
Spark自定义JAR作业
更新时间:2025-08-21
背景
BSC 产品支持用户提交SPARK自定义jar作业,以读KAFKA写BOS为例,其具体步骤如下:
步骤
1. 开发作业
开发环境
使用IDEA进行开发,项目管理使用maven,相关版本为
| 名称 | 版本 |
|---|---|
| java | 1.8 |
| scala | 2.11 |
| spark | 2.4.6 |
项目结构
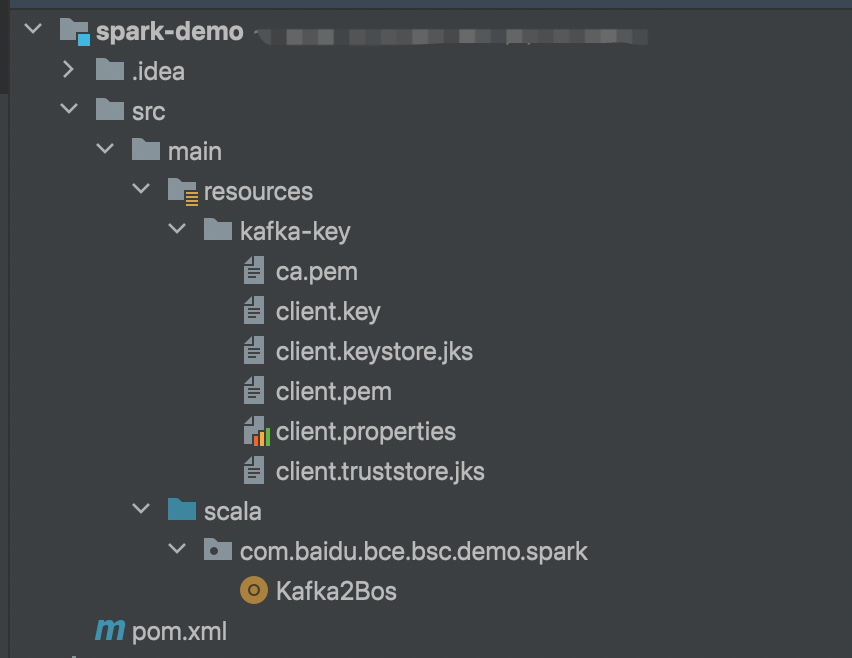
整体项目结构如下图所示。由于示例中KAFKA使用SSL协议,根据代码逻辑将KAFKA提供的SSL证书以及对应kafka配置文件都放在resource下一起打包到jar中。
pom文件
pom文件如下所示,相关的注意事项见文件注释
XML
1<?xml version="1.0" encoding="UTF-8"?>
2<project xmlns="http://maven.apache.org/POM/4.0.0"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
4 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
5 <modelVersion>4.0.0</modelVersion>
6
7 <groupId>org.example</groupId>
8 <artifactId>spark-demo</artifactId>
9 <version>1.0-SNAPSHOT</version>
10
11 <!-- 指定相关依赖的版本号 -->
12 <properties>
13 <scala.binary.version>2.11</scala.binary.version>
14 <spark.version>2.4.6</spark.version>
15 <maven.compiler.source>8</maven.compiler.source>
16 <maven.compiler.target>8</maven.compiler.target>
17 <scope.setting>provided</scope.setting>
18 </properties>
19
20 <dependencies>
21 <!-- 1、 bsc运行环境中包含 spark 核心依赖,所以下面涉及到的 spark 核心依赖无需打到项目jar中,
22 在打包的时候需要指定scope为provided
23 -->
24 <!-- spark 核心依赖:spark-sql -->
25 <dependency>
26 <groupId>org.apache.spark</groupId>
27 <artifactId>spark-sql_${scala.binary.version}</artifactId>
28 <version>${spark.version}</version>
29 <scope>${scope.setting}</scope>
30 </dependency>
31 <!-- spark 核心依赖:spark-streaming -->
32 <dependency>
33 <groupId>org.apache.spark</groupId>
34 <artifactId>spark-streaming_${scala.binary.version}</artifactId>
35 <version>${spark.version}</version>
36 <scope>${scope.setting}</scope>
37 </dependency>
38
39
40 <!-- 2、 bsc运行环境中不包含 spark connector依赖,所以下面涉及到的 spark connector 依赖需要打到项目jar中。
41 注意:
42 - bos相关的依赖无须额外引用,
43 - kafka必须使用0.10版本的connector和client
44 -->
45 <!-- spark对接kafka streaming相关依赖,需要打到jar中 -->
46 <dependency>
47 <groupId>org.apache.spark</groupId>
48 <artifactId>spark-streaming-kafka-0-10_${scala.binary.version}</artifactId>
49 <version>${spark.version}</version>
50 </dependency>
51 <!-- spark对接kafka sql相关依赖,需要打到jar中 -->
52 <dependency>
53 <groupId>org.apache.spark</groupId>
54 <artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
55 <version>${spark.version}</version>
56 </dependency>
57
58
59 <!-- 3、 下面可以引用 spark 之外的一些依赖 -->
60
61 </dependencies>
62
63 <build>
64 <plugins>
65 <plugin>
66 <!-- scala编译插件 -->
67 <groupId>org.scala-tools</groupId>
