在每行中从左到右进行累加,然后下一行的第一个值是在上一行的累加结果基础上进行累加。
此时没有分区维度,寻址维度为地区、省份和发货日期。
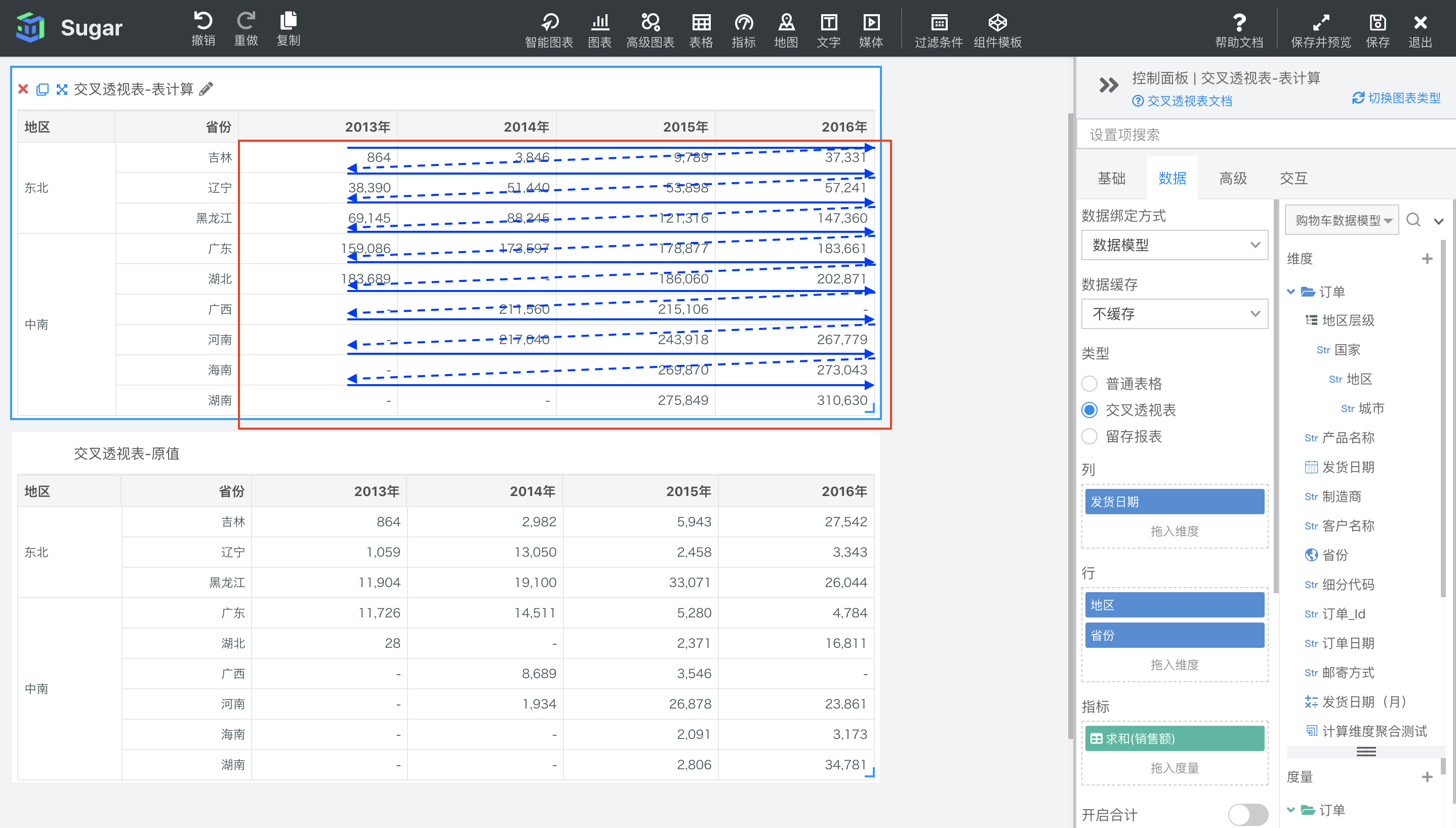
表向下然后横穿
表向下然后横穿是以绘出的交叉透视表的整表为分区,先按列从上到下,再累加到下一列从上到下为寻址方向,进行表计算。如下图所示,表一设置了表向下方向的累计和计算,表二是原值,可以看出,数据会在每列中从上到下进行累加,然后下一列的第一个值是在上一列的累加结果基础上进行累加。
此时没有分区维度,寻址维度为发货日期、地区和省份。
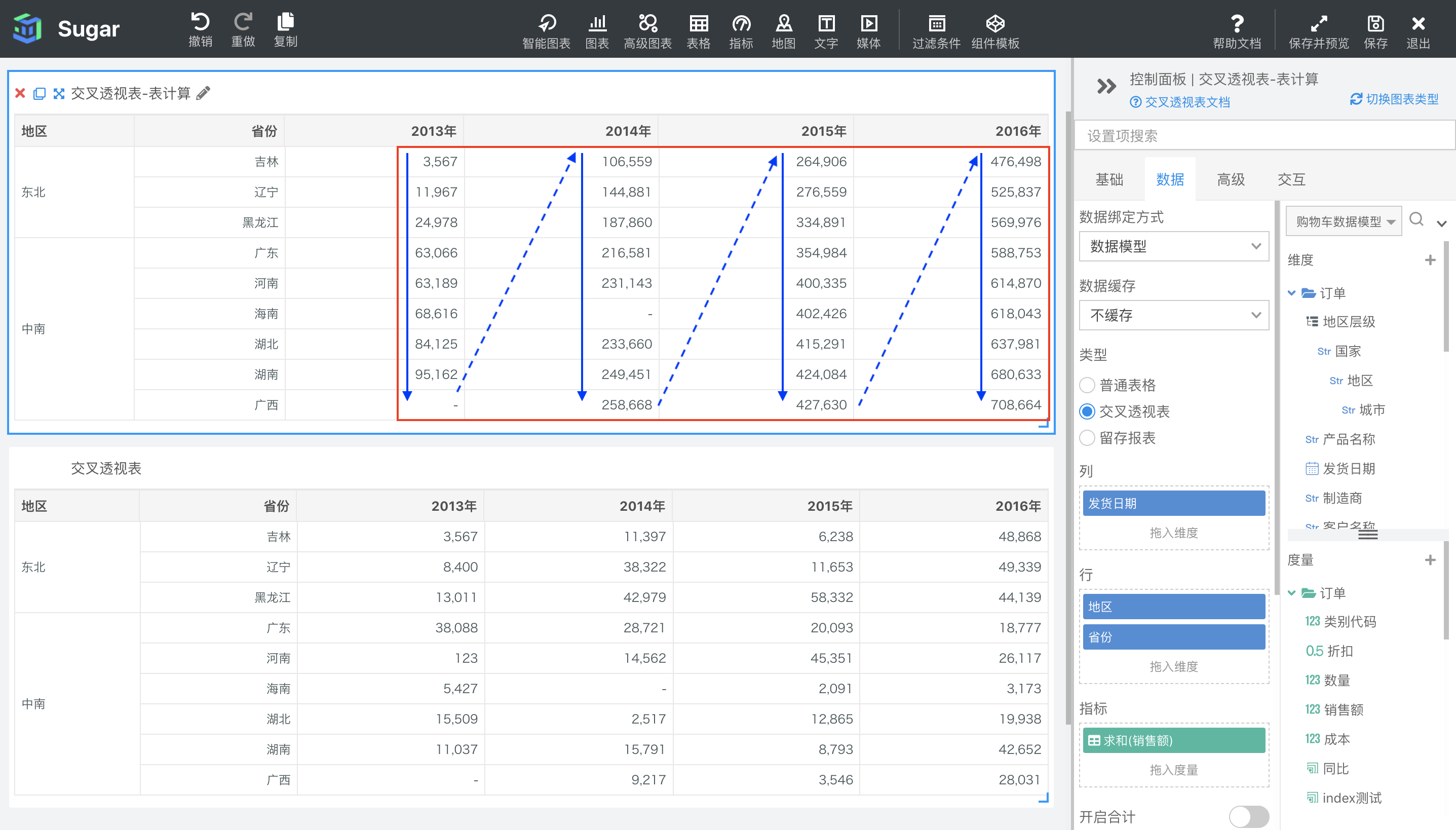
区横穿
上述四种都是在整表的范畴内,进行行横穿或者列向下,接下来的四种是在区的范围内横穿或者向下的。那么什么是区呢?这里的区是按照第二细粒度、第二内层的行维度和列维度进行划分的。下图例子中,行维度是地区和省份,最细粒度的行维度是省份,第二细粒度的行维度就是地区了,而列维度只有发货日期,不存在第二细粒度的列维度,所以第二细粒度的列维度的辐射范围相当于所有列。以地区和所有列划分分区的话,就是下图中红框的部分。可看看到,当不存在第二细粒度的列维度时,区横穿的结果实际与表横穿是相同的。
此时分区维度为地区、省份,寻址维度为发货日期。
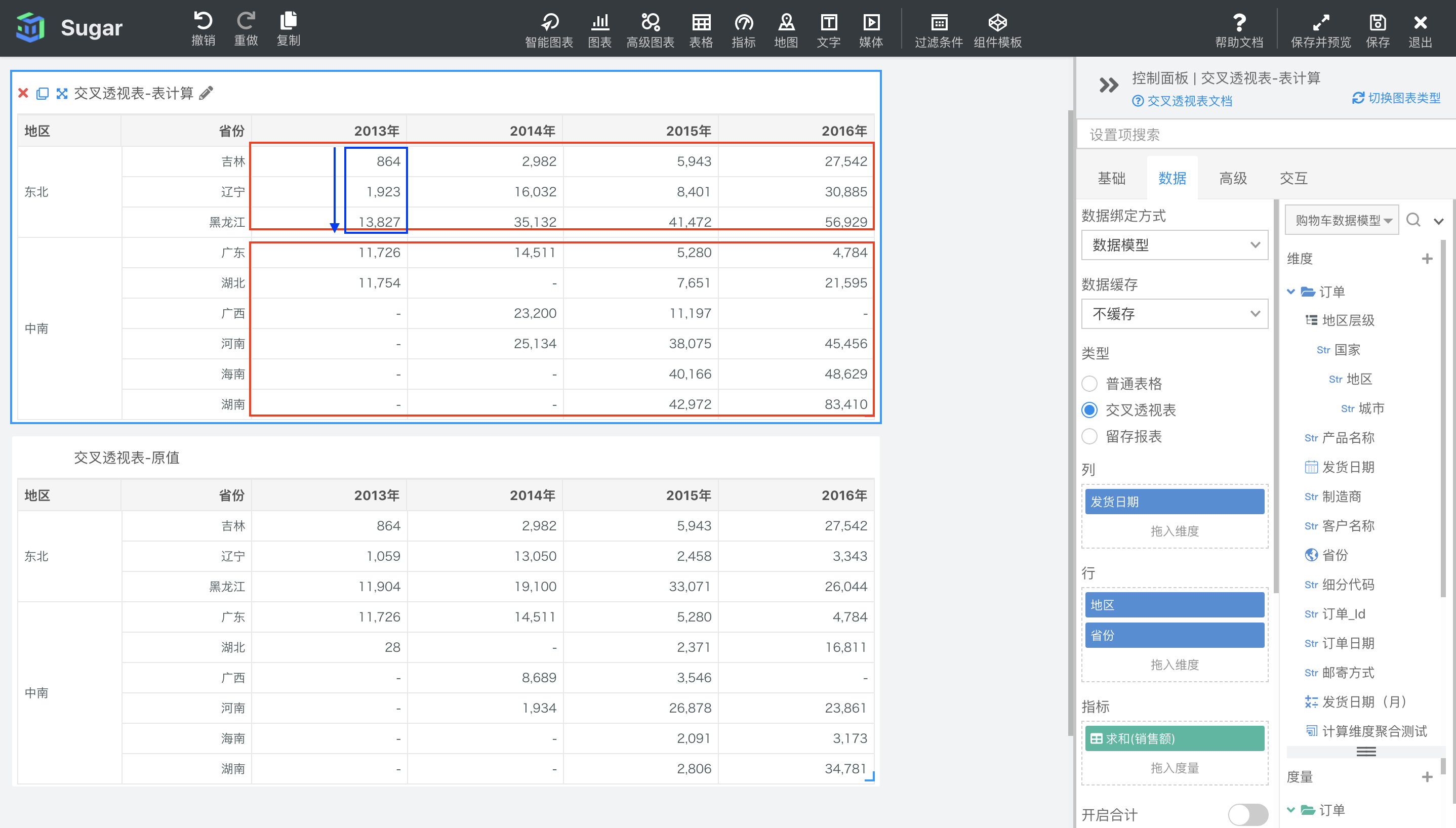
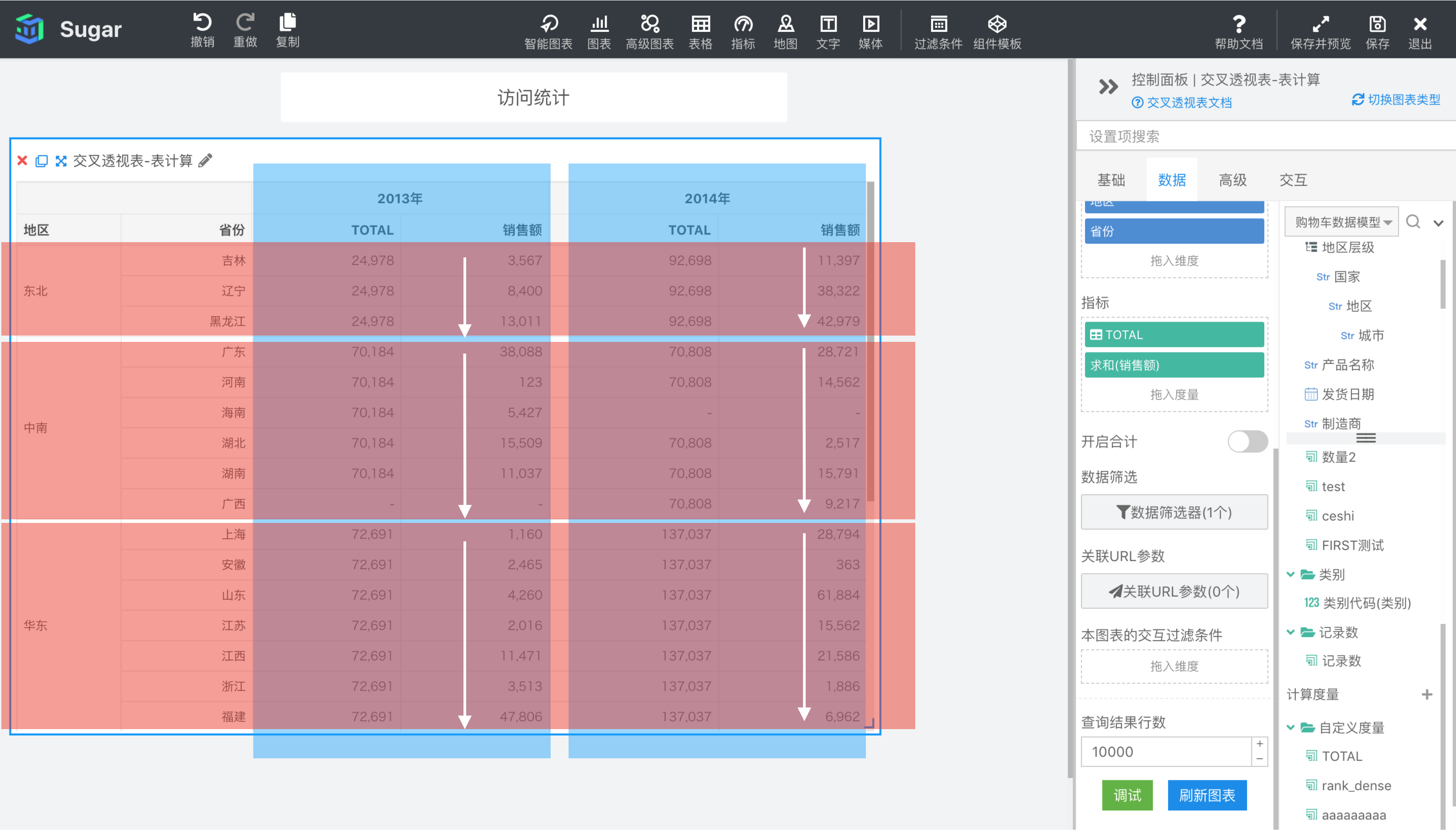
区向下
区向下是根据区横穿中分析的分区,也就是下图中红框部分,按列进行从上到下的寻址。如下图所示,可以看到与表向下不同,区向下的累加只在东北地区范围内累加,中南地区广东的数据还是原值,没有受到东北地区的影响。
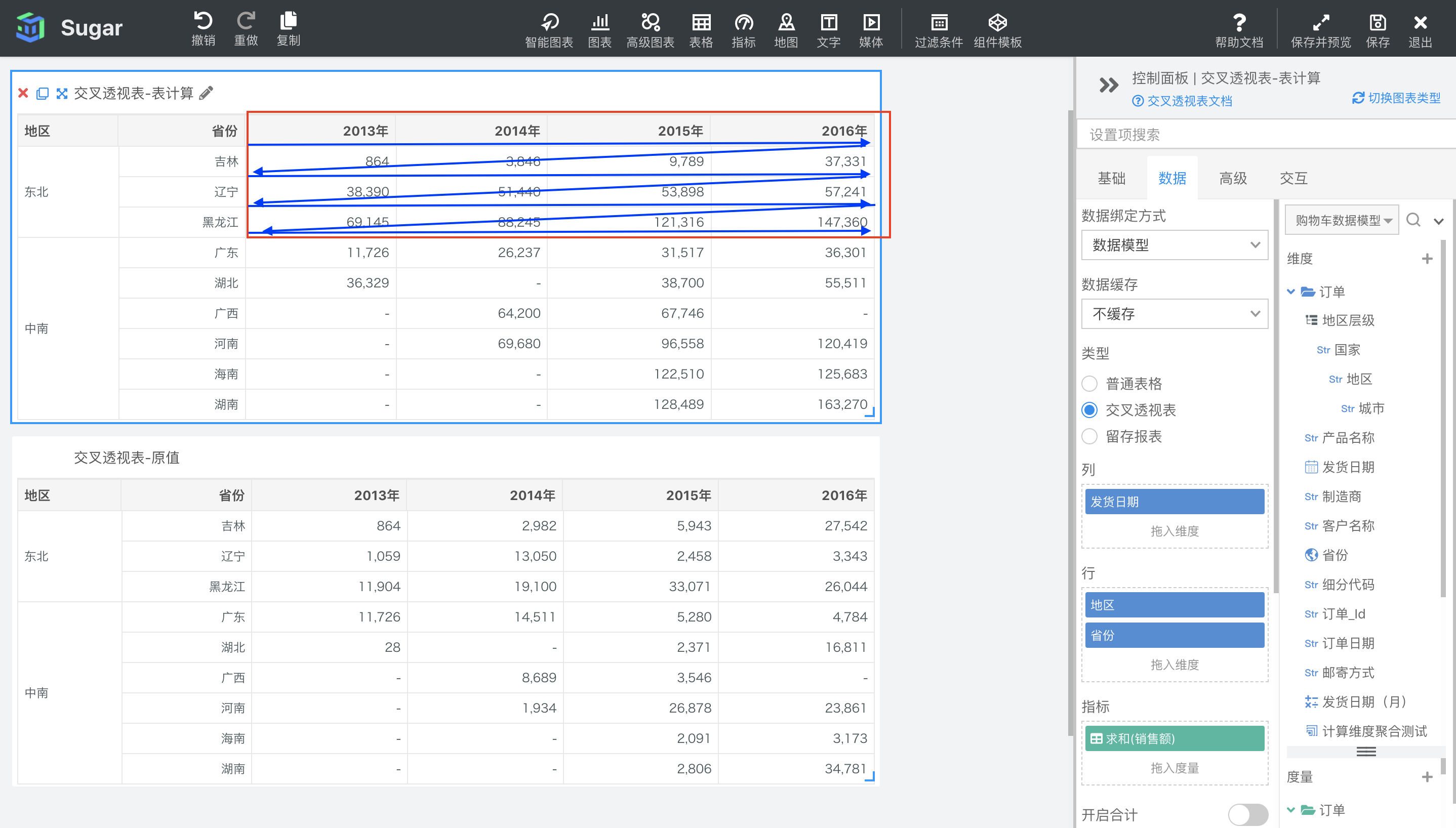
区横穿然后向下
区横穿然后向下是根据区横穿中分析的分区,也就是下图中红框部分,先按行从左到右,再累加到下一行从左到右为寻址方向,进行表计算。如下图所示,可以看到与表横穿然后向下不同,区横穿然后向下的累加只在东北地区范围内累加,中南地区广东的数据还是原值,没有受到东北地区的影响。
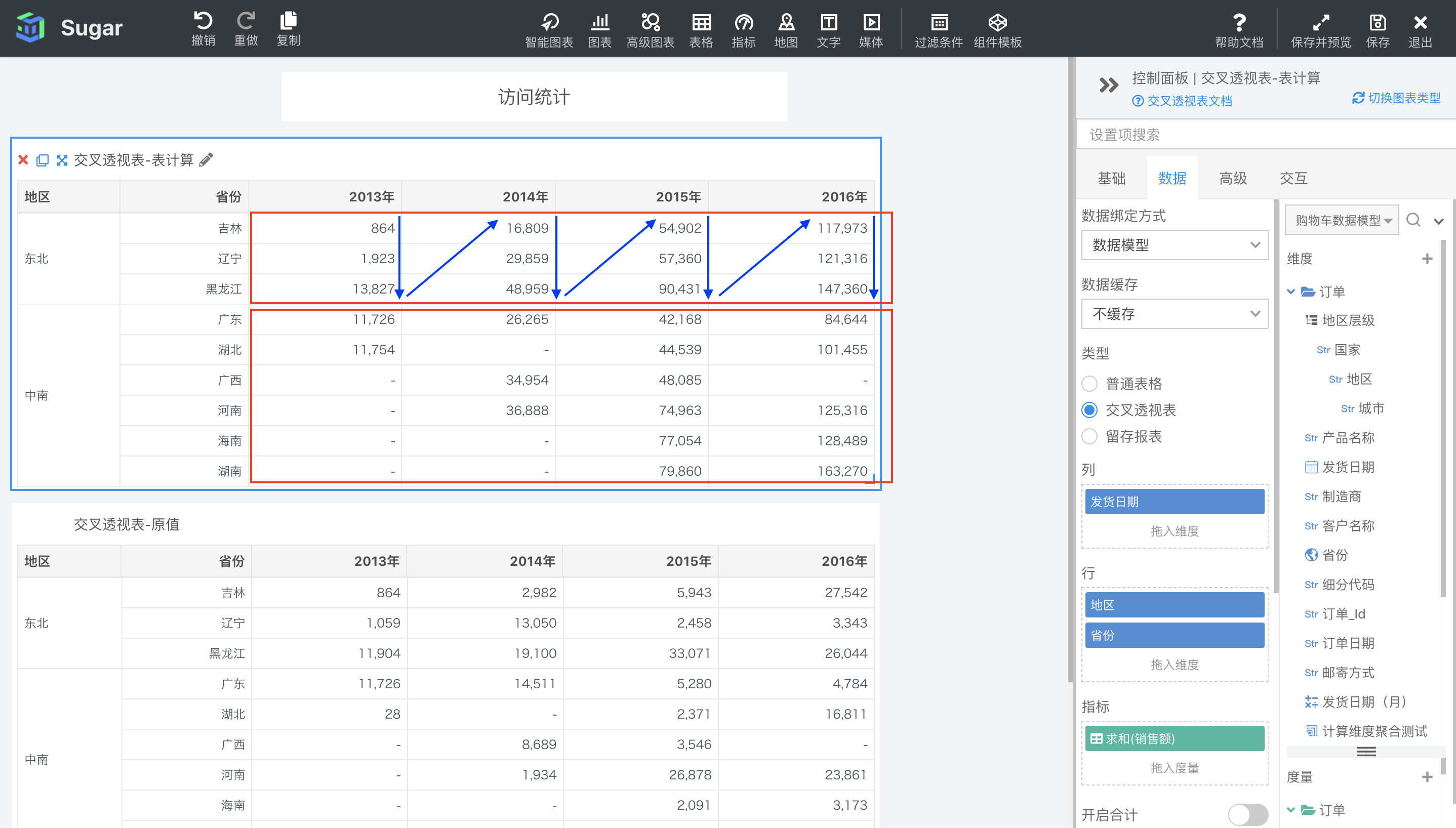
区向下然后横穿
区向下然后横穿是根据区横穿中分析的分区,也就是下图中红框部分,先按列从上到下,再累加到下一列从上到下为寻址方向,进行表计算。如下图所示,可以看到与表向下然后横穿不同,区向下然后横穿然后向下的累加只在东北地区范围内累加,中南地区广东的数据还是原值,没有受到东北地区的影响。
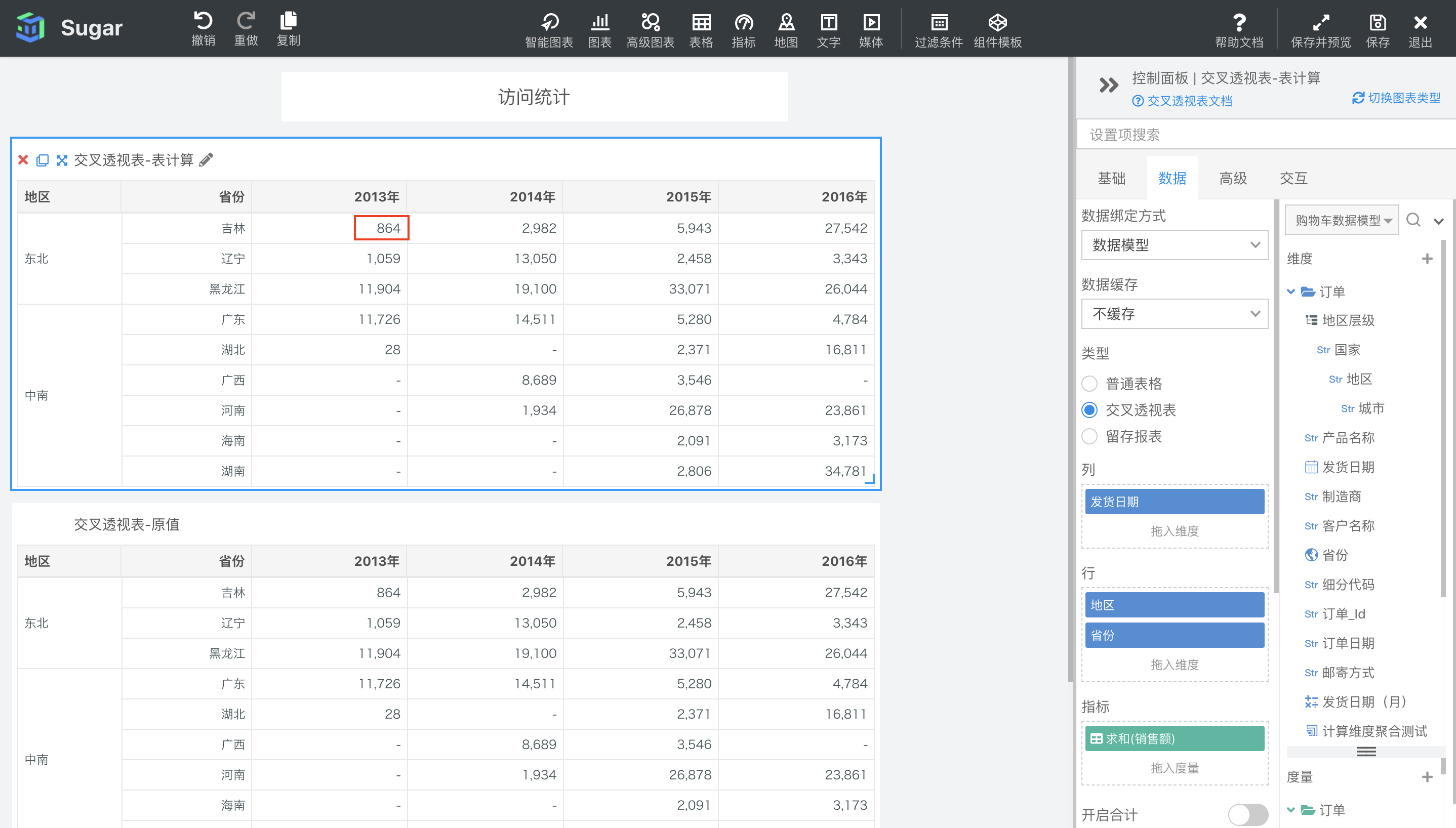
单元格
单元格就是以每一个单元格为一个分区,在单元格内进行表计算。在快速表计算为累计和的例子中,单元格分区内只有自身值,所以累计和还是自身值,可以看到下图中,表一和表二数据是相同的。
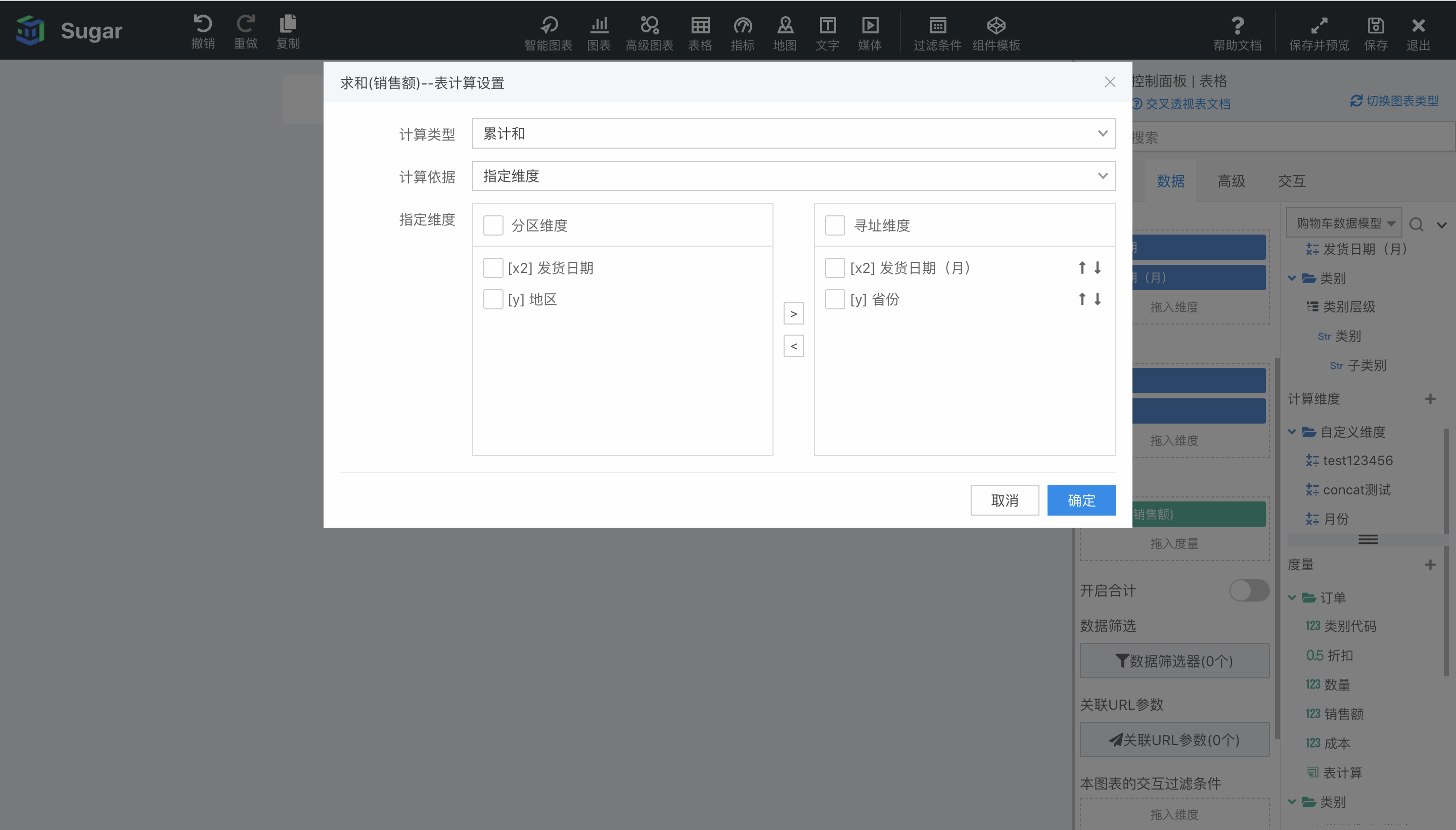
指定维度
指定维度的选择和配置在度量的右键菜单表计算设置中,如下图所示,可以看到指定维度的选择是一个穿梭框,列出了当前图表绑定的所有维度。选中维度前面的复选框,再点击穿梭框中间的小箭头,就可以将选中的维度移动到分区维度框中或寻址维度框中。也可以勾选分区维度和寻址维度左侧的复选框,全选。
此外,每个维度后面有一个向上的箭头和一个向下的箭头,这两个箭头可以调整维度的顺序,因为维度的顺序影响着表计算的分区和寻址。
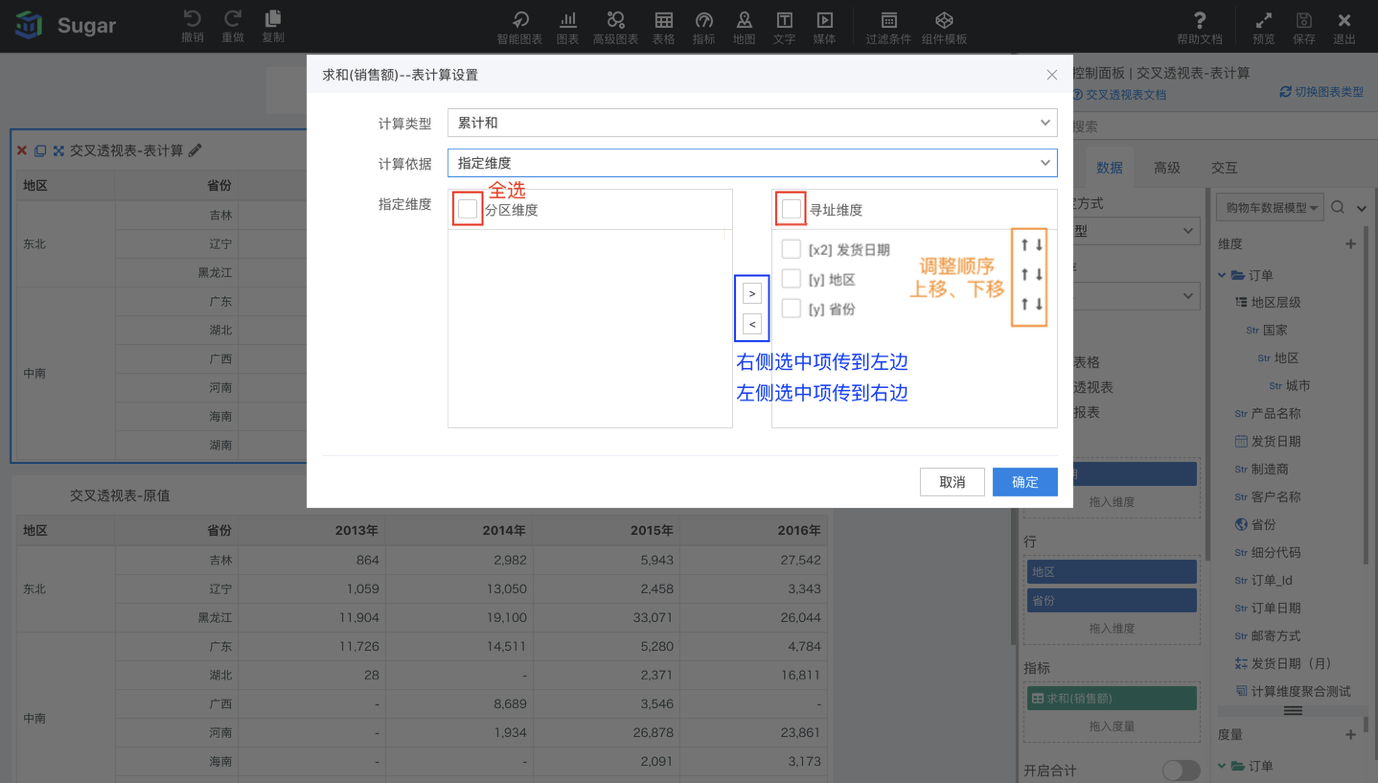
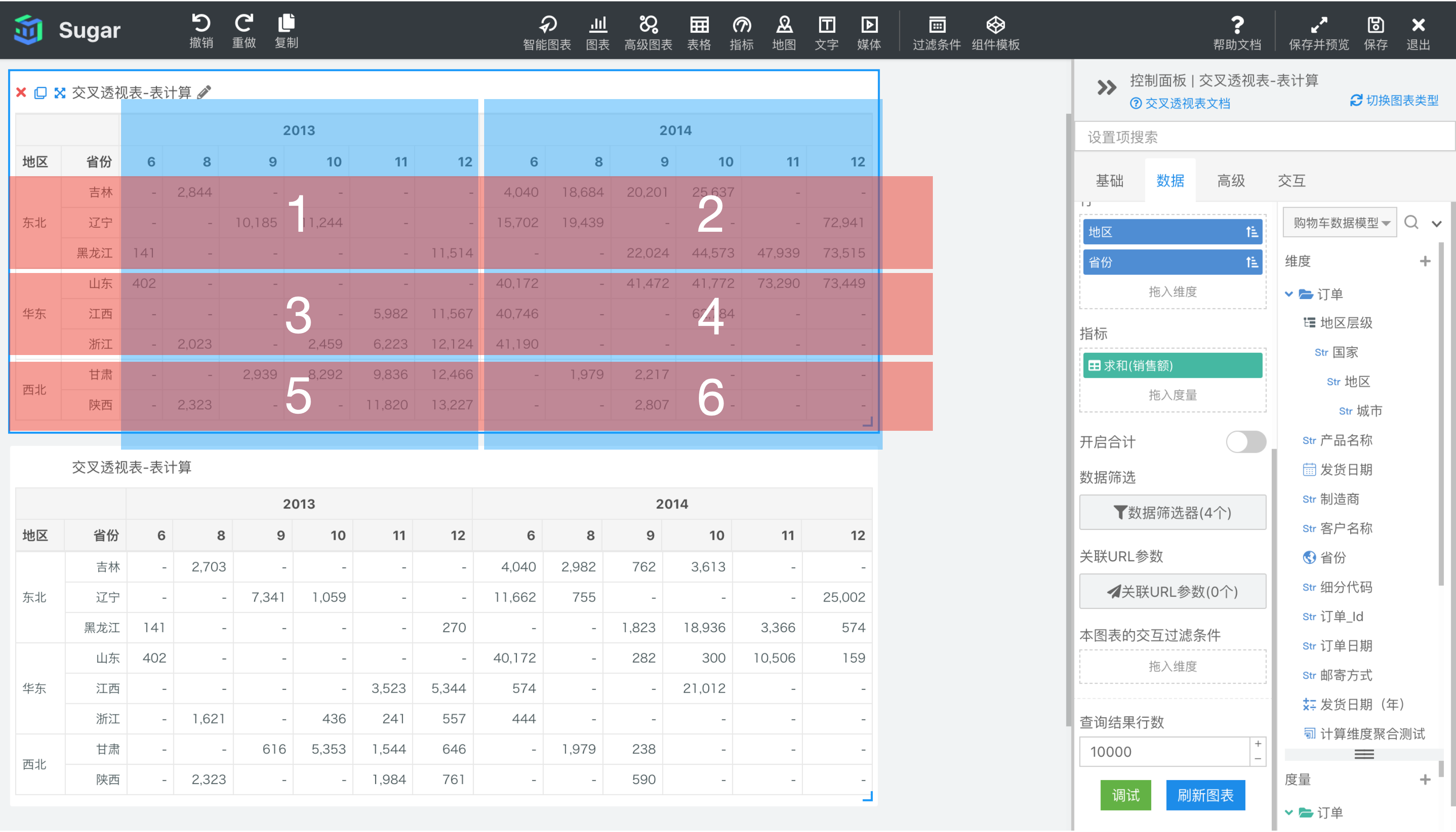