68 <artifactId>maven-scala-plugin</artifactId>
69 <version>2.15.2</version>
70 <executions>
71 <execution>
72 <id>scala-compile-first</id>
73 <goals>
74 <goal>compile</goal>
75 </goals>
76 <configuration>
77 <includes>
78 <include>**/*.scala</include>
79 </includes>
80 </configuration>
81 </execution>
82 <execution>
83 <id>scala-test-compile</id>
84 <goals>
85 <goal>testCompile</goal>
86 </goals>
87 </execution>
88 </executions>
89 </plugin>
90
91 <!-- 按照上述的逻辑,必须打fat-jar才能把所有依赖提交到bsc中,因此需要使用此打包插件 -->
92 <plugin>
93 <artifactId>maven-assembly-plugin</artifactId>
94 <version>3.0.0</version>
95 <configuration>
96 <archive>
97 <manifest>
98 <mainClass></mainClass>
99 </manifest>
100 </archive>
101 <descriptorRefs>
102 <descriptorRef>jar-with-dependencies</descriptorRef>
103 </descriptorRefs>
104 </configuration>
105 <executions>
106 <execution>
107 <id>make-assembly</id>
108 <phase>package</phase>
109 <goals>
110 <goal>single</goal>
111 </goals>
112 </execution>
113 </executions>
114 </plugin>
115 </plugins>
116 </build>
117
118</project>demo代码
读kafka写bos的代码如下:
Scala
1package com.baidu.bce.bsc.demo.spark
2
3import org.apache.spark.sql.functions.from_json
4import org.apache.spark.sql.types._
5import org.apache.spark.sql.{DataFrame, SparkSession}
6
7import java.io.{File, FileOutputStream, InputStream}
8import java.util.{Base64, Properties}
9
10/**
11 * 使用SPARK DataStream接口完成读kafka,写bos的jar作业示例demo
12 * 示例中:
13 * - 读kafka使用SSL协议,用户需自行指定kafka的kafka client参数,并利用demo提供的文件解析能力,读取证书和配置
14 * - 从kafka读取的数据为json格式,需要用户自行指定schema
15 * - 写bos需要用户提供永久AK/SK,并指定bosEndpoint和bosSinkPath
16 */
17object Kafka2Bos {
18
19 def className = {
20 this.getClass.getName.stripSuffix("$")
21 }
22
23 // 启动日志记录器
24 def logger = {
25 org.slf4j.LoggerFactory.getLogger(className)
26 }
27
28 // 为抽取jar中的文件设置常量
29 val keyStoreName = "client.keystore.jks"
30 val trustStoreName = "client.truststore.jks"
31 val keyDir = "/kafka-key/"
32
33 def main(args: Array[String]) {
34
35 // 1. 获取参数
36 /**
37 * args(0) 为BSC为用户指定的checkpoint目录,无法更改。
38 * 如果用户想要使用SPARK的checkpoint功能,只能使用提供的args(0)作为checkpoint目录。
39 */
40 val checkpointLocation = args(0)
41 /**
42 * args(1) 为用户提供的作业运行参数,以base64编码存储,解码后需要解析成Map再使用
43 * 参数格式:
44 * key1=value1
45 * key2=value2
46 * 本代码中示例:
47 * bootStrapServer=kafka.bj.baidubce.com:9092
48 * topic=test
49 * bosEndpoint=https://bj.bcebos.com
50 * ...