分区和寻址有几种理解方式,简要阐述下,方便您的理解。以下图的指定维度设置为例,分区维度为发货日期和地区,寻址维度为发货日期(月)和省份。
- 根据分区和寻址方向在原表上分析。如下图所示,目前交叉透视表绑定的列维度是发货日期(年)和发货日期(月),行维度是地区和省份。如果我们选择分区维度为地区和发货日期(年),那么分区就是这两个维度每个取值的相交的区域,也就是下图中红色部分与蓝色部分相交产生的 6 个紫色区域。
寻址方向是发货日期(月)和省份,需要注意寻址方向是有严格的先后顺序的,计算方向是先找最后一个寻址维度的值,再找倒数第二个寻址维度的值,最后找第一个寻址维度的值,以此类推。也就是说先找到省份的值,再找发货日期(月)的值。具体来说,在上图 2013 年份和东北地区确定的分区 1 中,第一个单元格是 6 月份吉林省的数据,会先找 6 月份下不同省份的值,所以第二个计算到的单元格是 6 月份辽宁省的数据,再接下来是 6 月份黑龙江省的数据。找完分区中 6 月份所有省份的值之后,再去找下一个月份也就是 8 月。然后再沿着 8 月的列找出分区中所有 8 月和不同省份对应的单元格,接着找到下一个月份,以此类推,实际上就是区向下然后横穿的效果。
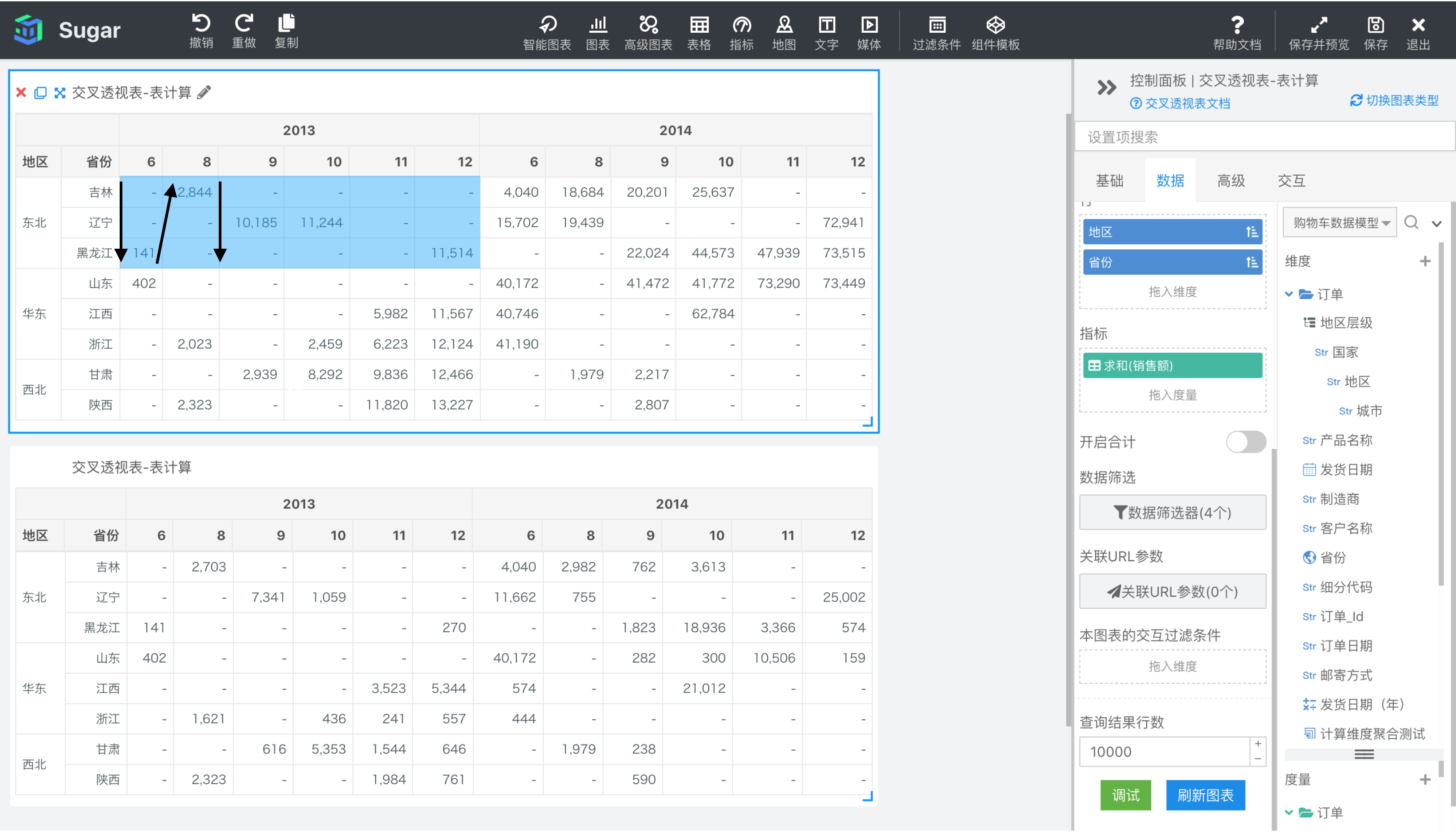
如果我们把寻址方向反过来,先省份再发货日期(月),就会先找到吉林省 6 月份的值,然后沿着分区内吉林省对应的行,找到所有发货日期(月)对应的单元格,再找下一个省份辽宁,以此类推,实际上就是区横穿然后向下的效果。
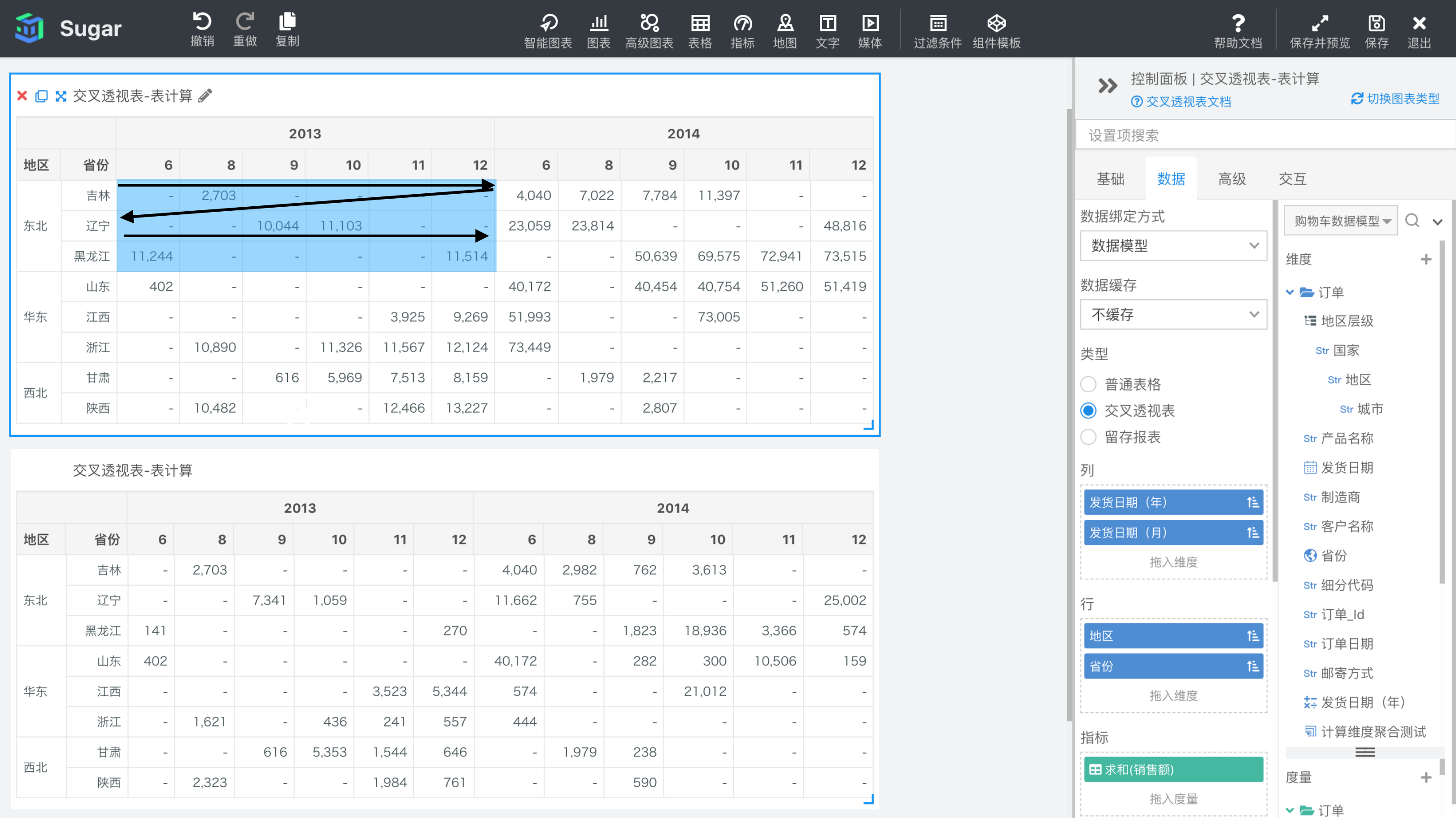
- 第一种方式是理解性的,第二种方式可以看到实际的分区寻址效果。在分区和寻址维度比较多,不好理解时,就可以通过这种方式简单粗暴的看出分区和寻址方向,同时也可以方便检验您通过第一种方式推理的是否正确。
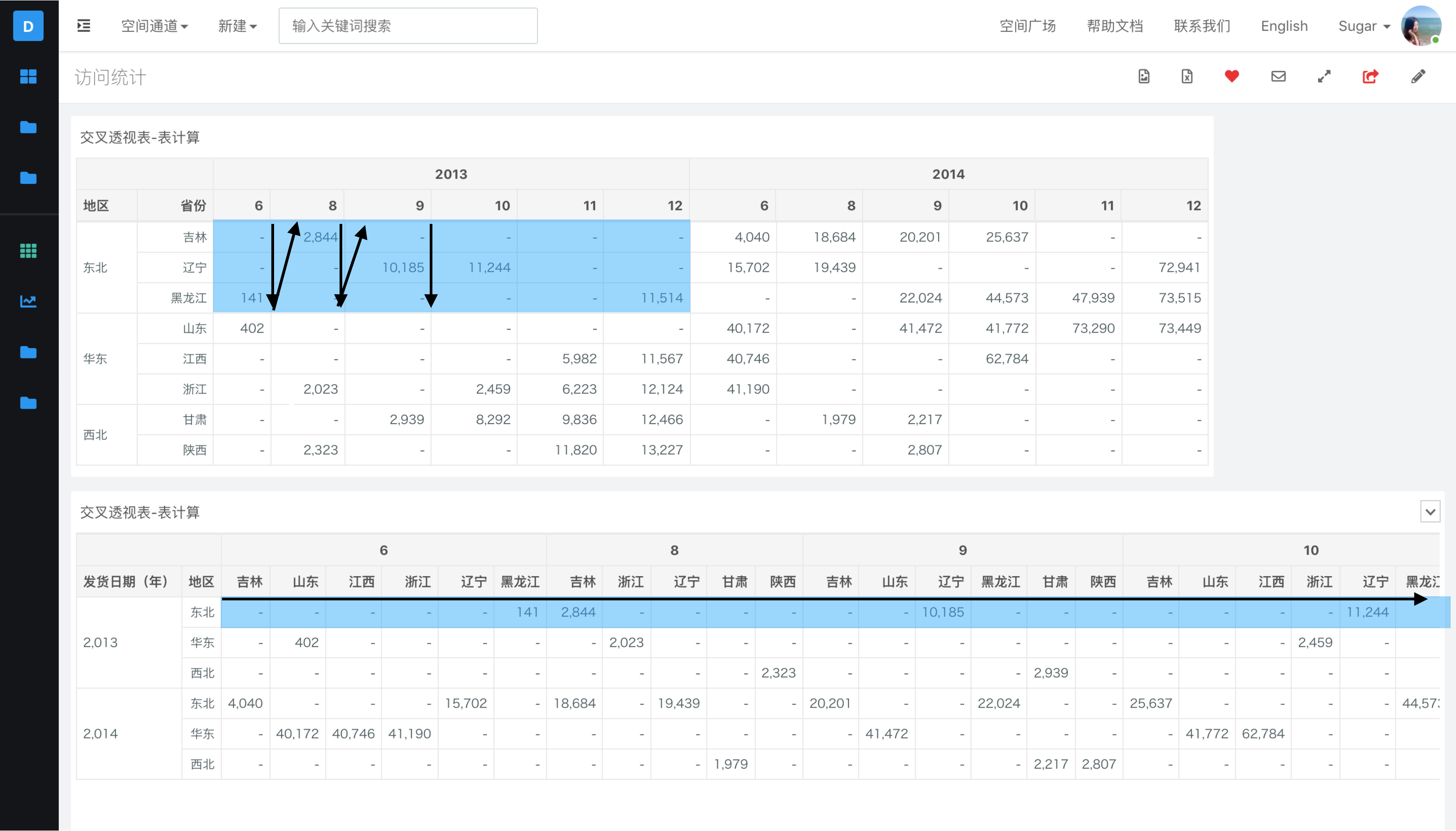
我们可以新建一个交叉透视表,以分区维度作为行维度,寻址维度作为列维度,画交叉透视表。然后取表横穿方向,就是当前设定是指定维度的计算方式。比如方法 1 中的举例,我们就可以以地区和发货日期(年)作为行维度,发货日期(月)和省份作为列维度,绘制交叉透视表,如下图所示。表二是按照表一的指定维度重新绘制的交叉透视表,可以看到表一的分区和寻址方向等同于表二表横穿的分区和寻址方向。
表计算字段
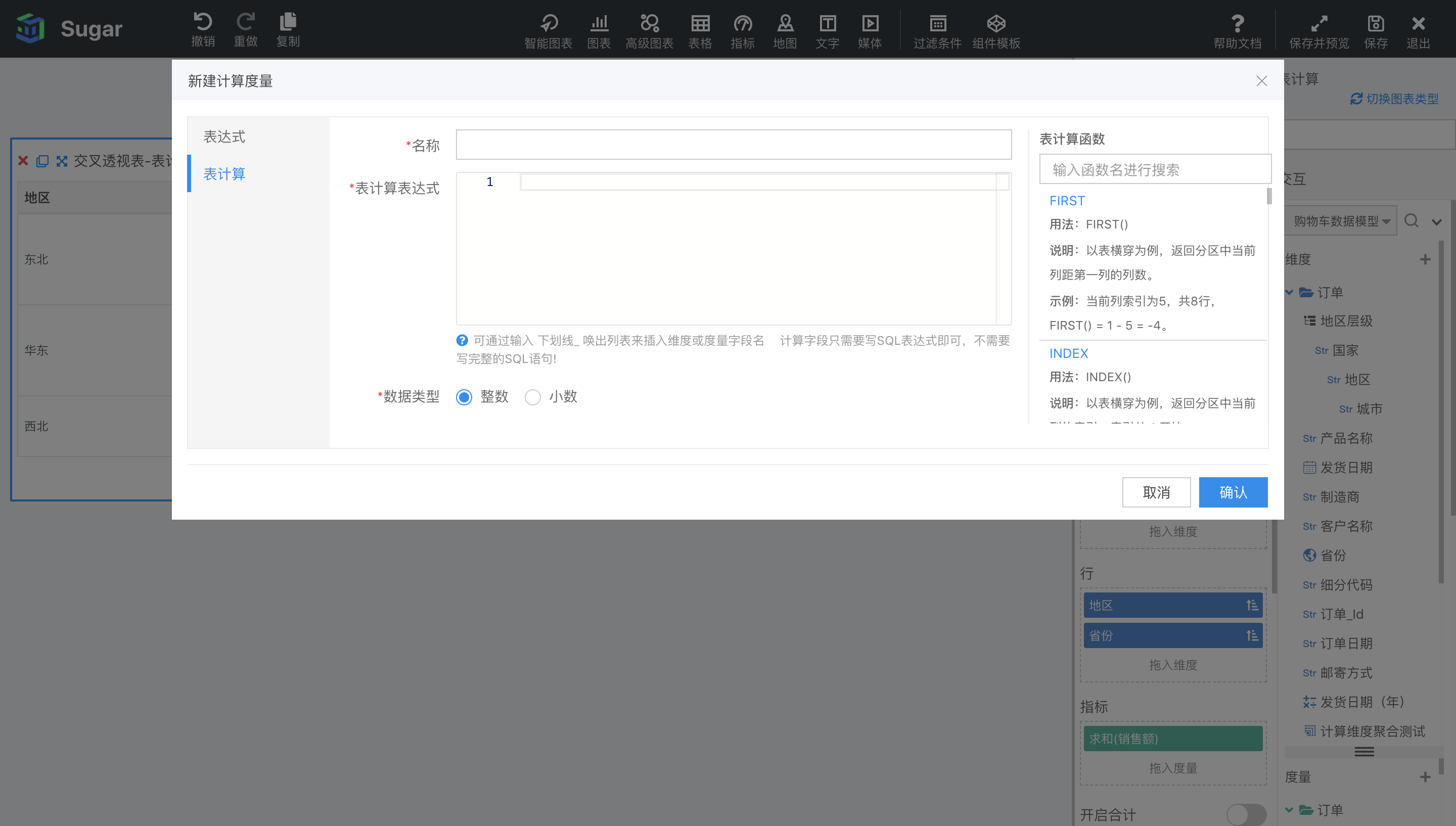
除了快速表计算提供的 8 种计算方式,还可以通过新建表计算字段的方式,使用 Sugar BI 中内置的几十种表计算函数来自定义表计算。您可以在数据模型编辑页或者报表大屏新建计算度量,在编辑器中选择表计算,请注意表计算字段必须是度量。
如下图所示,编辑器的右边列出了所有 Sugar BI内置的表计算函数的用法说明,在表计算表达式中只能使用这些表计算函数。
此外,表计算表达式内部支持写计算字段表达式,但引用的字段必须是使用聚合函数聚合了的度量字段,不支持引入维度字段,也不支持嵌套其它计算字段。
比如可以用表计算字段实现快速表计算中的百分比差异计算:((SUM({销售额}) - LOOKUP(SUM({销售额}), -1)) / LOOKUP(SUM({销售额}), -1))) * 100
对于表计算字段来说,同快速表计算一样,支持设置计算依据。
截下来详细介绍下 Sugar BI中支持的各个表计算函数的用法。
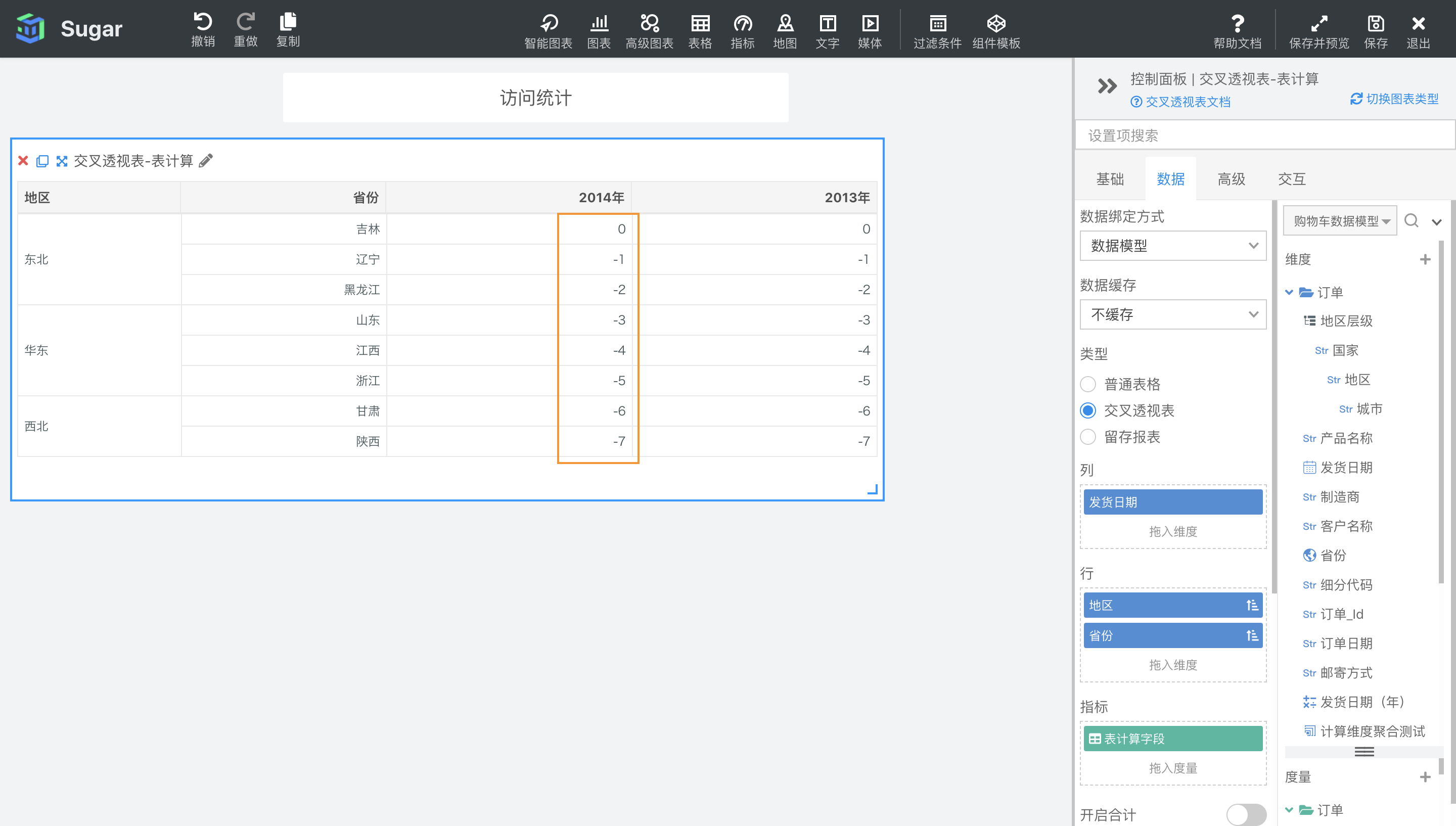
FIRST()
返回分区中当前项距离第一项的项数。公式为 1 - 当前项的索引。