51 */
52 var variables: Map[String, String] = Map()
53 try {
54 // 解析参数
55 val kvStr = new String(Base64.getDecoder().decode(args(1)))
56 kvStr.split("\n").foreach { kv =>
57 val variable = kv.split("=")
58 variables += (variable(0) -> variable(1))
59 }
60 } catch {
61 case e: Exception =>
62 logger.error("decode job variables failed", e)
63 throw e
64 }
65 /** 为配置参数赋值 */
66 val sourceBootstrapServer = variables("bootStrapServer")
67 val sourceTopic = variables("topic")
68 val sinkBosEndpoint = variables("bosEndpoint")
69 val userAK = variables("bosUserAK")
70 val userSK = variables("bosUserSK")
71 val bosSink = variables("bosSink")
72
73 // 2. 从资源文件获取kafka的SSL协议client配置
74 val sslProp: Properties = new Properties()
75 var in: InputStream = null
76 try {
77 in = this.getClass.getResourceAsStream("/kafka-key/client.properties")
78 sslProp.load(in)
79 } finally {
80 if (in != null) {
81 in.close
82 }
83 }
84 /** 打印client配置内容 */
85 sslProp.list(System.out)
86
87 // 3. 从jar中抽取 client.keystore.jks & client.truststore.jks
88 val currentDir = System.getProperty("user.dir")
89 val keyStoreDist = currentDir + File.separator + keyStoreName
90 val trustStoreDist = currentDir + File.separator + trustStoreName
91 extractFileFromJar(keyStoreDist, keyDir + keyStoreName)
92 extractFileFromJar(trustStoreDist, keyDir + trustStoreName)
93
94 // 4. create SparkSession 以及一些基本配置
95 val spark = SparkSession.builder
96 .appName("KafkaToBosJob")
97 .config("spark.sql.shuffle.partitions", "5")
98 .getOrCreate()
99 /** add cert file */
100 spark.sparkContext.addFile(keyStoreDist)
101 spark.sparkContext.addFile(trustStoreDist)