示例:计算依据为表向下,计算字段设置为FIRST(),结果如下图所示。
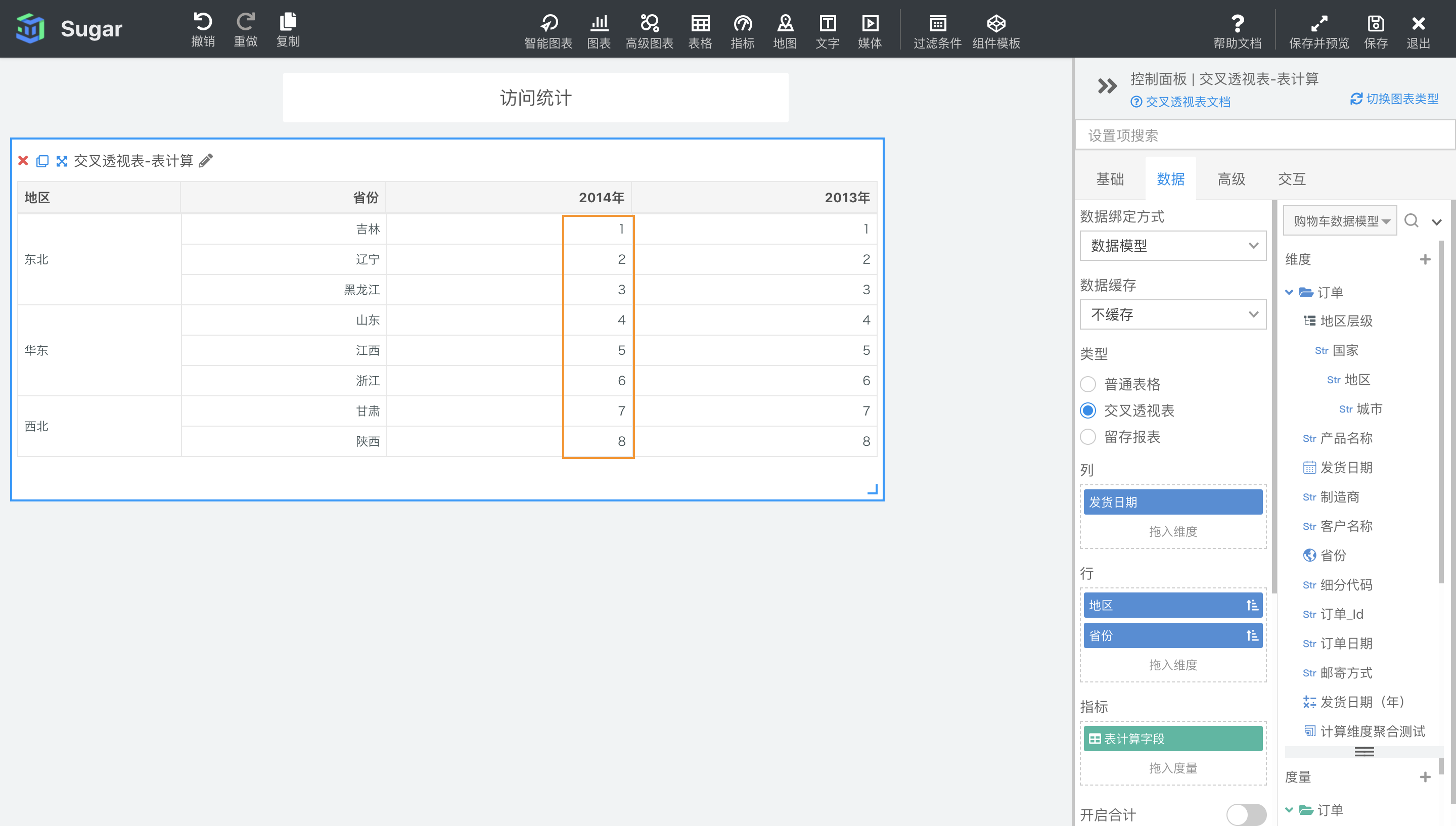
INDEX()
返回分区中当前项当前项的索引。
示例:计算依据为表向下,计算字段设置为INDEX(),结果如下图所示。
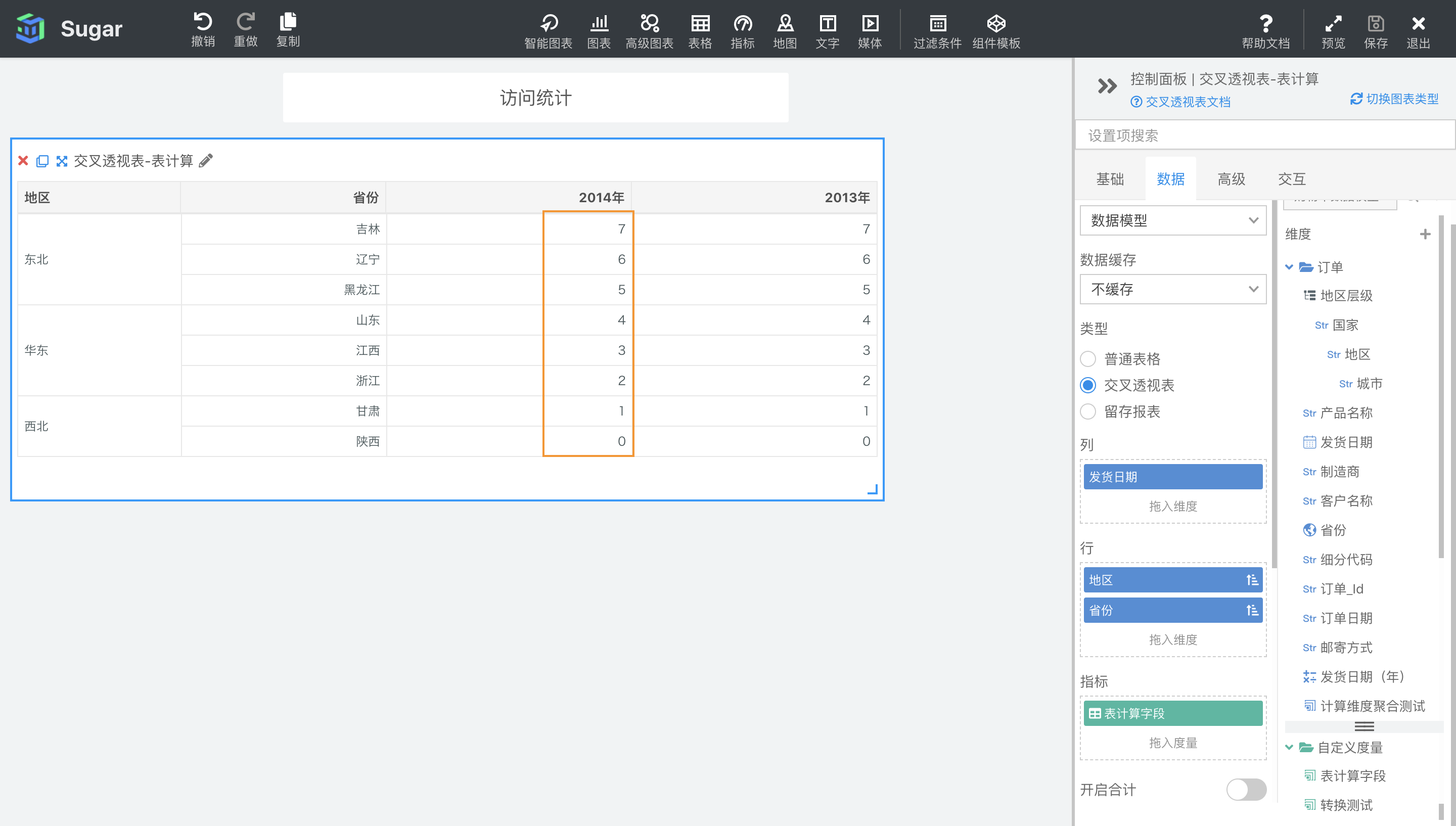
LAST()
返回分区中当前项距离最后一项的项数。公式为 分区总项数 - 当前项的索引。
示例:计算依据为表向下,计算字段设置为LAST(),结果如下图所示。
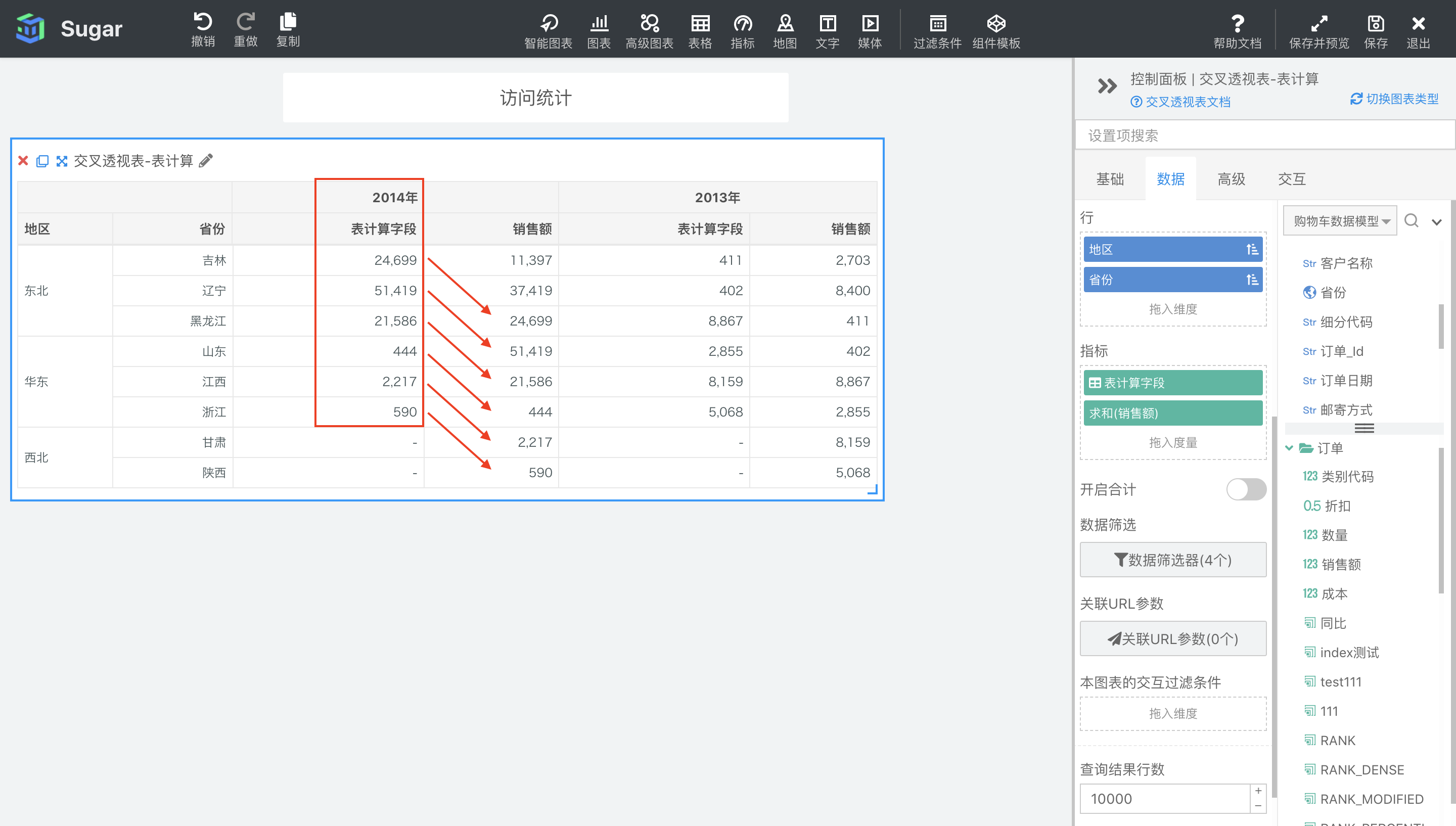
LOOKUP(expression, [offset])
返回当前分区中,当前项偏移 offset 之后的项对应的表达式 expression 的值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。offset 是偏移量,不填表示当前项,可以输入数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。
示例:计算依据为表向下,表计算表达式为LOOKUP(SUM({销售额}), 2),意思是返回分区中当前项往后数两项对应的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到LOOKUP(SUM({销售额}), 2)的每项值与SUM({销售额})之间的偏移关系。
PREVIOUS_VALUE(expression)
返回当前分区中,上一项对应的表达式 expression 的值。相当于LOOKUP(SUM({销售额}), -1)
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
RANK(expression, ['asc'|'desc'])
根据表达式 expression 返回当前项在分区中的竞争排名。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。第二个参数为排序方式,不填默认为降序。
示例:假设当前分区内所有项对应表达式的值为 [5, 3, 5, 10], 那么降序的竞争排名为 [2, 4, 2, 1]。
RANK_DENSE(expression, ['asc'|'desc'])
根据表达式 expression 返回当前项在分区中的密集排名。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。第二个参数为排序方式,不填默认为降序。
示例:假设当前分区内所有项对应表达式的值为 [5, 3, 5, 10], 那么降序的竞争排名为 [2, 3, 2, 1]。
RANK_MODIFIED(expression, ['asc'|'desc'])
根据表达式 expression 返回当前项在分区中修改过的的竞争排名。与 RANK 竞争排名不同的是,RANK_MODIFIED 会为相同的排名分配更大的值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。第二个参数为排序方式,不填默认为降序。
示例:假设当前分区内所有项对应表达式的值为 [5, 3, 5, 10], 那么降序的排名为 [3, 4, 3, 1]。
RANK_UNIQUE(expression, ['asc'|'desc'])
根据表达式 expression 返回当前项在分区中唯一排名。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。第二个参数为排序方式,不填默认为降序。