102
103 import spark.implicits._
104
105 // 5. 创建 kafka source
106 val source = createKafkaSource(spark, sourceBootstrapServer, sourceTopic, sslProp)
107
108 // 6. spark operation pipeline
109 /**
110 * 操作value中的数据字段
111 * 原始value数据格式由用户上游kafka自定义,只需要能在以下逻辑中可以正确提取数据即可。
112 * 以json格式为例
113 * {
114 * "stringtype": "lRAhSQgShKn77uD",
115 * "longtype": 1199158871,
116 * "floattype": 0.038981155578358462,
117 * "binarytype": "null",
118 * "integertype": 1,
119 * "bytetype": -58,
120 * "booleantype": true,
121 * "doubletype": 439147658,
122 * "shorttype": 13538
123 * }
124 */
125 /** 对于json格式,我们使用schema来定义结构 */
126 val schema = new StructType().add("stringtype", StringType).add("longtype", LongType)
127 .add("floattype", FloatType).add("binarytype", BinaryType)
128 .add("integertype", IntegerType).add("bytetype", ByteType)
129 .add("booleantype", BooleanType).add("doubletype", DoubleType)
130 .add("shorttype", ShortType)
131 /** 将kafka record中的value字段(实际数据)取出来转换成schema,并取出stringtype、longtype、floattype三个字段 */
132 val kafkaStreamDF = source
133 .selectExpr("CAST(value as STRING)")
134 .select(from_json($"value", schema).alias("json_data"))
135 .select($"json_data.stringtype", $"json_data.longtype", $"json_data.floattype")
136
137 // 7. 将操作过后的数据以csv格式写入bos
138 /** 配置baidu bos file system参数 */
139 val hadoopConf = spark.sparkContext.hadoopConfiguration
140 hadoopConf.set("fs.bos.endpoint", s"${sinkBosEndpoint}")
141 hadoopConf.set("fs.bos.access.key", s"${userAK}")
142 hadoopConf.set("fs.bos.secret.access.key", s"${userSK}")
143 hadoopConf.set("fs.bos.impl", "org.apache.hadoop.fs.bos.BaiduBosFileSystem")