示例:假设当前分区内所有项对应表达式的值为 [5, 3, 5, 10], 那么降序的唯一排名为 [2, 4, 3, 1]。
RANK_PERCENTILE(expression, ['asc'|'desc'])
根据表达式 expression 返回当前项在分区中百分等级。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。第二个参数为排序方式,不填默认为降序。
假设当前分区内所有项对应表达式的值为 [5, 3, 5, 10], 那么降序的百分位为 [0.67, 1.00, 0.67, 0.00]。
RUNNING_AVG(expression)
运行平均值,根据表达式 expression 返回分区中第一项到当前项的平均值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为表向下,表计算表达式为RUNNING_AVG(SUM({销售额})),返回分区中第一项到当前项的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到RUNNING_AVG(SUM({销售额}))的每项值与SUM({销售额})之间的计算关系。
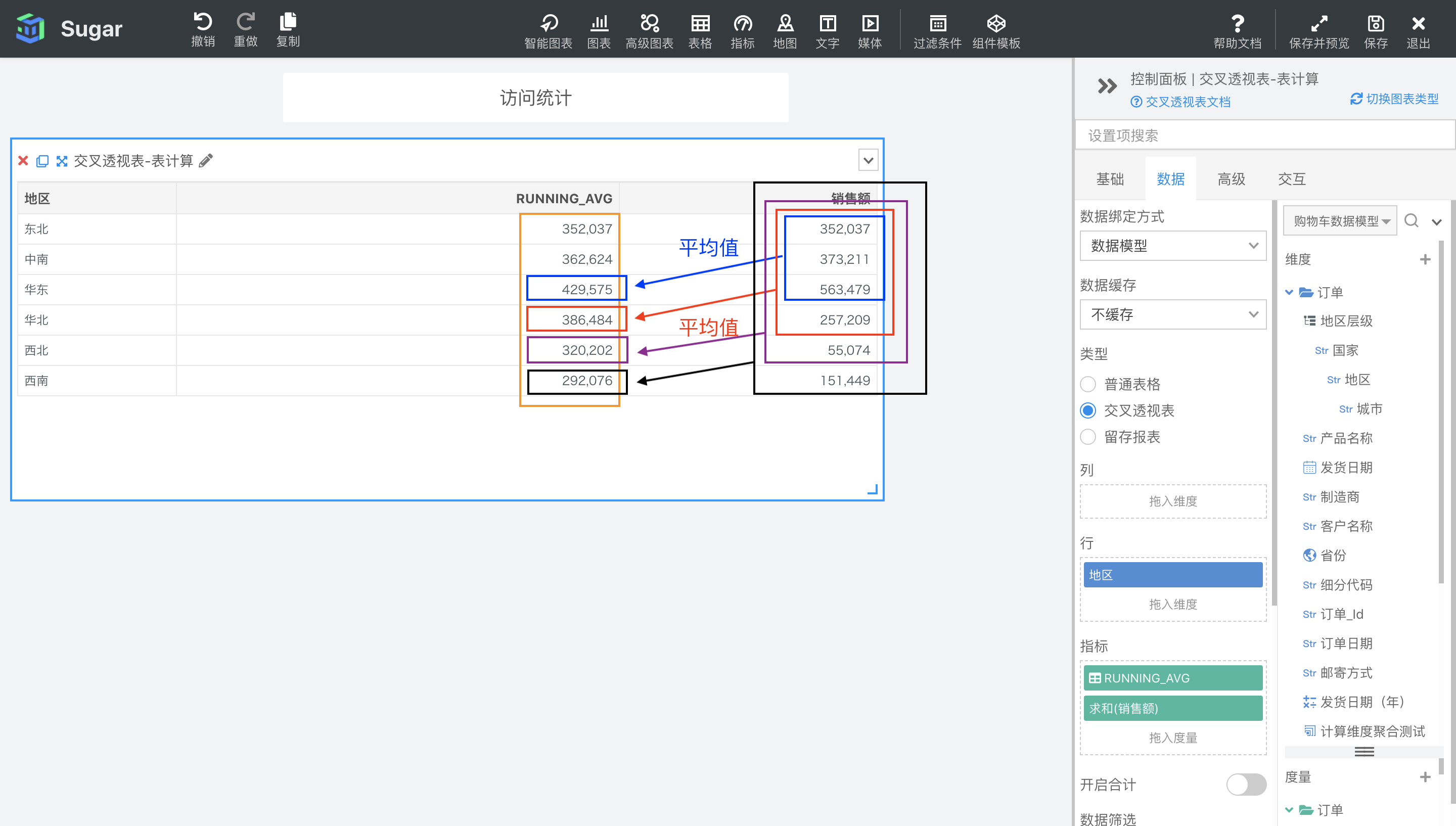
RUNNING_COUNT(expression)
运行计数,根据表达式 expression 返回分区中第一项到当前项的计数。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为表向下,表计算表达式为RUNNING_COUNT(SUM({销售额})),返回分区中第一项到当前项的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到RUNNING_COUNT(SUM({销售额}))的每项值与SUM({销售额})之间的计算关系。
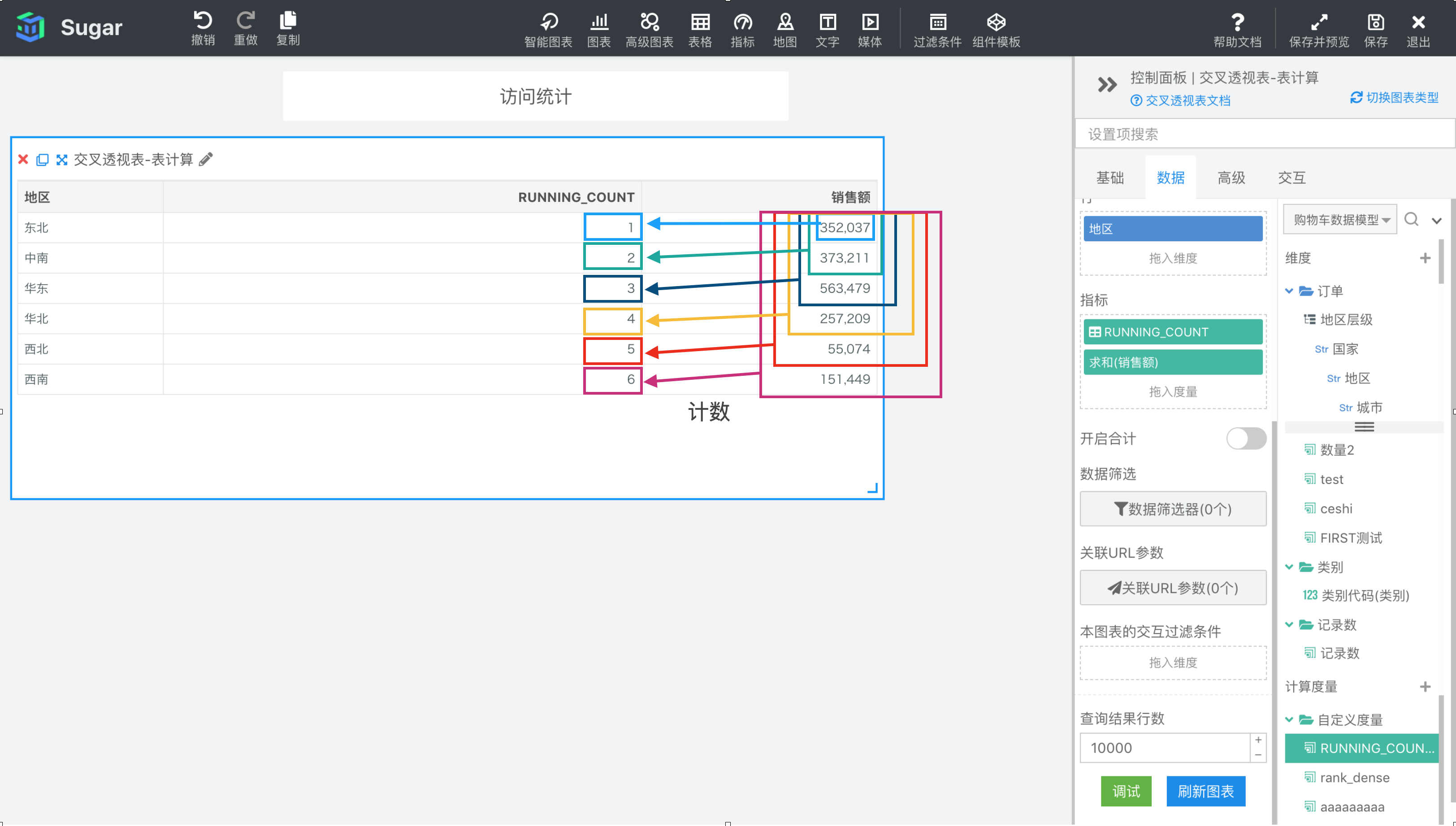
RUNNING_MAX(expression)
运行最大值,根据表达式 expression 返回分区中第一项到当前项的最大值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为表向下,表计算表达式为RUNNING_MAX(SUM({销售额})),返回分区中第一项到当前项的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到RUNNING_MAX(SUM({销售额}))的每项值与SUM({销售额})之间的计算关系。
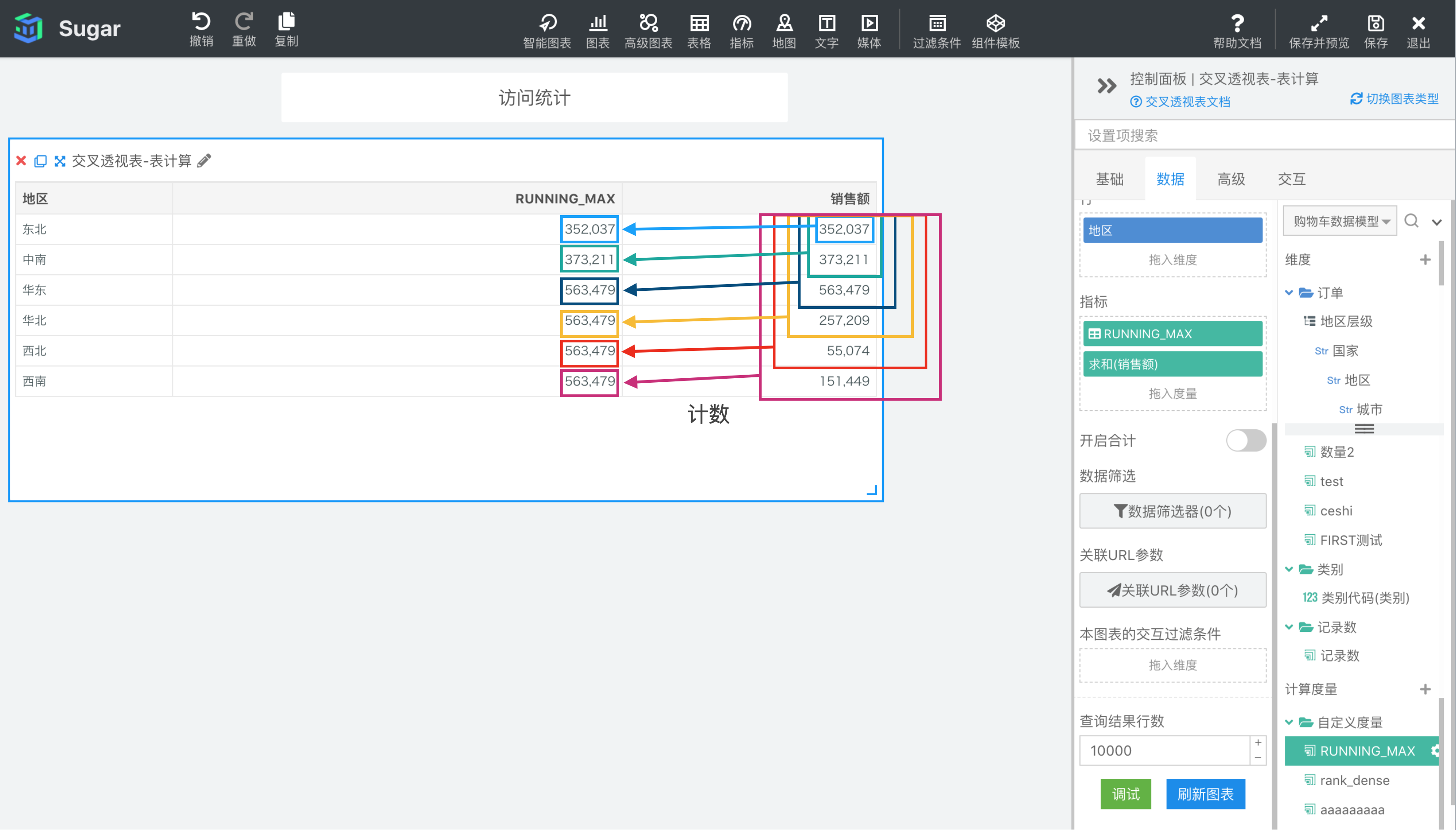
RUNNING_MIN(expression)
运行最小值,根据表达式 expression 返回分区中第一项到当前项的最小值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为表向下,表计算表达式为RUNNING_MIN(SUM({销售额})),返回分区中第一项到当前项的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到RUNNING_MIN(SUM({销售额}))的每项值与SUM({销售额})之间的计算关系。
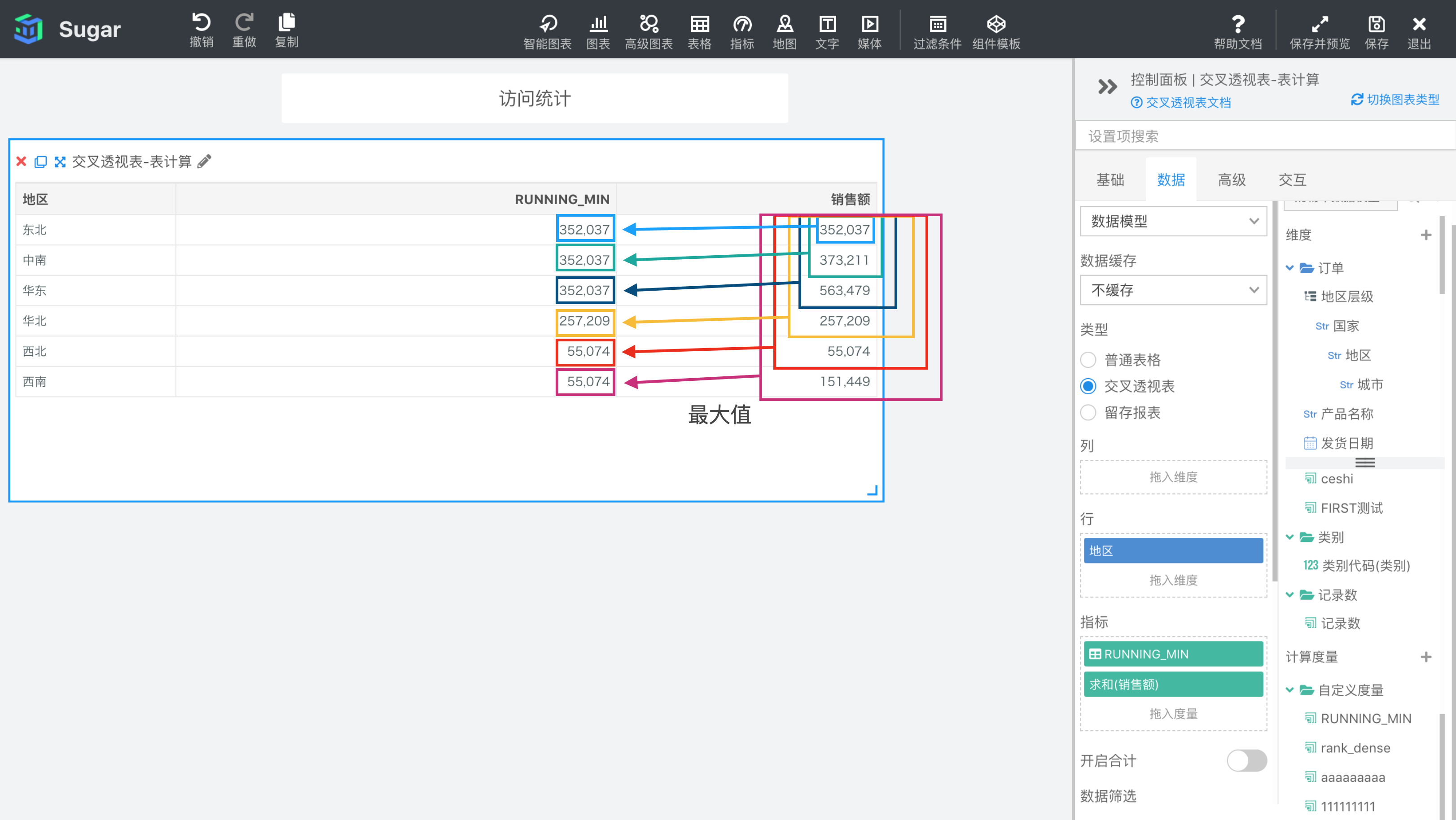
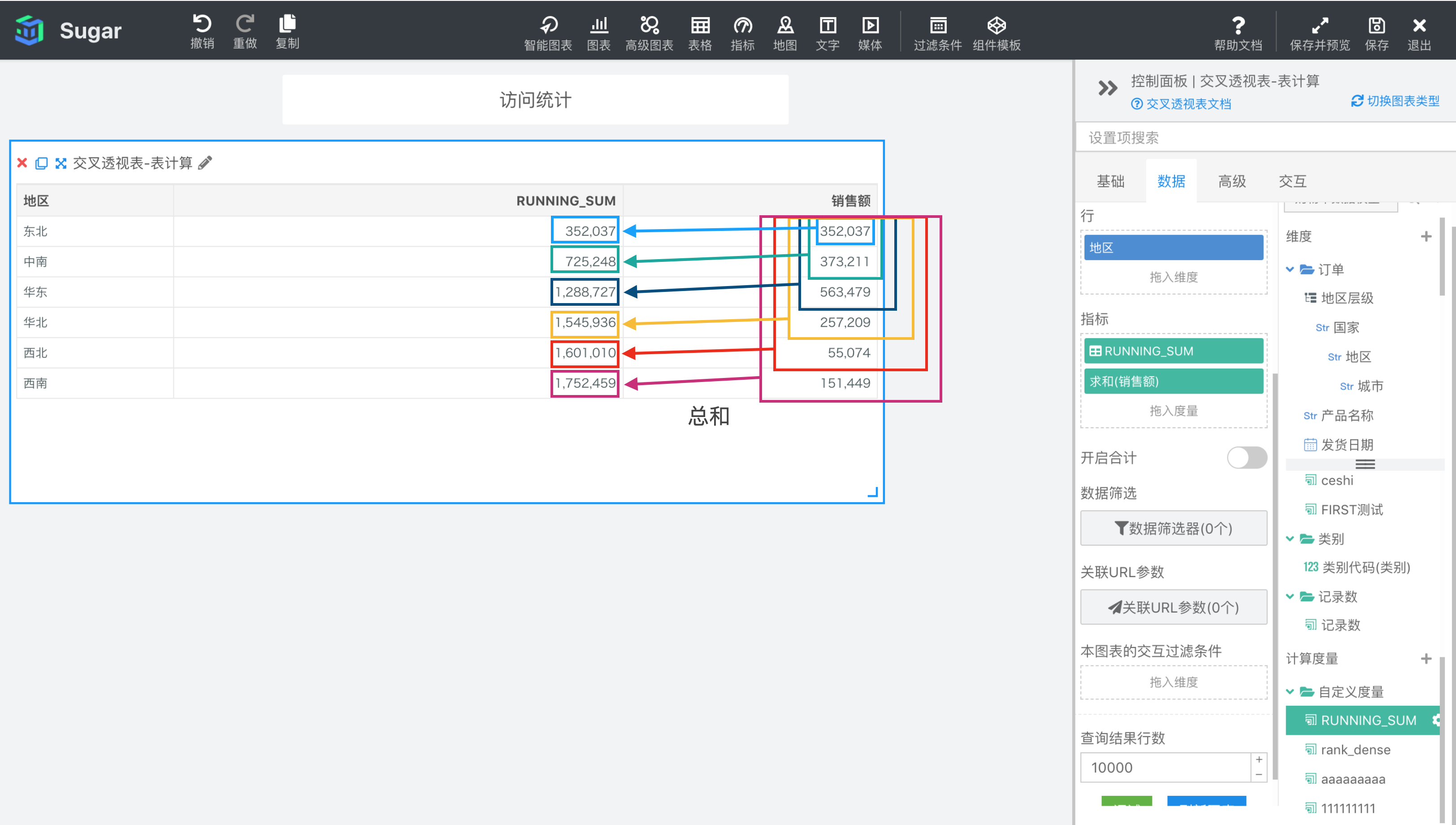
RUNNING_SUM(expression)
运行总计,根据表达式 expression 返回分区中第一项到当前项的总计和。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为表向下,表计算表达式为RUNNING_SUM(SUM({销售额})),返回分区中第一项到当前项的 SUM({销售额})。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),可以很清楚的观察到RUNNING_SUM(SUM({销售额}))的每项值与SUM({销售额})之间的计算关系。
SIZE()
返回当前分区的项数。
示例:计算依据为区向下,表计算表达式为SIZE(),返回分区中的总项数。如下图所示,红色和蓝色相交的部分为分区(区向下具体分区和寻址请参照计算依据章节),顺着白色箭头向下,分区内的项数就是图中相交部分的行数。
TOTAL(expression)
返回分区内表达式的总计和。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。
示例:计算依据为区向下,表计算表达式为TOTAL(SUM({销售额})),返回分区中的总项数。如下图所示,红色和蓝色相交的部分为分区(区向下具体分区和寻址请参照计算依据章节),顺着白色箭头向下,TOTAL(SUM({销售额}))就是图中相交部分SUM({销售额})各项的总和。
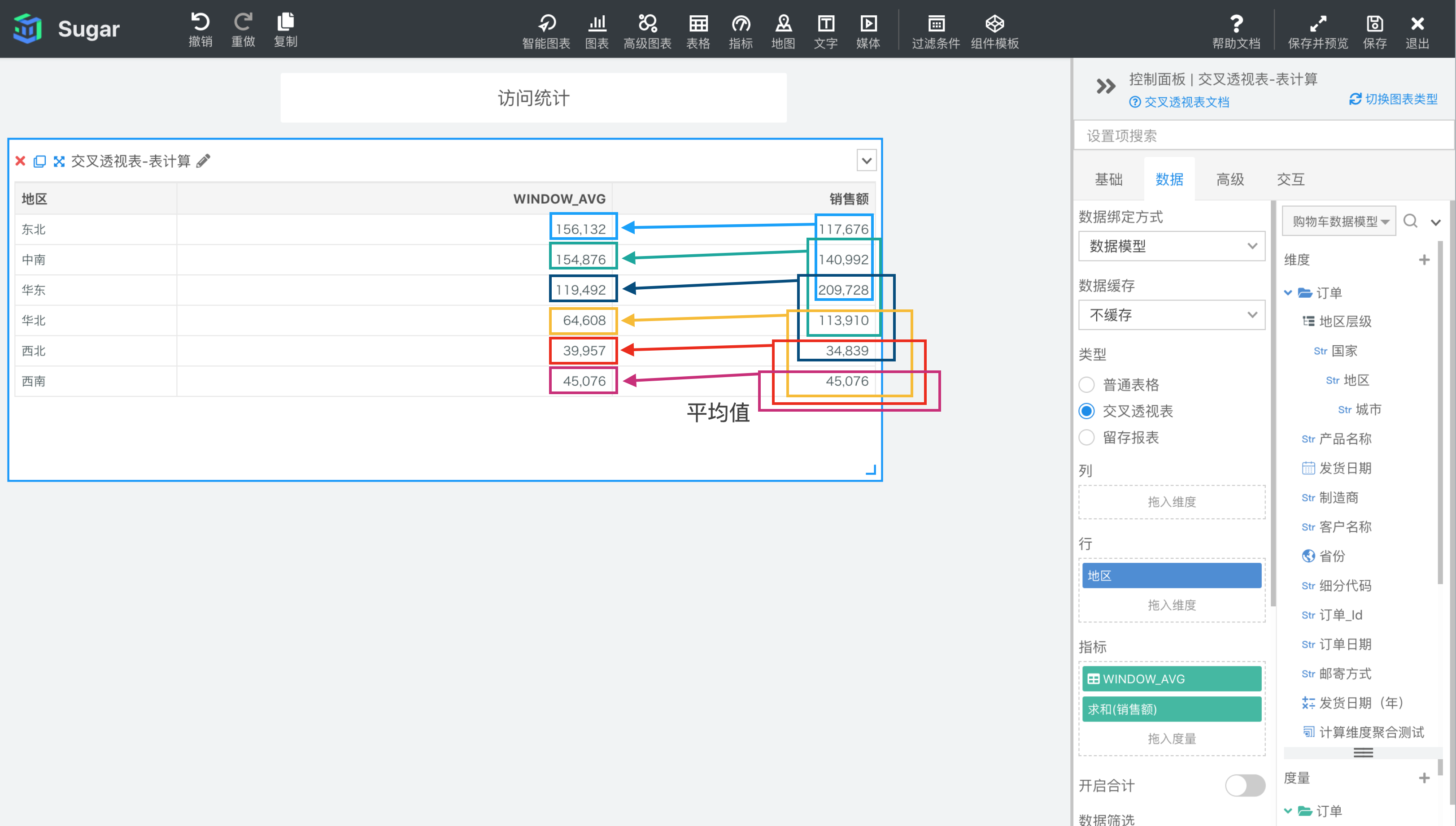
WINDOW_AVG(expression, [start, end])
根据表达式 expression 返回分区中从 start 到 end 所形成的窗口中的项的平均值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_AVG(SUM({销售额}), 0, 2)。结果如下图所示,start 为 0 表示当前项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,当前项东北到后面两项华东,蓝框部分对应的的SUM({销售额})的平均值就是表计算表达式的值。2013 年中南地区对应的窗口是红框部分,当前项到当前项后面两项即中南、华东和华北地区,表计算表达式的值就是红框中对应的的SUM({销售额})的平均值。
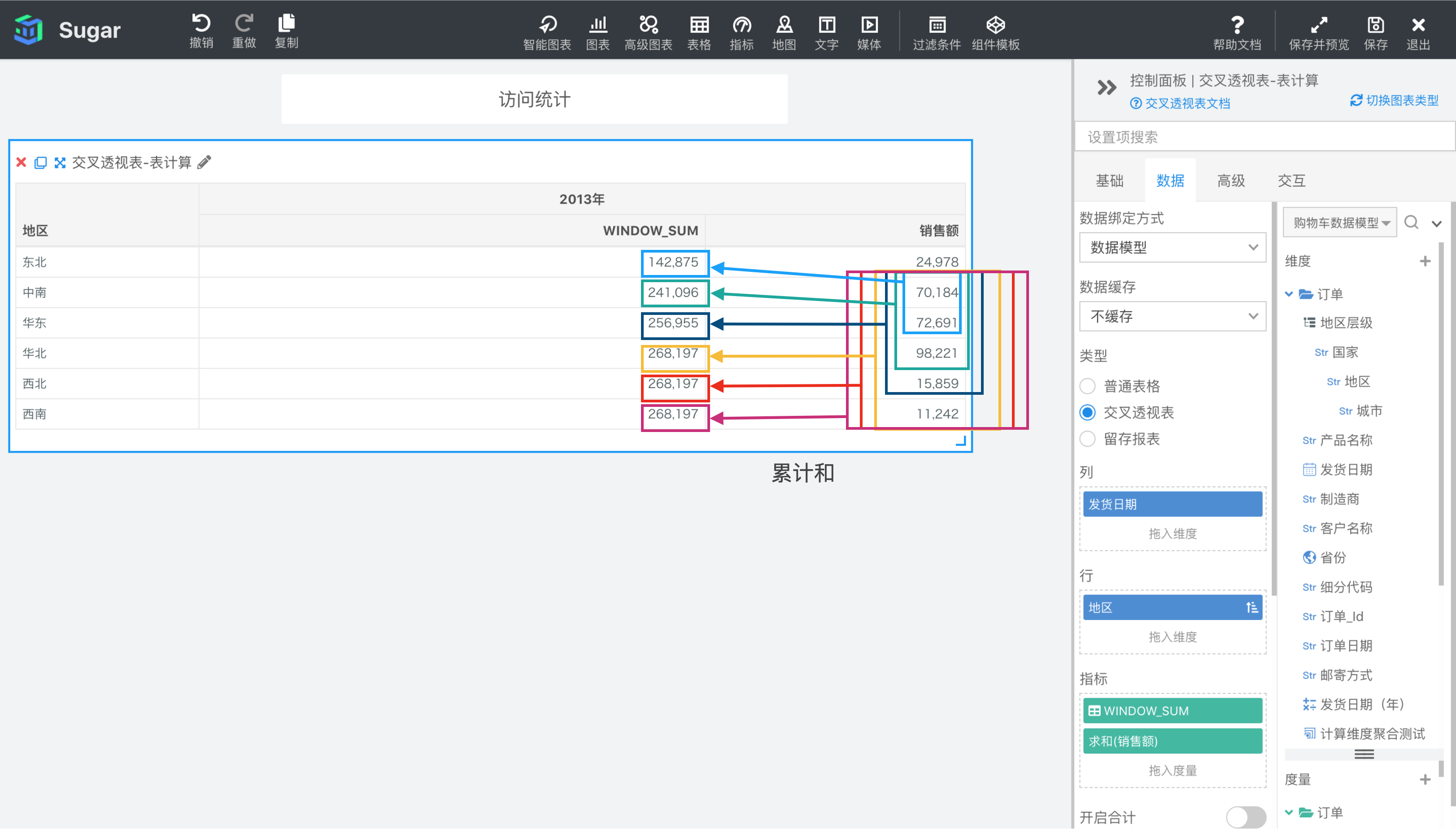
WINDOW_SUM(expression, [start, end])
根据表达式 expression 返回分区中从 start 到 end 所形成的窗口中的项的总和。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_SUM(SUM({销售额}), FIRST() + 1, 2)。start 为 FIRST() + 1 表示分区内第 2 项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,中南、华东 2013 年销售额的累计和。2013 年中南地区对应的就是分区内第 2 项中南——当前项后两项华北的累计和,以此类推,结果如下图所示。
WINDOW_COUNT(expression, [start, end])
根据表达式 expression 返回分区中从 start 到 end 所形成的窗口中的项的计数。
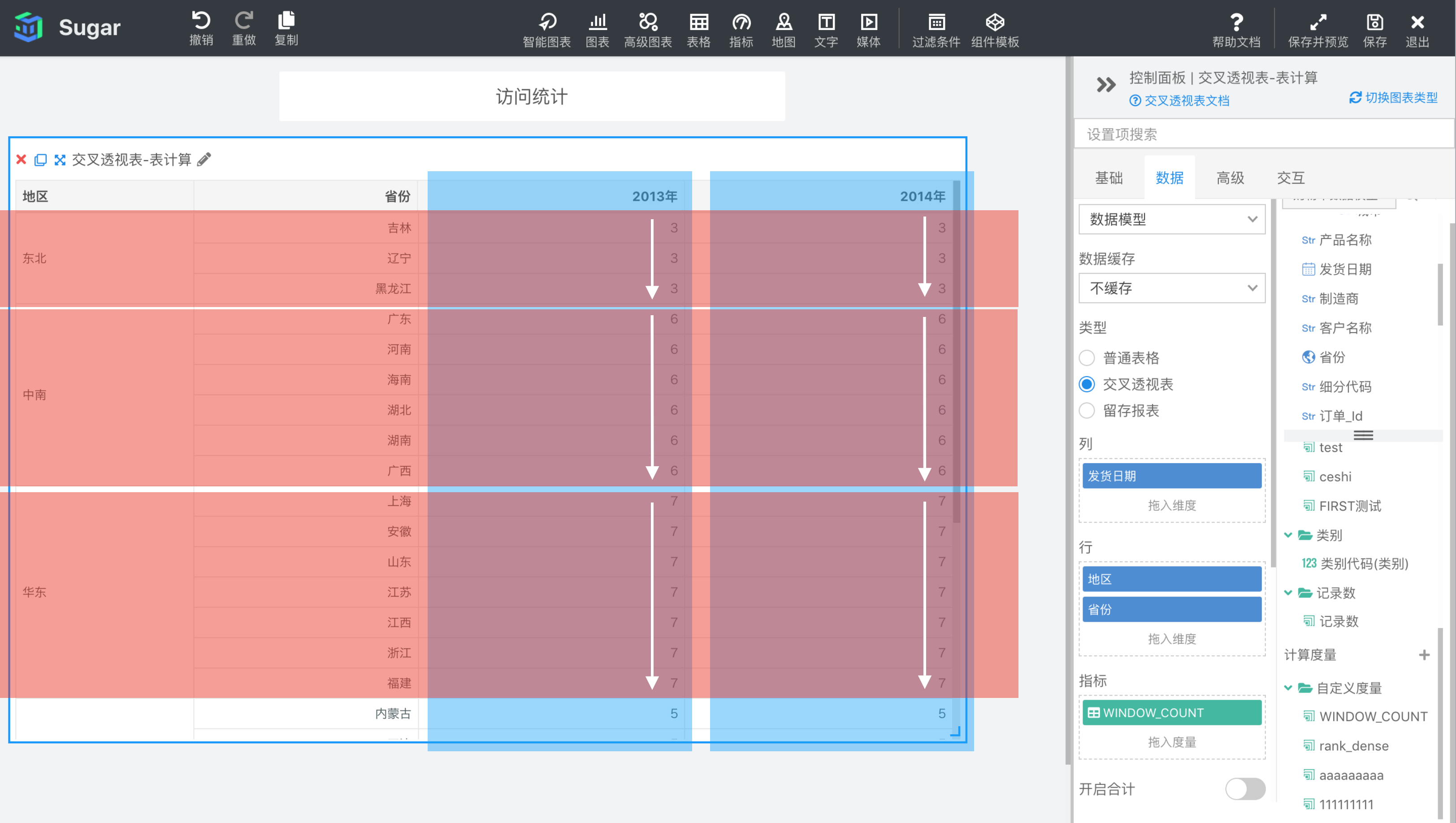