144 hadoopConf.setBoolean("iam.sts.enabled", false)
145 hadoopConf.setLong("fs.bos.readahead.size", 5242880)
146 val sink=kafkaStreamDF.writeStream
147 .format("csv") //sink的类型,必填
148 .outputMode("append") //输出模式
149 .option("path", s"${bosSink}")
150 .option("truncate", "false")
151 .option("checkpointLocation", s"${checkpointLocation}") //从args(0)指定checkpoint位置
152
153 val query = sink.start()
154 query.awaitTermination()
155 } // end main
156
157
158 /**
159 * 创建kafka source,设置基本配置参数,以及ssl配置
160 * @param spark
161 * @param sourceBootstrapServer
162 * @param topic
163 * @param sslProp
164 * @return
165 */
166 def createKafkaSource(
167 spark: SparkSession,
168 sourceBootstrapServer: String,
169 topic: String,
170 sslProp: Properties): DataFrame = {
171 val source = spark.readStream
172 .format("kafka") //source的类型,必填
173 .option("kafka.bootstrap.servers", s"${sourceBootstrapServer}") //endpoint和端口,必填
174 .option("subscribe", s"${topic}") //topic,必填
175 .option("startingOffsets", "earliest") //读取offset的起始位置,latest/earliest,必填
176
177 // set sslProp to source option
178 var iter = sslProp.stringPropertyNames.iterator()
179 while (iter.hasNext) {
180 val key = iter.next()
181 source.option(s"kafka.$key", sslProp.getProperty(key))
182 }
183 source.load()
184 }
185
186 /**
187 * 从jar中抽取文件到本地
188 * @param dist
189 * @param source
190 */
191 def extractFileFromJar(dist: String, source: String) = {
192 try {
193 val inStream = this.getClass.getResourceAsStream(source)
194
195 val fos = new FileOutputStream(dist);
196 val buffer = new Array[Byte](10240);
197 var size: Int = 0;
198 while (size != -1) {