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为区向下,表计算表达式为WINDOW_COUNT(SUM({销售额}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,红色和蓝色相交的部分为分区(区向下具体分区和寻址请参照计算依据章节),顺着白色箭头向下WINDOW_COUNT(SUM({销售额}))就是图中相交部分计数。
WINDOW_MAX(expression, [start, end])
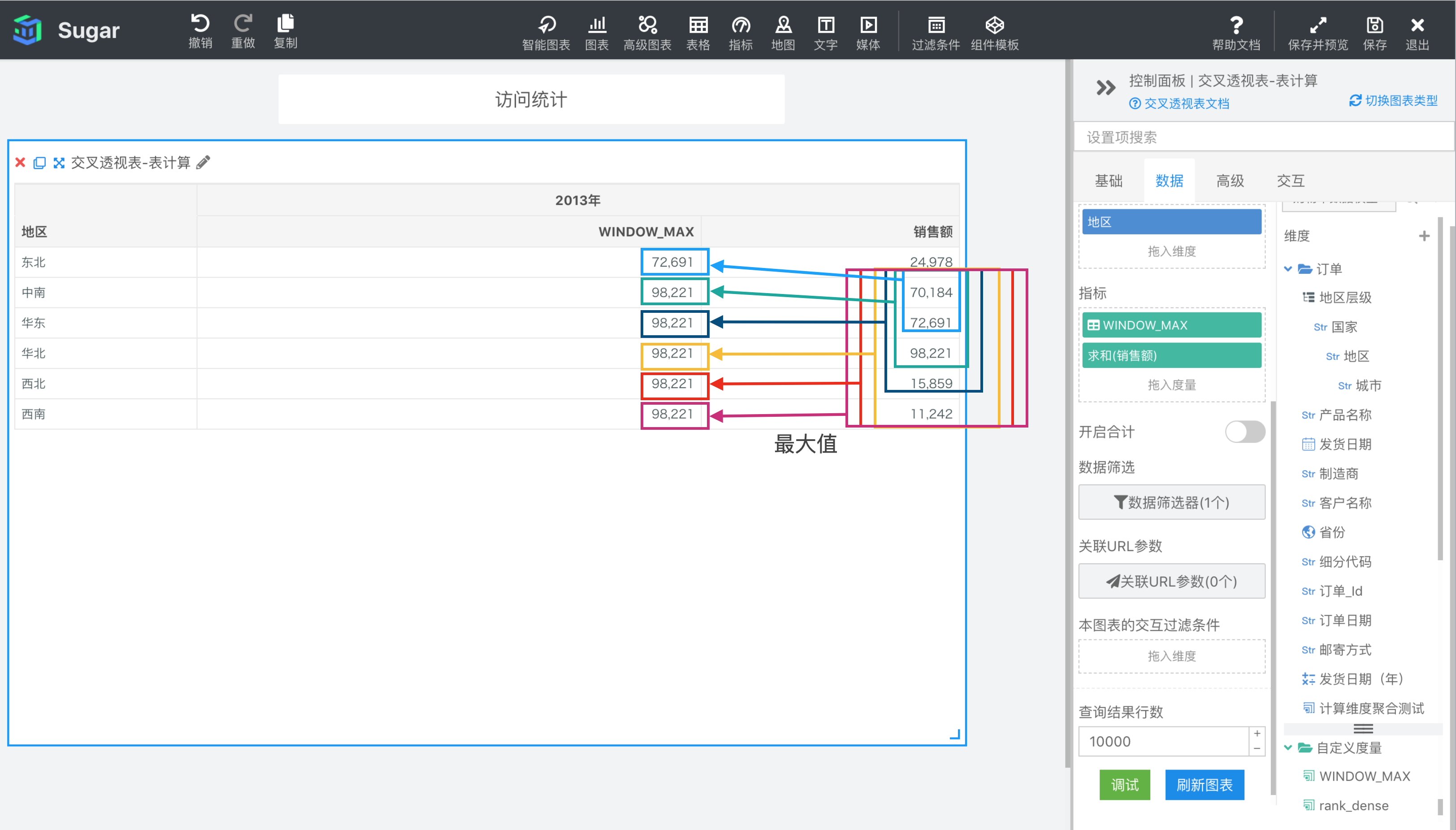
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的最大值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_MAX(SUM({销售额}), FIRST() + 1, 2)。start 为 FIRST() + 1 表示分区内第 2 项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,中南、华东 2013 年销售额的最大值。2013 年中南地区对应的就是分区内第 2 项中南——当前项后两项华北之间的最大值,以此类推,结果如下图所示。
WINDOW_MIN(expression, [start, end])
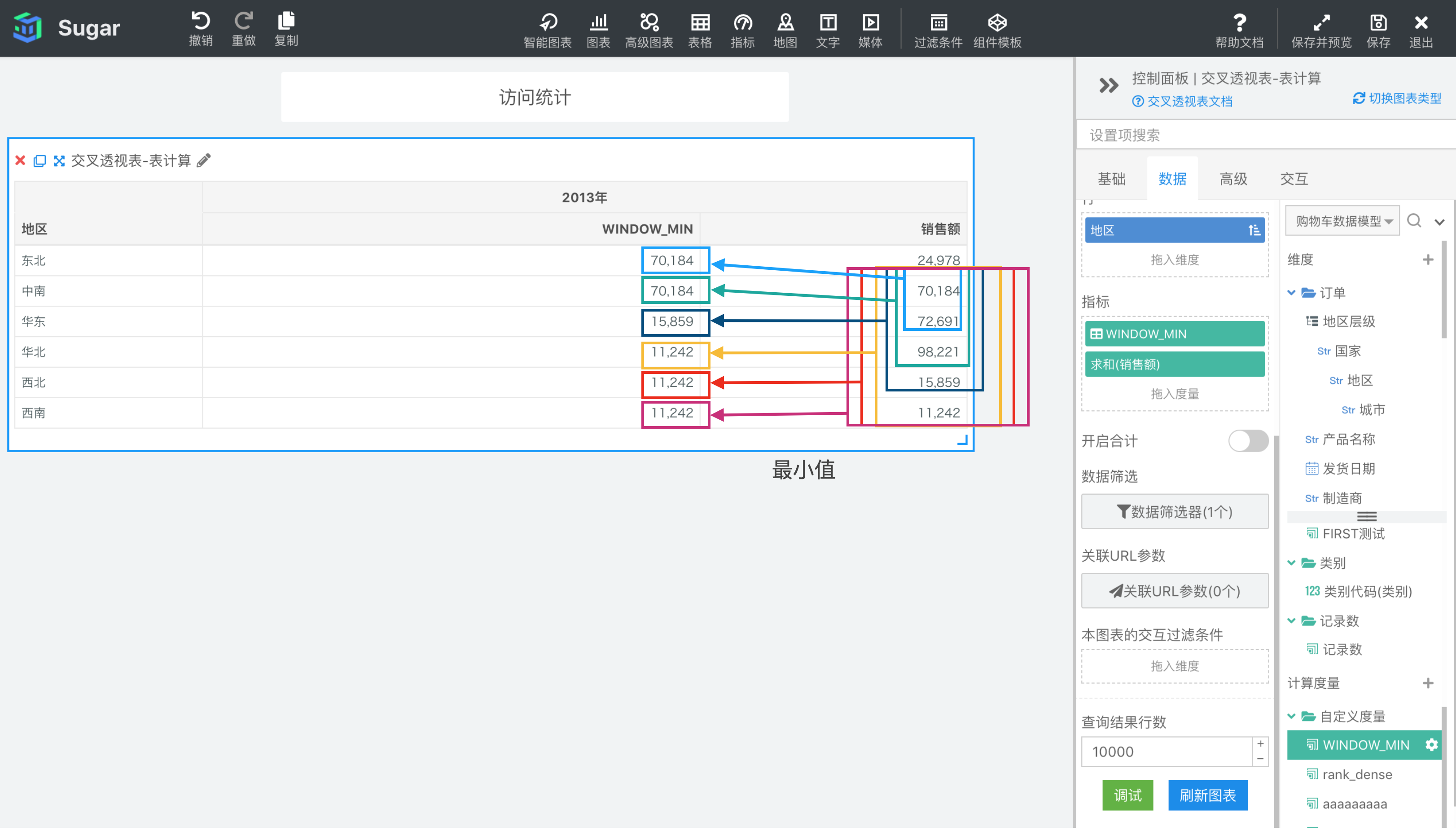
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的最小值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_MIN(SUM({销售额}), FIRST() + 1, 2)。start 为 FIRST() + 1 表示分区内第 2 项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,中南、华东 2013 年销售额的最小值。2013 年中南地区对应的就是分区内第 2 项中南——当前项后两项华北之间的最小值,以此类推,结果如下图所示。
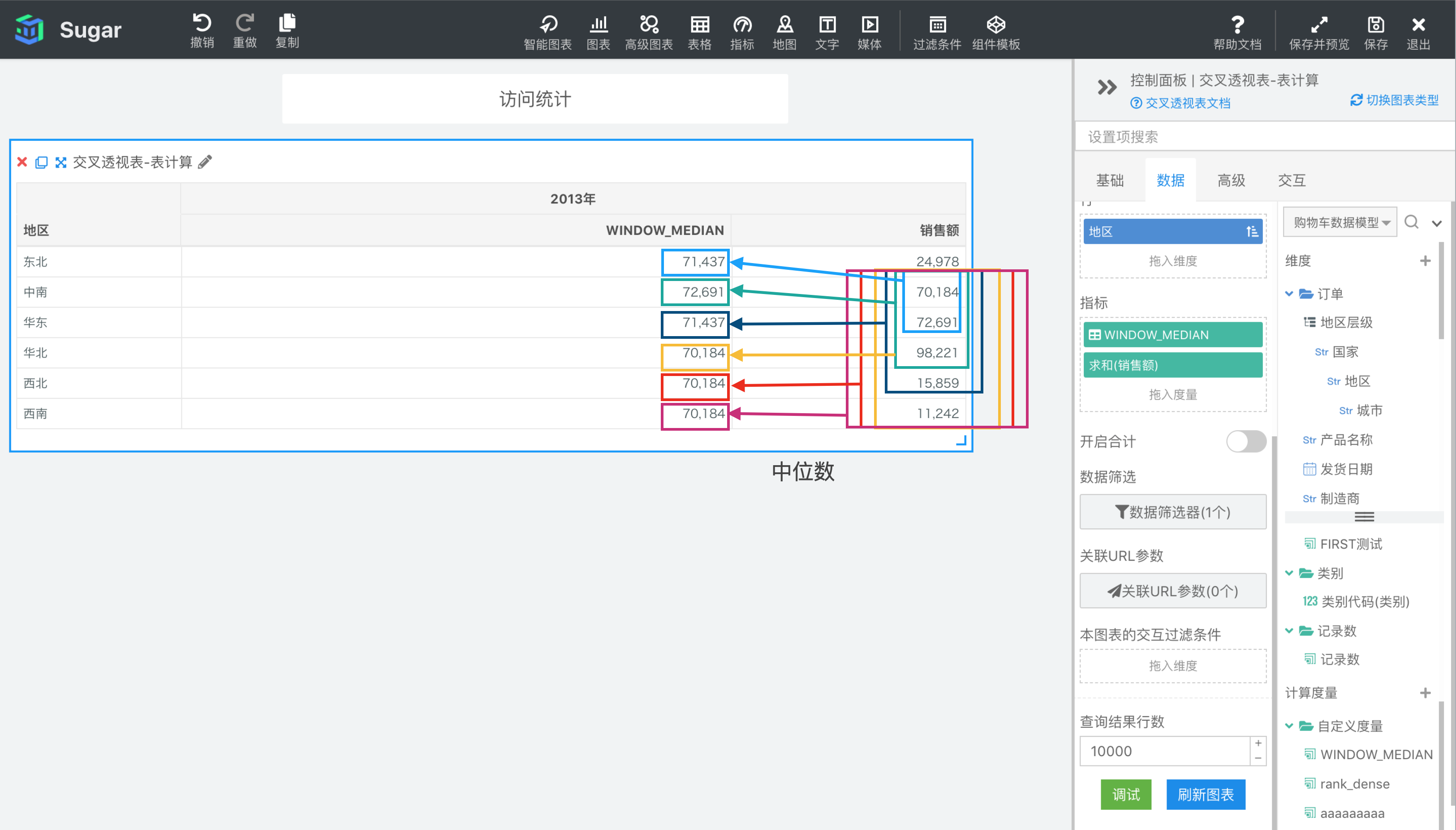
WINDOW_MEDIAN(expression, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expression 升序排列后的中位数。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_MEDIAN(SUM({销售额}), FIRST() + 1, 2)。start 为 FIRST() + 1 表示分区内第 2 项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,中南、华东 2013 年销售额的中位数。2013 年中南地区对应的就是分区内第 2 项中南——当前项后两项华北之间的中位数,以此类推,结果如下图所示。
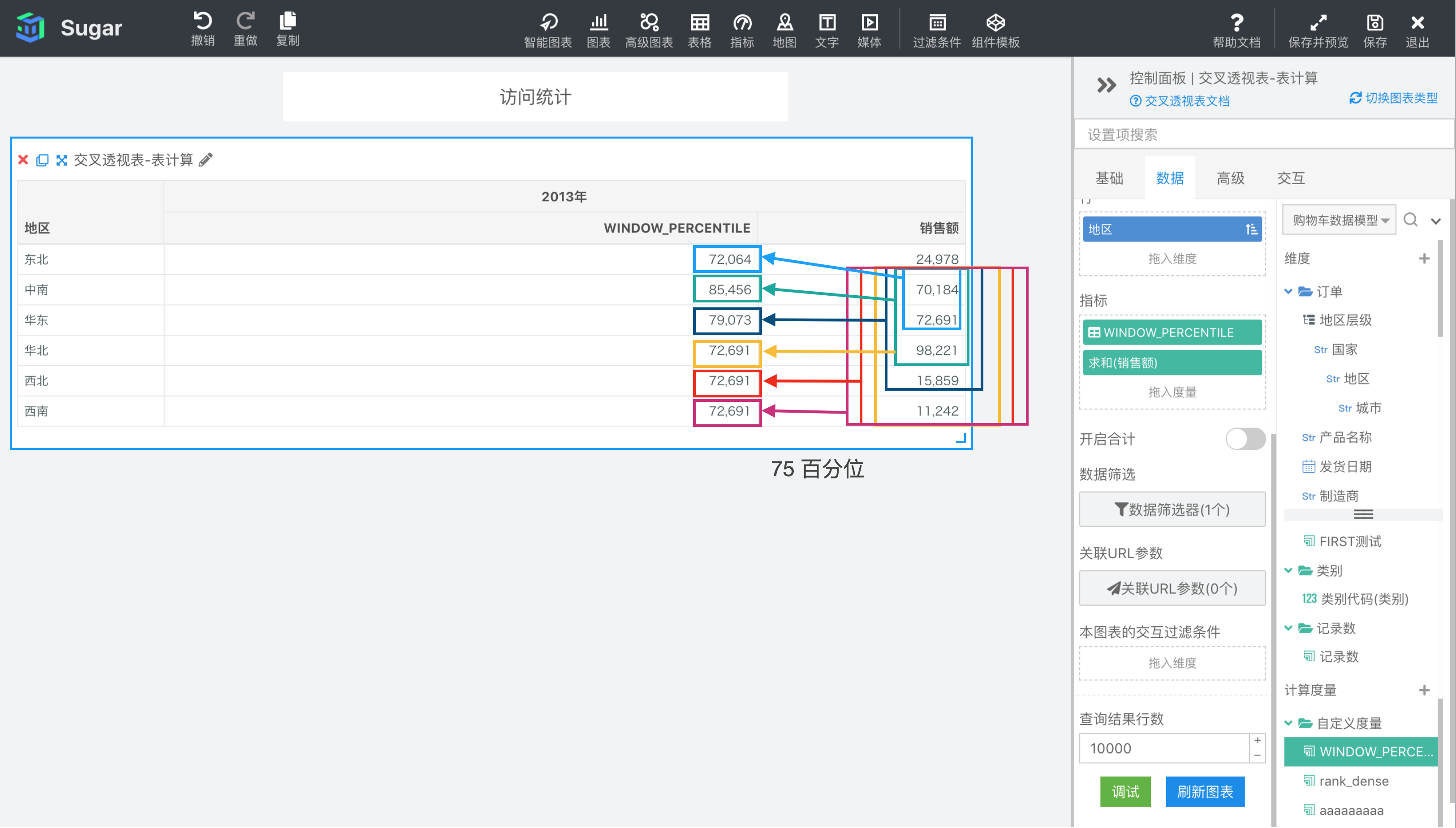
WINDOW_PERCENTILE(expression, number, [start, end])
根据表达式 expression 返回分区中从 start 到 end 所形成的窗口中数据升序排列后的第 number 个百分位对应的值。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 number是百分位数,请输入 0-100 之间的数字。start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_PERCENTILE(SUM({销售额}), 75, FIRST() + 1, 2)。number 为 75,说明这里计算 75 百分位。start 为 FIRST() + 1 表示分区内第 2 项,end 为 2 表示当前项后面两项,则 2013 年东北地区对应的窗口是图中蓝框部分,中南、华东 2013 年销售额的中位数。2013 年中南地区对应的就是分区内第 2 项中南——当前项后两项华北之间的 75 百分位,以此类推,结果如下图所示。
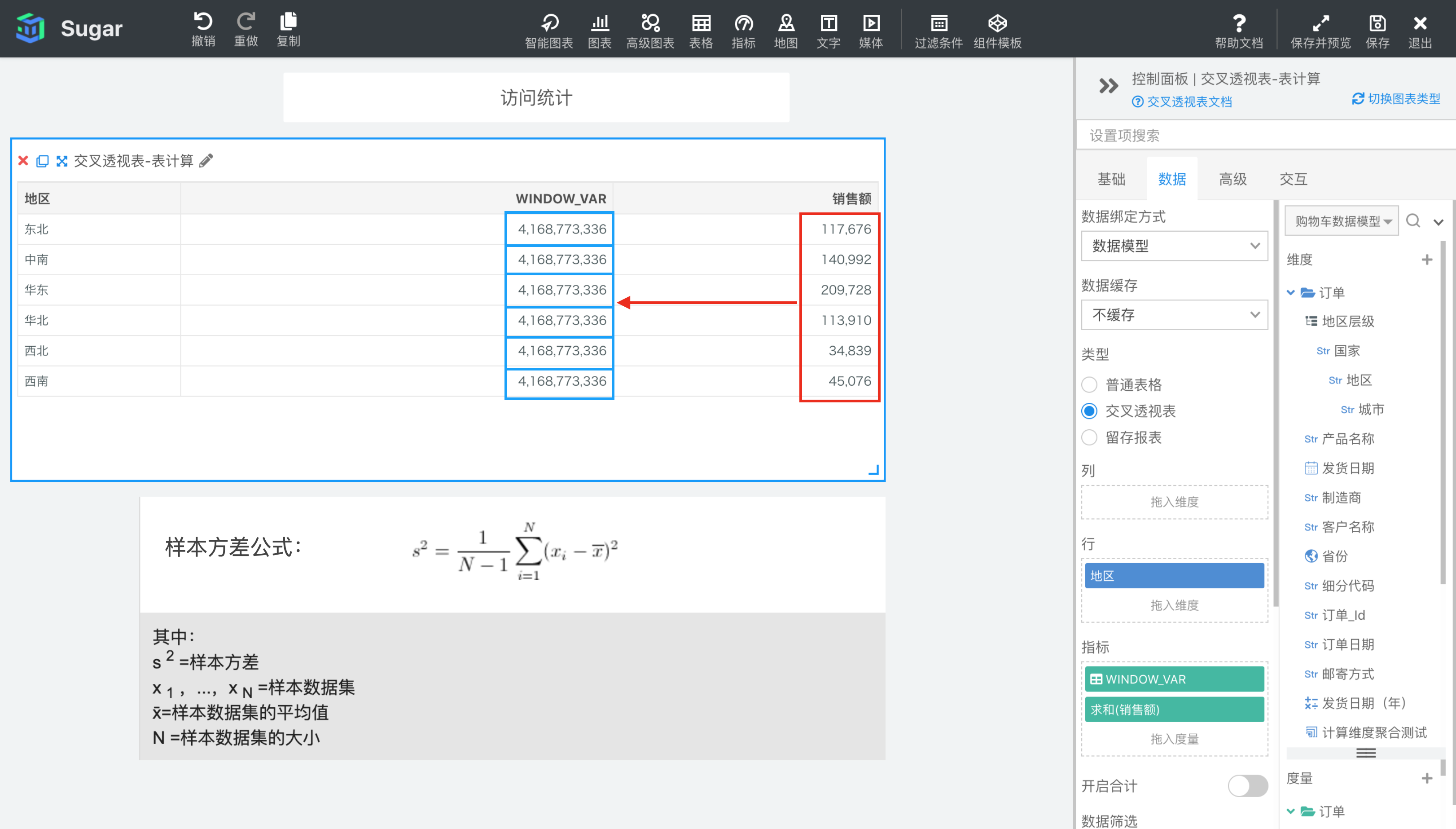
WINDOW_VAR(expression, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的样本方差。样本方差公式见下图。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_VAR(SUM({销售额}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),方便我们观察和验证。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的样本方差。
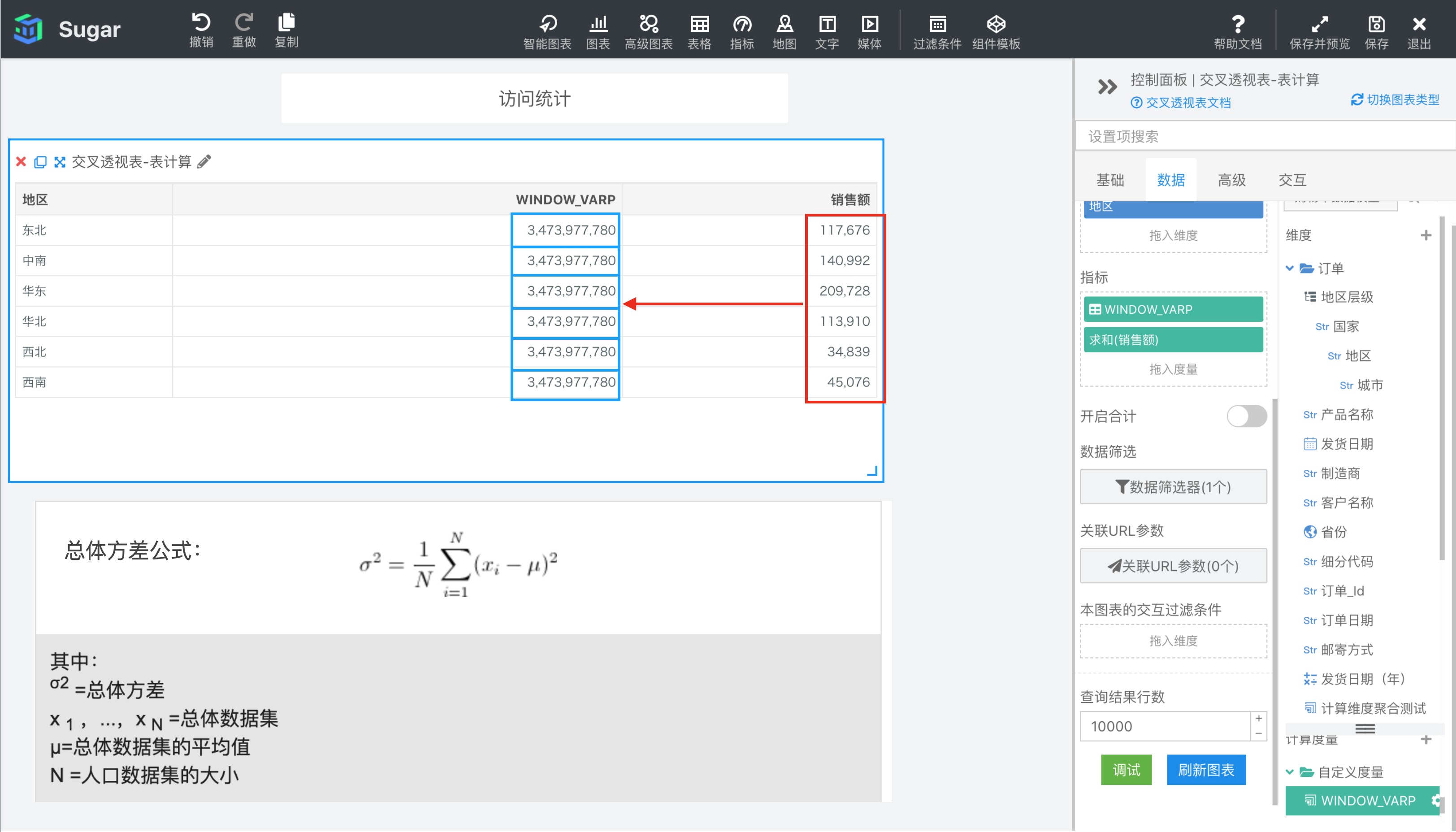
WINDOW_VARP(expression, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的总体方差。总体方差和样本方差的区别是,总体方差除的是 n,样本方差为了无偏估计除的是 n-1。总体方差公式见下图。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_VARP(SUM({销售额}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),方便我们观察和验证。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的总体方差。
WINDOW_STDEV(expression, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的样本标准差。样本标准差等于样本方差开 2 次方。样本标准差公式见下图。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_STDEV(SUM({销售额}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),方便我们观察和验证。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的样本方差。
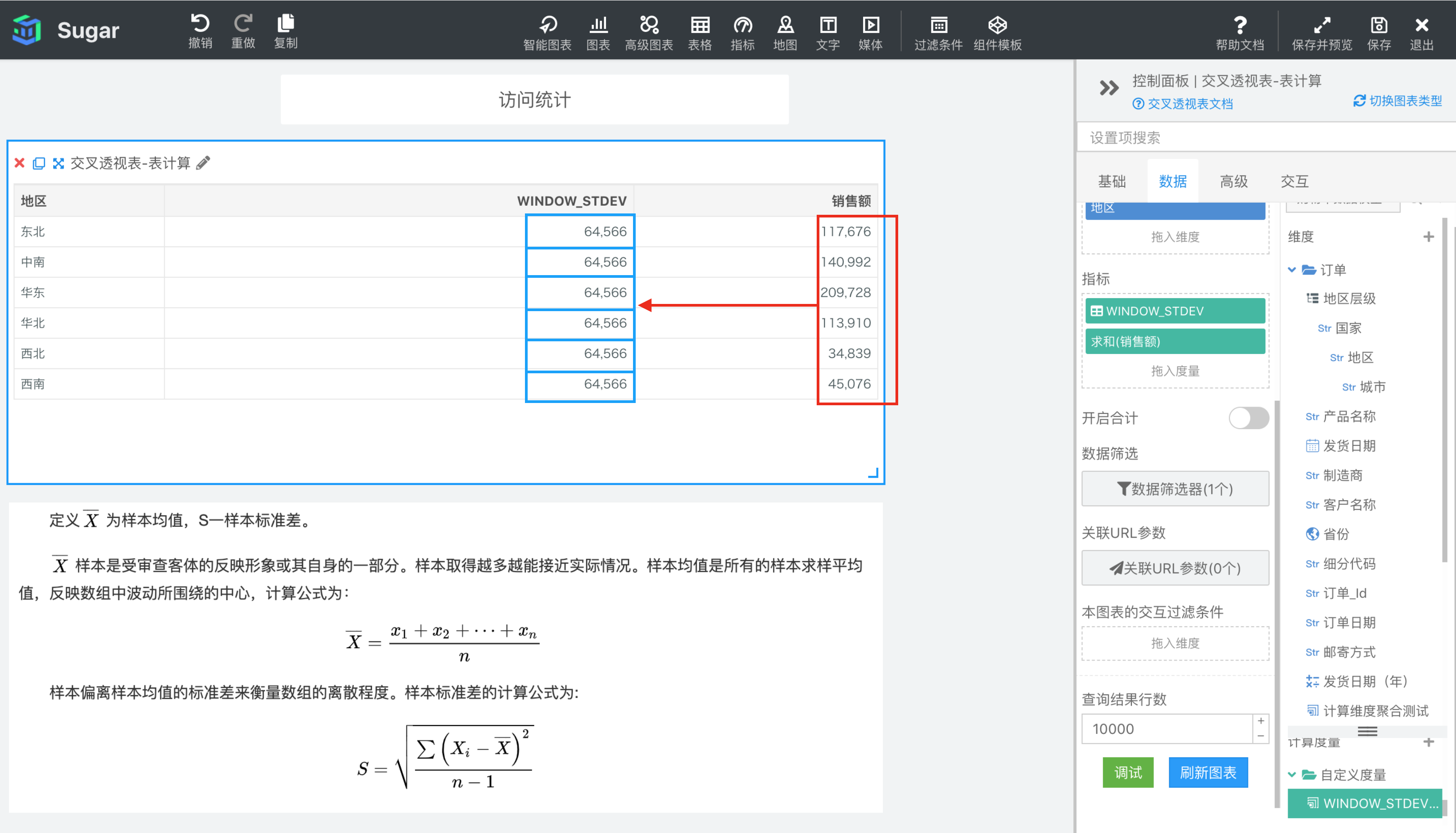
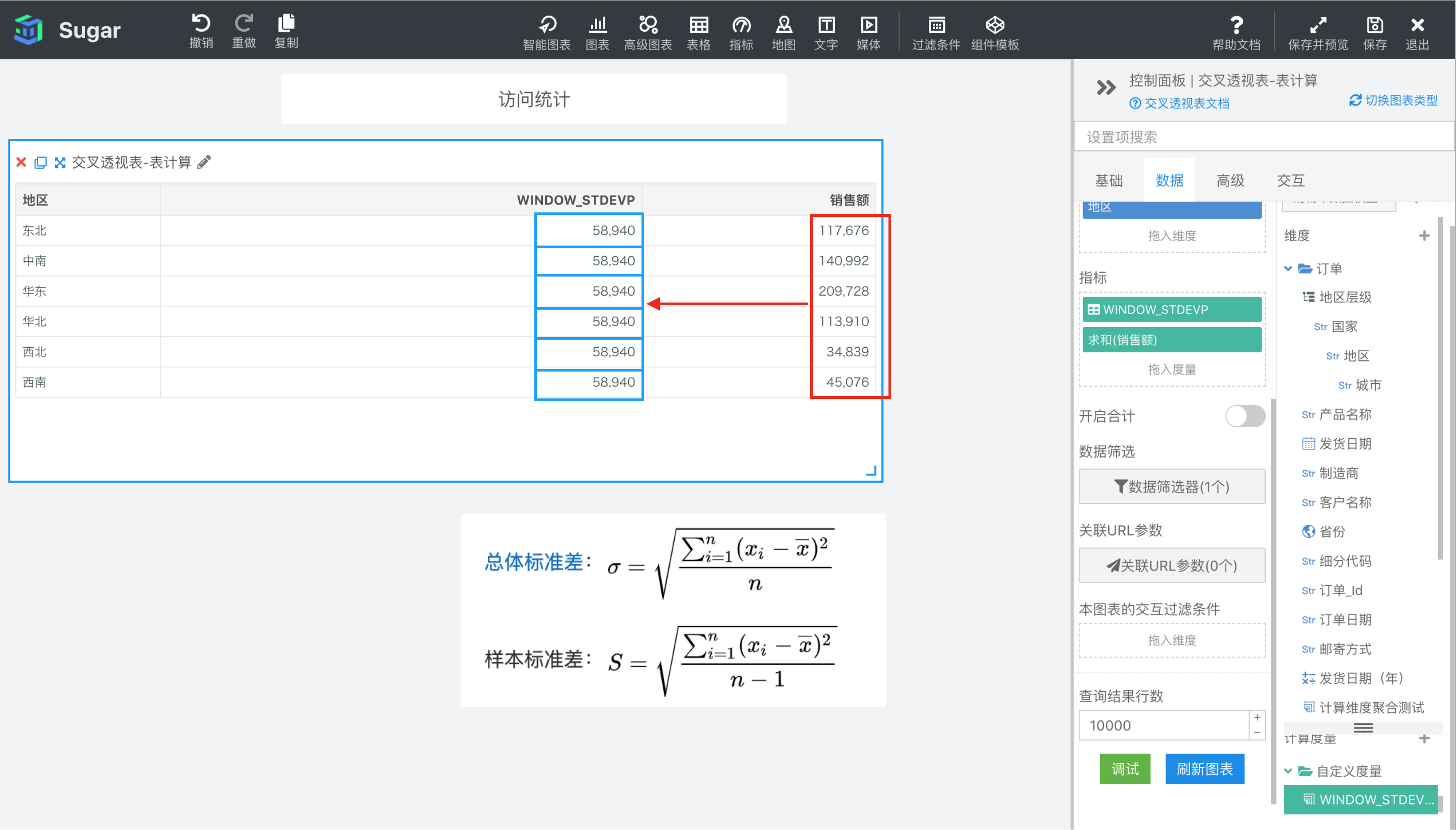
WINDOW_STDEVP(expression, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expression 的总体标准差。总体标准差等于总体方差开 2 次方。总体标准差和样本标准差的区别是,总体标准差除的是 n,样本标准差为了无偏估计除的是 n-1。总体标准差公式见下图。