199 fos.write(buffer, 0, size);
200 size = inStream.read(buffer); //Scala中这个Size的位置很重要
201 }
202 inStream.close();
203 fos.close();
204 } catch {
205 case t: Throwable =>
206 t.printStackTrace
207 throw t
208 }
209 }
210}项目打包
执行 mvn clean package 命令之后,能编译出用于bsc运行的jar包 spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
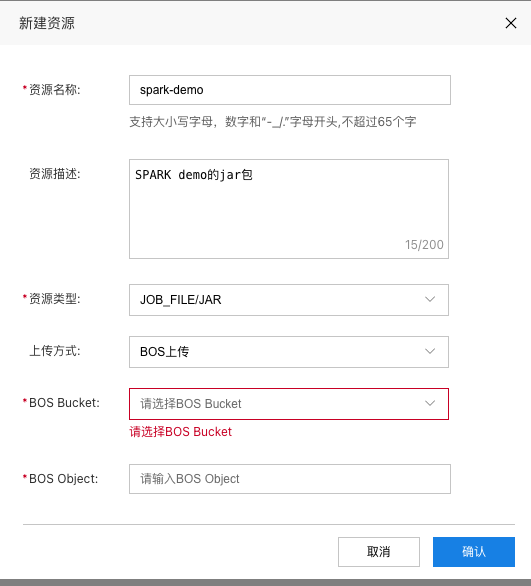
2. 新增资源
进入BSC控制台,选择资源管理,点击新增资源按钮。资源类型需要选择为JOB_FILE/JAR,上传方式与jar包大小相关,可以选择bos上传或者本地上传。
上传完成之后效果如下:

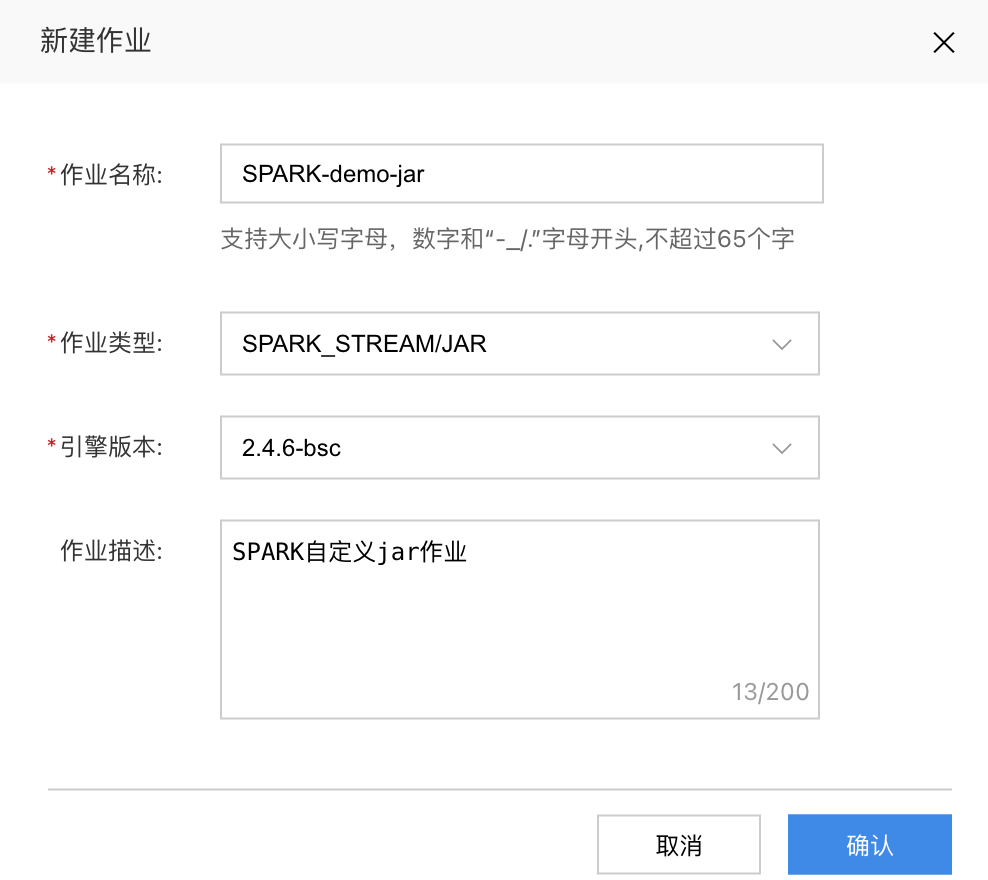
3. 新增作业
打开BSC控制台,点击新建作业按钮,新建一个SPARK_STREAM/JAR作业如下图示例。
编辑作业参数
在作业开发的富文本编辑框中,配置SPARK jar的参数信息如示例:
Bash
1-- 函数完整类名
2main.class=com.baidu.bce.bsc.demo.spark.Kafka2Bos;
3
4-- 完整主类名JAR包的资源名称
5main.jar=spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar;
6
7-- 函数参数设置,必须以“main.args.”开头
8main.args.bootStrapServer=kafka.gz.baidubce.com:9092;
9main.args.topic=topictopictopic;
10main.args.bosEndpoint=http://gz.bcebos.com;
11main.args.bosUserAK=akakakakakakakakakakakakak;
12main.args.bosUserSK=sksksksksksksksksksksksksk;
13main.args.bosSink=bos://bucket/object;引用jar资源
在资源引用栏中选择刚才上传的jar包,点击引用;并将资源详情中的资源原名作为作业参数main.jar的参数
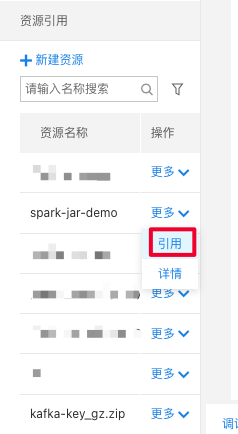
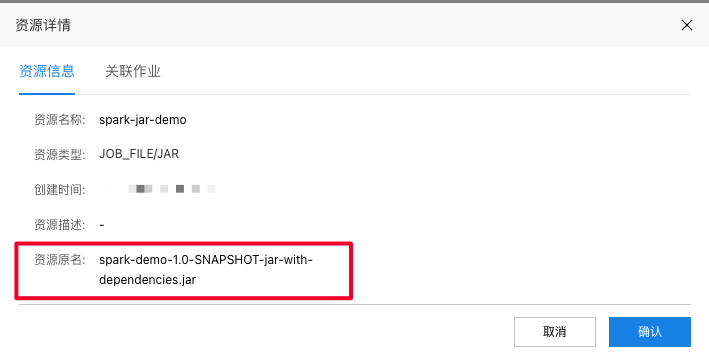
保存发布作业
依次点击保存、发布按钮,将作业发布到作业运维列表。
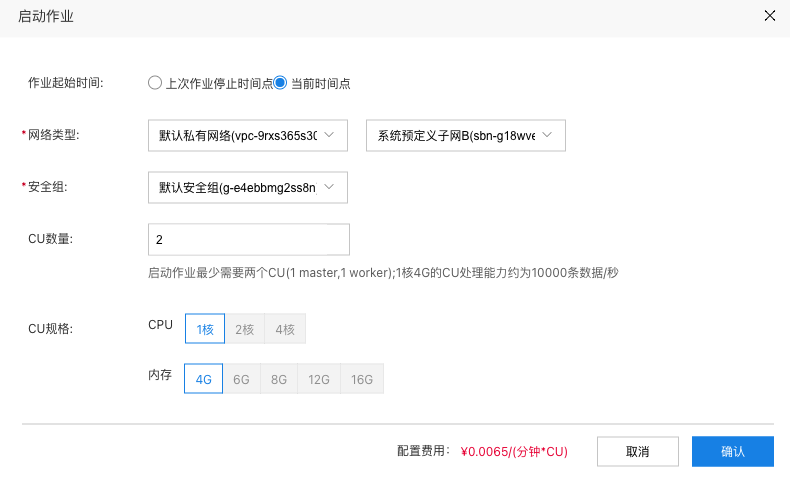
4. 运行作业
切换到作业运维的详情页面,点击启动,选择相应的网络参数并申请启动资源,点击确认。如果使用了检查点,可以选择从上次作业停止时间点启动
启动之后,可以看到作业运行日志,但jar作业不支持实时监控的查看。
5. 更新作业
如果需要更新作业jar包,需要按照如下步骤执行:
- 停止运行中的作业。
- 在资源管理列表对相应的jar包发起"新增版本"操作。
- 在作业开发页面对相应作业的资源引用执行"解绑-引用"操作。
- 在作业开发页面修改作业参数,对作业执行"保存-发布"操作。
- 重启启动作业。
如果仅仅是需要修改作业参数,可以简化步骤为:
- 停止运行中的作业。
- 在作业开发页面修改作业参数,对作业执行"保存-发布"操作。
- 重启启动作业。