参数说明:expression 为表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_STDEV(SUM({销售额}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额}),方便我们观察和验证。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的样本方差。
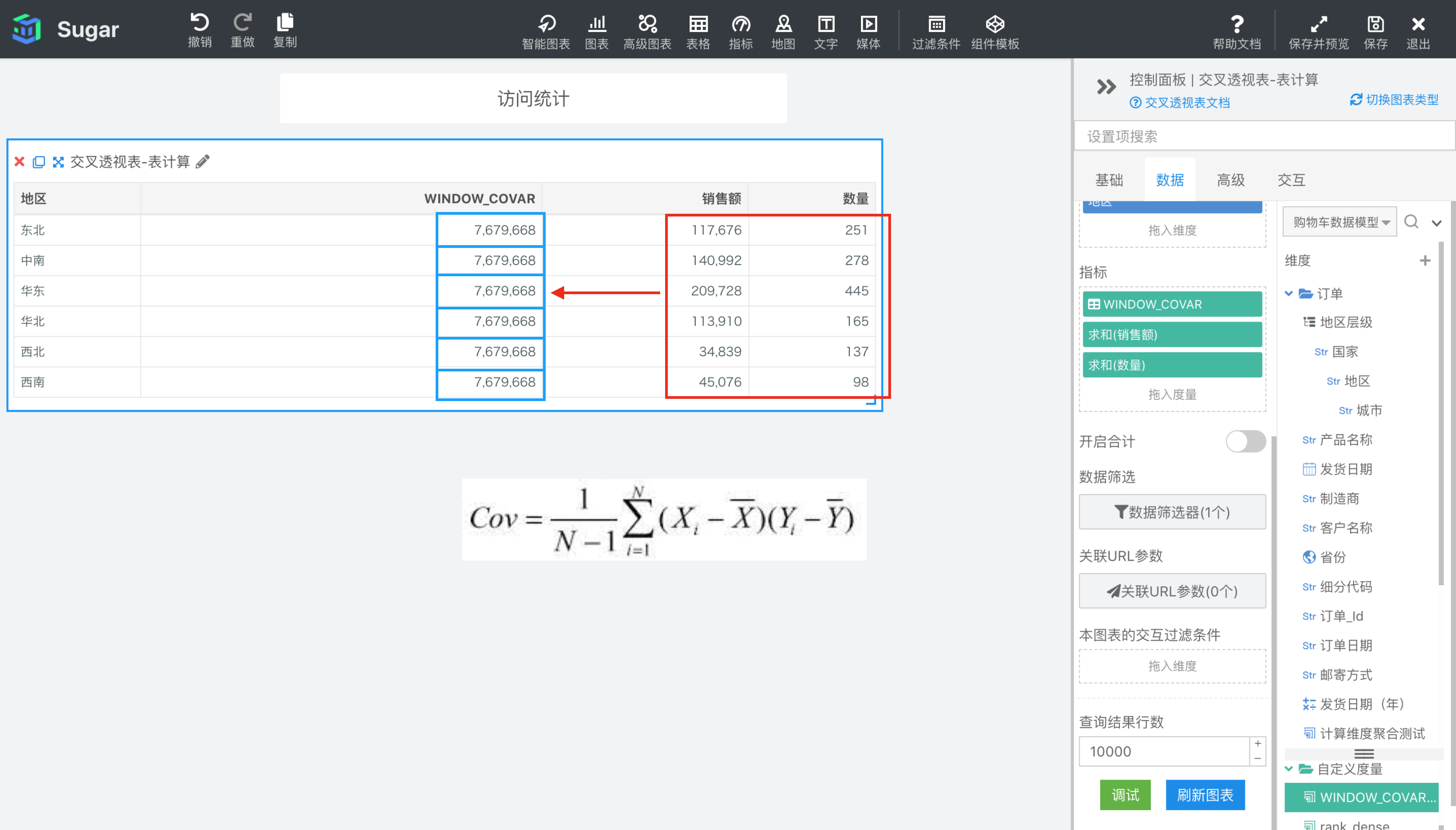
WINDOW_COVAR(expression1, expression2, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expr1 和表达式 expr2 的样本协方差。计算公式见下图。
参数说明:expr1 和 expr2 为参与计算皮尔逊相关系数的两个表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_COVAR(SUM({销售额}), SUM({数量}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额})和一列SUM({数量},方便我们观察。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的样本协方差。
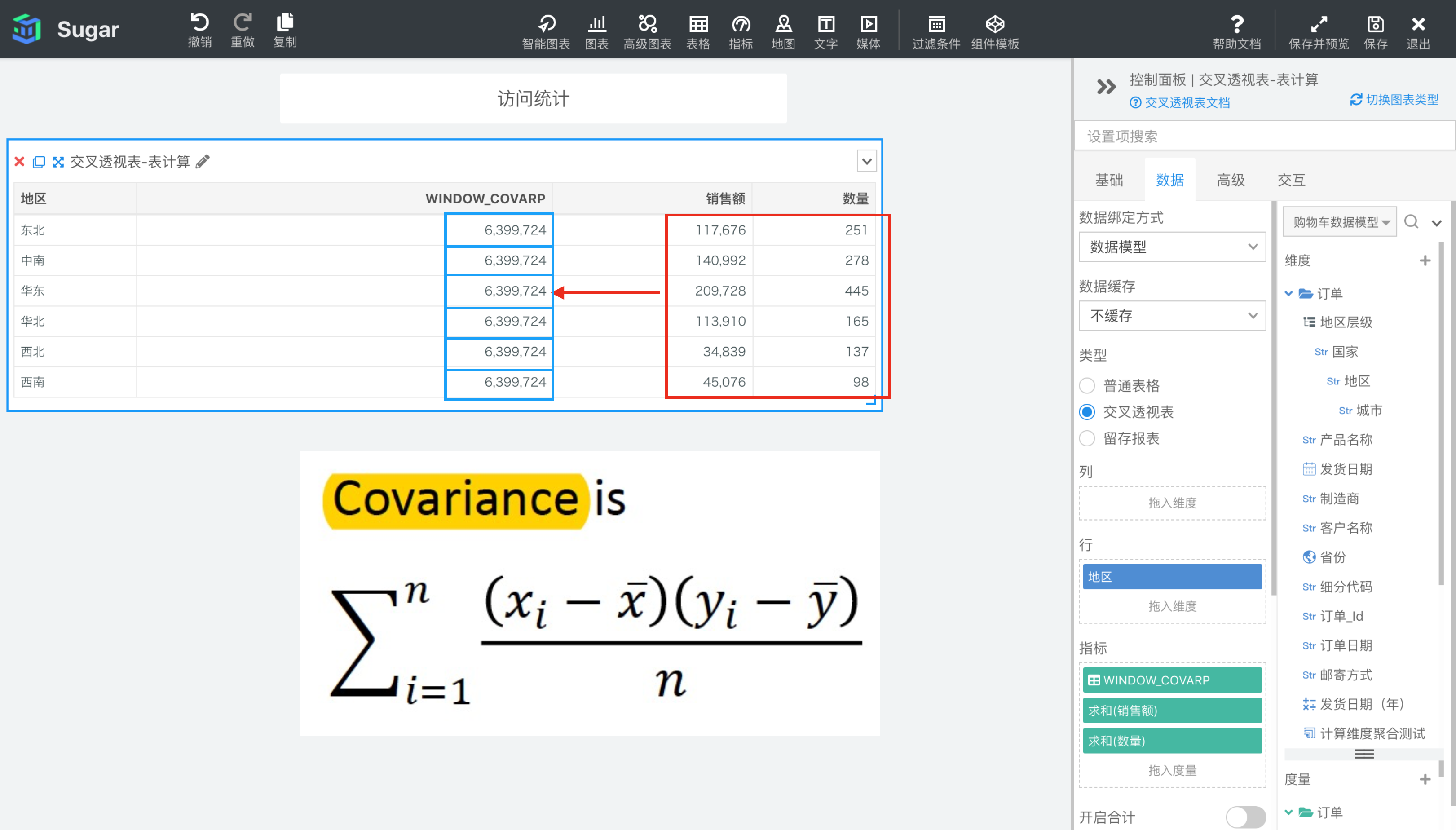
WINDOW_COVARP(expression1, expression2, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expr1 和表达式 expr2 的总体协方差。总体协方差和样本协方差的区别是,总体协方差除的是 n,样本协方差为了无偏估计除的是 n-1。计算公式见下图。
参数说明:expr1 和 expr2 为参与计算皮尔逊相关系数的两个表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_COVAR(SUM({销售额}), SUM({数量}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额})和一列SUM({数量},方便我们观察。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的总体协方差。
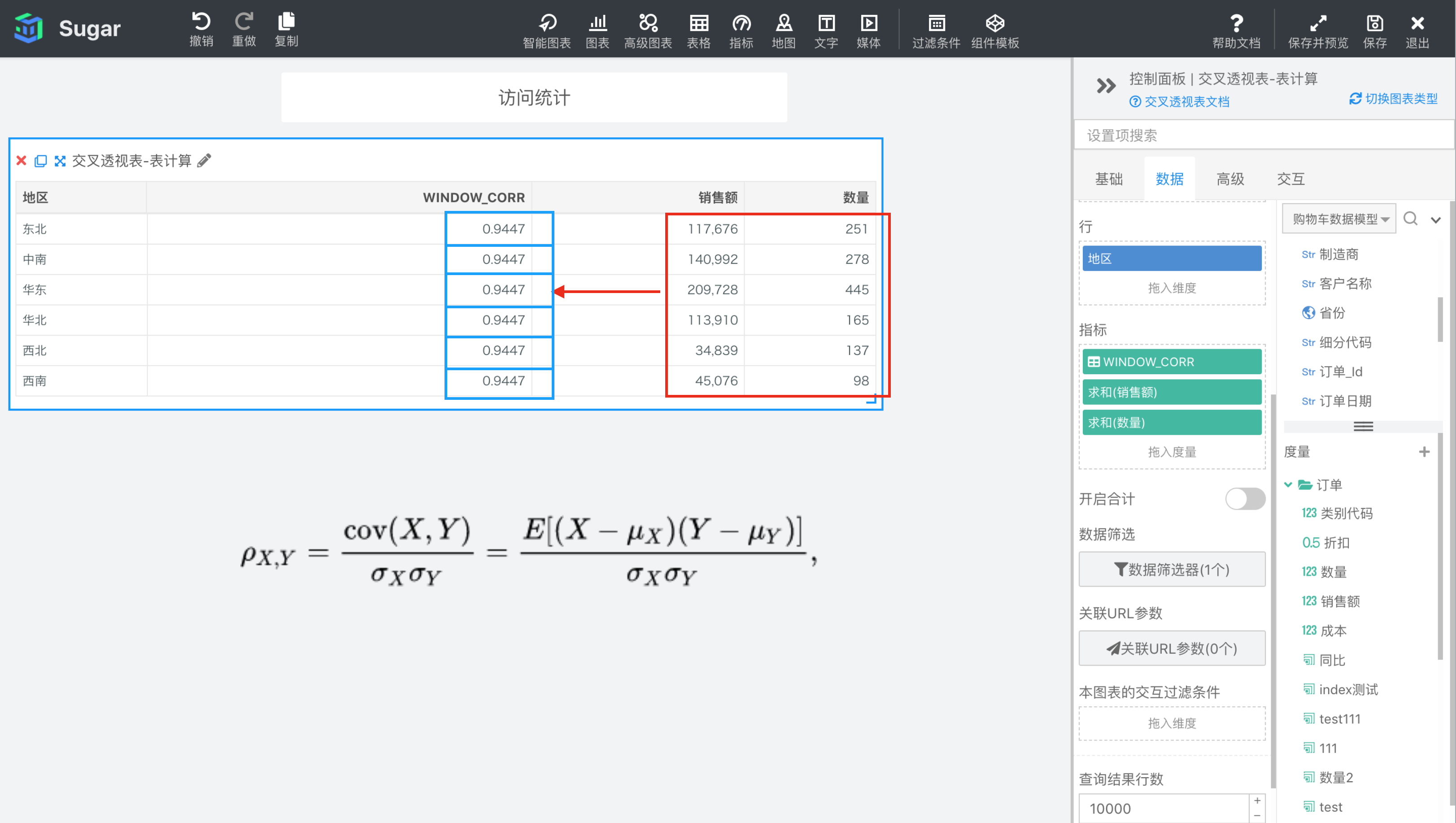
WINDOW_CORR(expr1, expr2, [start, end])
返回分区中从 start 到 end 所形成的窗口中表达式 expr1 和表达式 expr2 的皮尔逊相关系数。皮尔逊相关系数为样本协方差和样本标准差的商,计算公式见下图,
参数说明:expr1 和 expr2 为参与计算皮尔逊相关系数的两个表达式,必须是使用聚合函数的表达式。 start 和 end 是窗口的开始索引和结束索引,可以为数字,表示距当前项的偏移,可以使用 FIRST() + n 和 LAST() + n 表示相对于分区中第一项/最后一项的偏移。start 不填相当于第一项 FIRST(), end 不填相当于最后一项 LAST(),均不填即为整个分区。
示例: 计算依据为表向下,表计算表达式为WINDOW_CORR(SUM({销售额}), SUM({数量}))。start 和 end 缺省表示 FIRST()和 LAST(),即整个分区。结果如下图所示,我们再向指标中拖入一列 SUM({销售额})和一列SUM({数量},方便我们观察。由于窗口是整个分区,所以表计算表达式的值就是红框部分所有值的皮尔逊相关系数。